这是一系列视频学习,写博客也是方便自己之后复习,有大家需要的资料可以给个参考。
接上一篇:https://blog.csdn.net/aaaaaab_/article/details/80015589
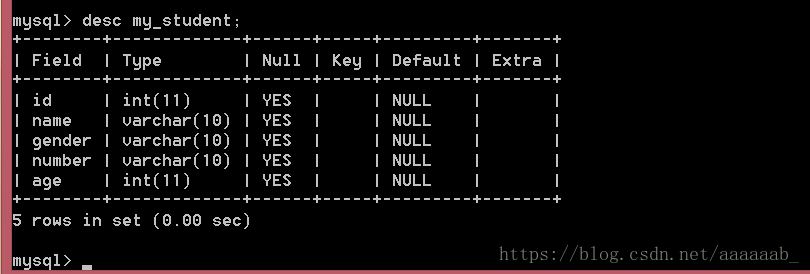
原数据表:
修改字段:
alter table 表名 modify 字段名
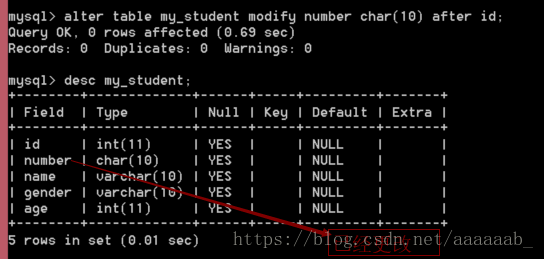
--将学生表中的number学号字段变成固定长度,且放在第二位之后:
alter table my_student modify number char(10) after id;
desc my_student;
重命名字段:
alter table 表名 change 旧字段 新字段名 数据类型 [属性][位置];
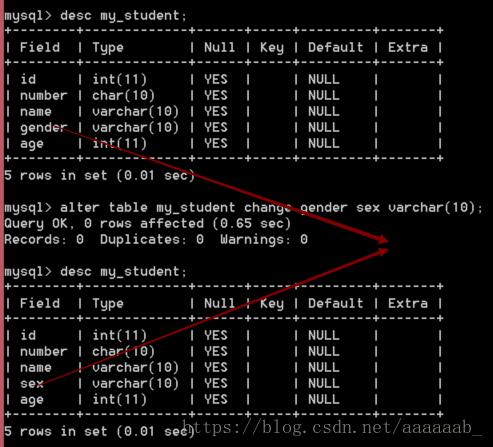
--修改学生表中的gender字段为sex
alter table my_student change gender sex varchar(10);
desc my_student;
删除字段:
alter table 表名 drop 字段名;
--删除学生表中的年龄字段:(age)
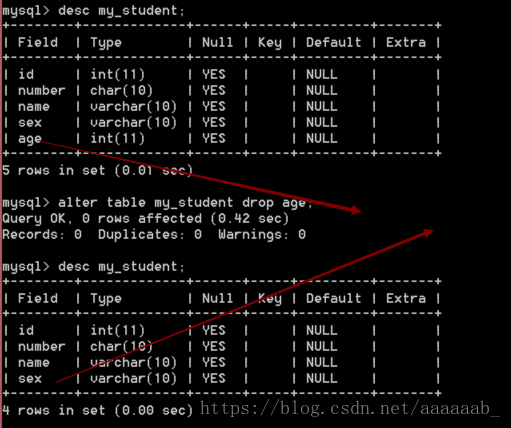
alter table my_student drop age;
desc my_student;
小心:如果表中已经存在数据,那么删除字段会清空该字段的所有数据(不可逆)。
删除数据表:
Drop table 表名1,表名2...;可以一次性删除多个表。
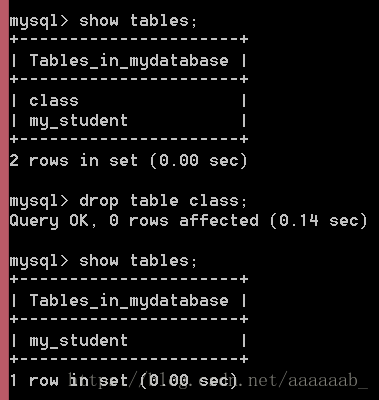
drop table class;
show tables;显示所有表
当删除数据表的指令执行发生了什么?
1.在表空间中,没有了指定的表(数据也没有了)
2.在数据库对应的文件夹下,表对应的文件(与存储引擎有关)也会被删除。
注意:删除有危险,操作需谨慎(不可逆的操作)
数据操作–新增数据:
insert into 表名 values(值列表)[,(值列表)];
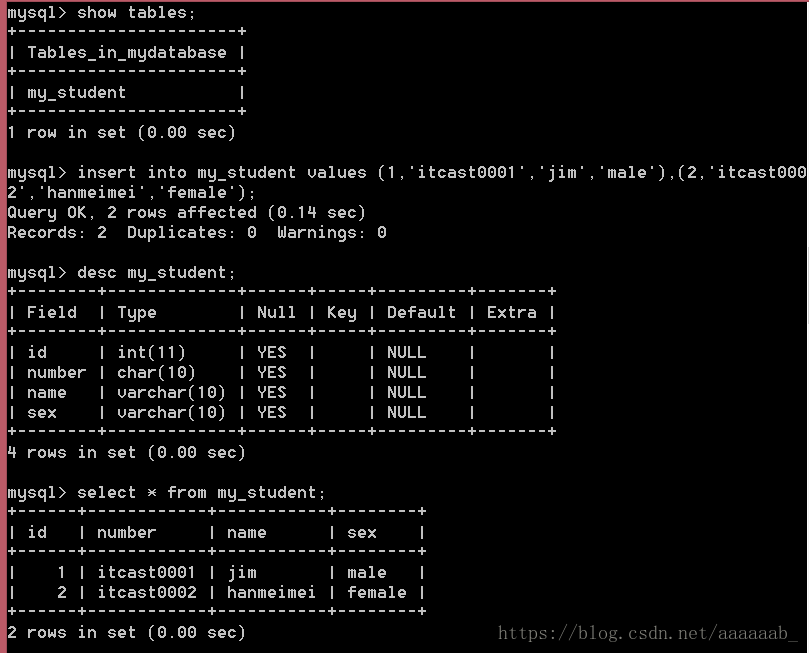
方案一:给全表字段插入数据,不需要指定字段列表,要求数据的值出现的顺序必须与表中设计出现的字段出现的顺序一致;
凡是非数值数据,都需要引号,建议是单引号包裹。(可以一次性插入多条记录)
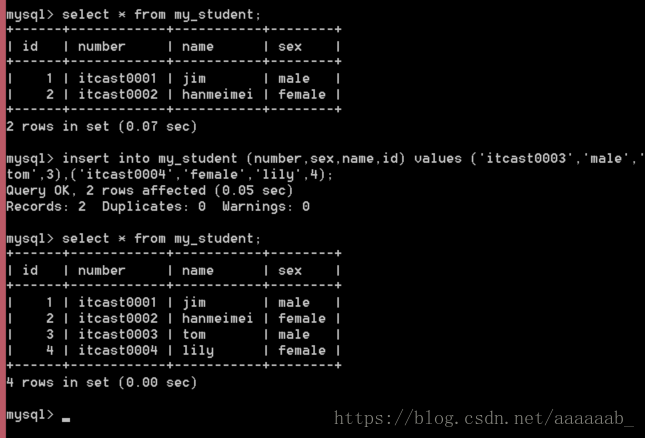
方案2:给部分字段插入数据,需要选定字段列表,字段列表出现的顺序与字段的顺序无关;但是值列表的顺序必须与选定字
段的顺序一致。
insert into 表名 (字段列表) values(值列表) [,(值列表)];
--插入数据,指定字段列表
insert into my_student (number,sex,name,id) values ('itcast0003','male','tom',3),('itcast0004','female','lily','4');
查看数据:
select */字段列表 from 表名 [where 条件];
--查看所有数据
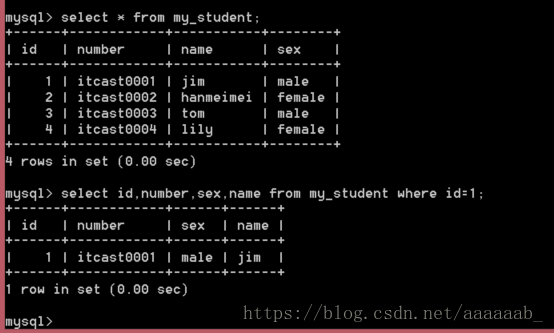
select * from my_student;
--查看指定字段,指定条件数据:
select id,number,sex,name from my_student where id=1;
更新数据:
update 表名 set 字段=值 [where 条件];
--建议都有where;要不然就是更新全部
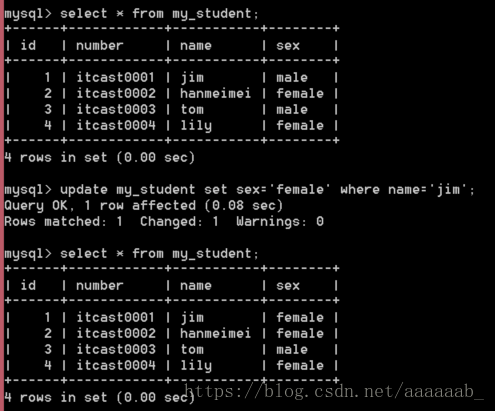
--更新数据:
update my_student set sex='female' where name='jim';
先查看select * from my_student;更新不一定成功,比如没有真正需要更新的数据,需要看有无数据影响。
删除数据:
删除是不可逆的;删除有风险,操作需谨慎。
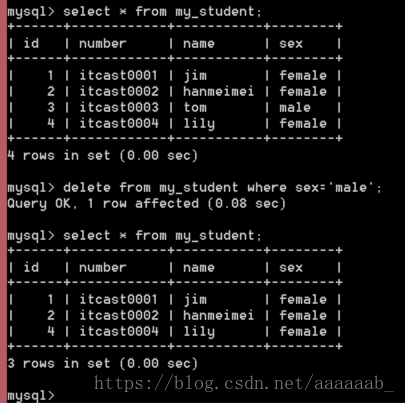
delete from 表名 [where 条件];
delete from my_student where sex='male';
select * from my_student;
中文数据问题:无法插入数据
中文数据问题本质是字符集问题。计算机只识别二进制:人类更多的是识别符号,需要有个二进制与字符的对应关系(字符集)。
--插入一组数据(中文)
insert into my_student values(5,'itcast0005','张越','男');会报错,客户端向服务器插入中文数据没有成功。

原因:\XD5\XC5\XD4\XBD代表的是‘张越’在当前编码(字符集)下对应的二进制编码转换成的十六进制。两个汉字=>四个字节(GBK)
报错:服务器没有识别对应的四个字节,服务器认为数据是UTF8,一个汉字有三个字节,读取三个字节转换成汉字(失败),剩余的
再读三个字节不够,最终会失败。
所有的数据库服务器认为(表现)的一些特性都是通过服务器端的变量来保存的,系统会先读取自己的变量,看看自己应该怎么表现。
查看字符集:
查看服务器到底识别了哪些字符集。
show character set;查看所有字符集,基本上服务器是万能的,什么字符集都可以处理。
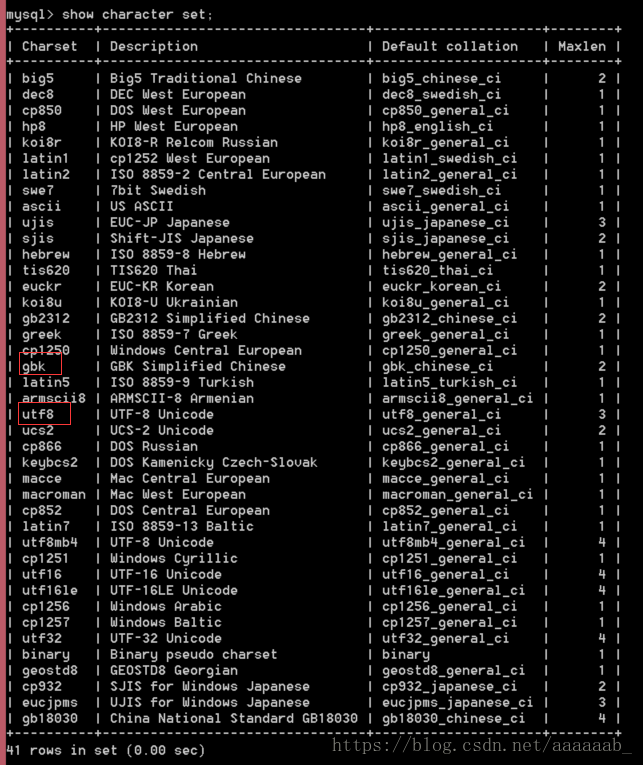
既然服务器识别那么多,总有一种是服务器默认的跟客户打交道的字符集。
show variables like 'character_set%'; 查看当前字符集处理
也即查看服务器默认的对外处理的字符集
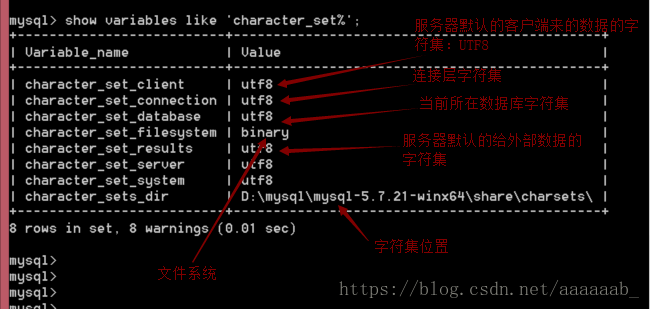
解决中文问题:
问题来源:客户端数据只能是GBK,而服务器认为是UFT8;矛盾产生。
解决方案:修改服务器认为的客户端数据的字符集为GBK
set character_set_client=gbk;
show variables like 'character_set%';
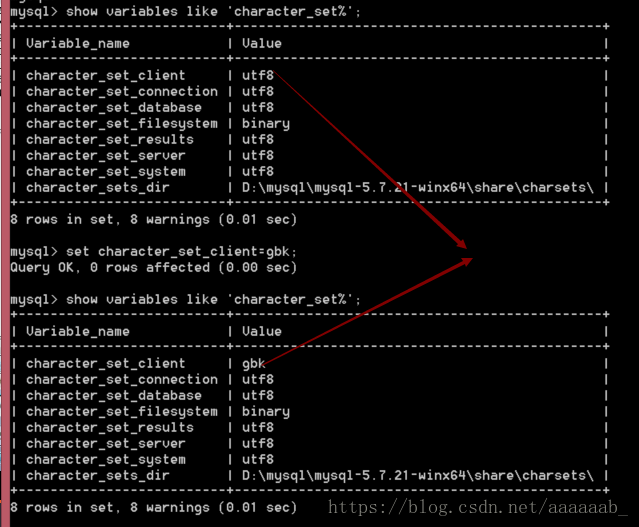
插入中文的效果:解决了不能插入中文的问题
insert into my_student values(5,'itcast0005','张越','男');
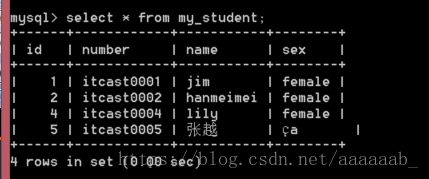
查看数据效果乱码:

select * from my_student;
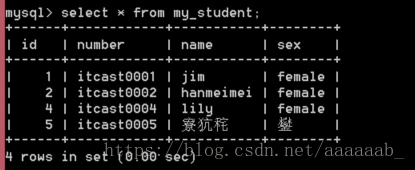
解决数据乱码的问题:
原因:数据来源是服务器,解析数据的是客户端(客户端只识别GBK,只会两个字节一个汉字);但是事实服务器给的数据却是
UTF8,三个字节一个汉字导致乱码。
解决方案:修改服务器给客户端的数据字符集为GBK。
set character_set_results=gbk;
show variables like 'character_set%';
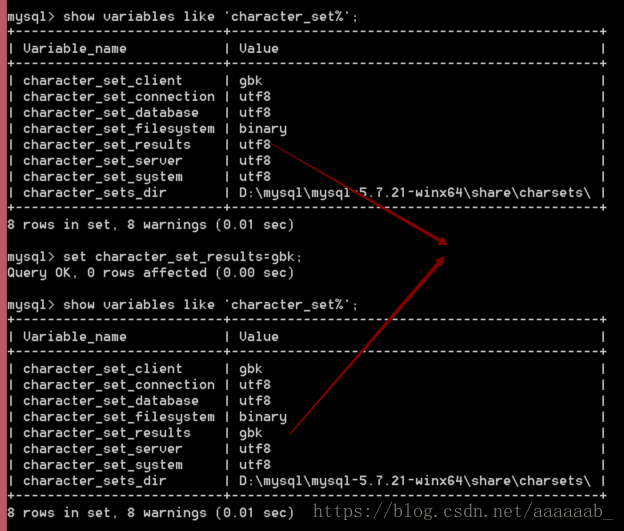
查看数据效果:这一块有个疑问就是第二次做这个实验的时候,没有修复好所有的乱码问题,很疑惑
select * from my_student; 解决问题
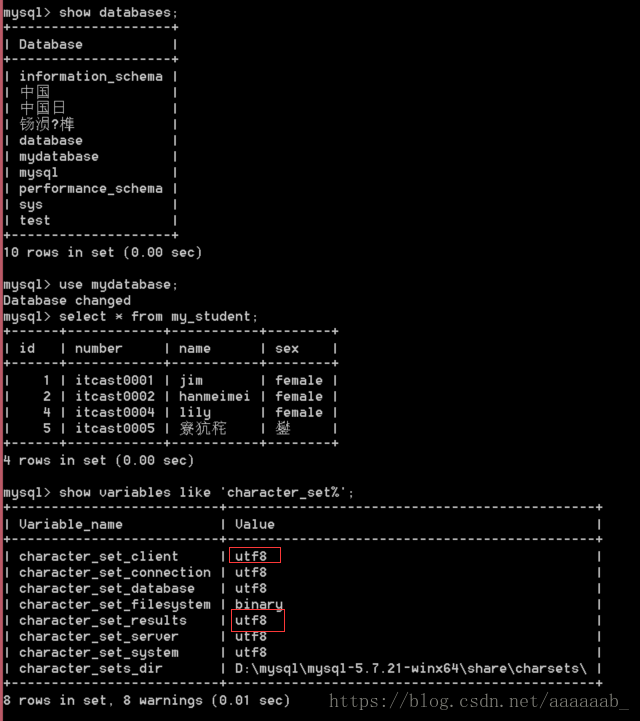
set 变量 = 值的级别:
set 变量 = 值;修改只是会话级别(当前客户端,当次连接有效关闭失效)
再次查看:select * from my_student; 依然乱码
show variables like 'character_set%'; 也都变回去了utf8
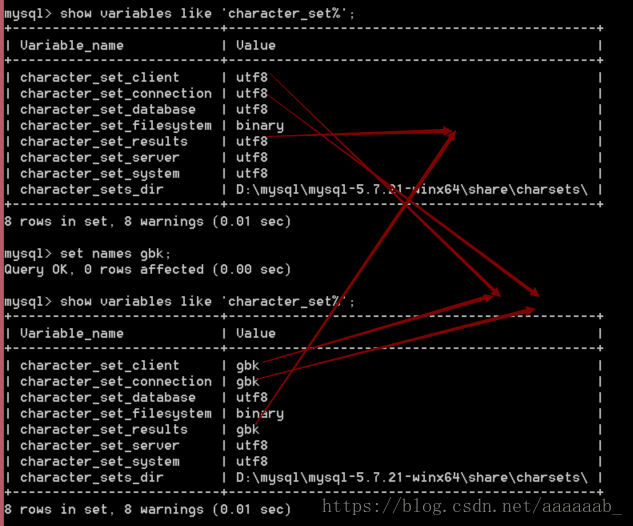
直接设置字符集:
设置服务器对客户端的字符集的认知,可以使用快捷方式:set names 字符集
set names gbk; 相当于直接设置character_set_client,character_set_results,character_set_connection;
快捷设置字符集set names gbk;
connection是一个连接层,是我们字符集转变的中间者,如果统一了效率更高,不统一也没有关系。
关于服务器和客户端的一个误区:
show create table my_student;
alter table my_student charset=utf8;
一个汉字有三个字节,服务器更改什么无所谓,只要保证客户端可以正确读取即可,正如我们银行存钱时,我们并不知道银行
内部是以何种方式存我们的钱,我们只要正确存取即可。这个主要是看客户端的需求,不要超过服务器的界限就都是可以的。
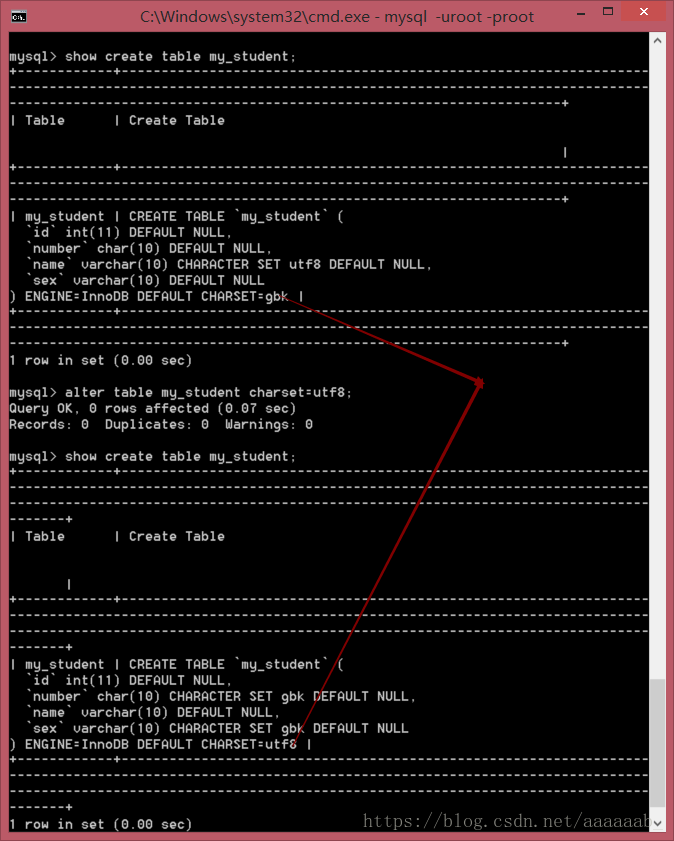
校对集问题:
校对集:数据比较的方式。
校对集有三种格式:
_bin:binary,二进制比较,取出二进制位,一位一位的比较,区分大小写。
_cs:case sensitive,大小写敏感,区分大小写。
_ci:case insensitive,大小写不敏感,不区分大小写。
查看数据库所支持的校对集:show collation;
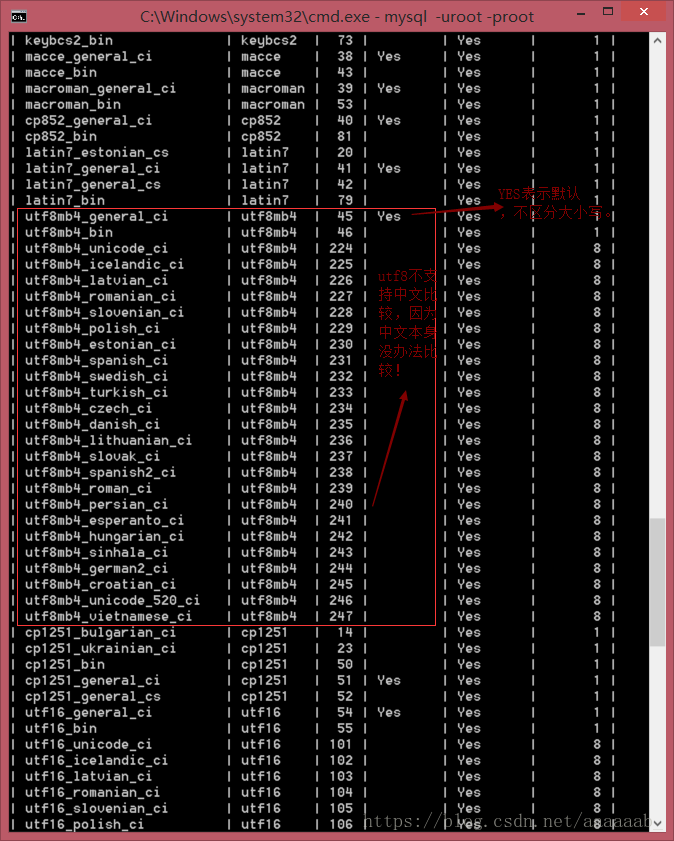
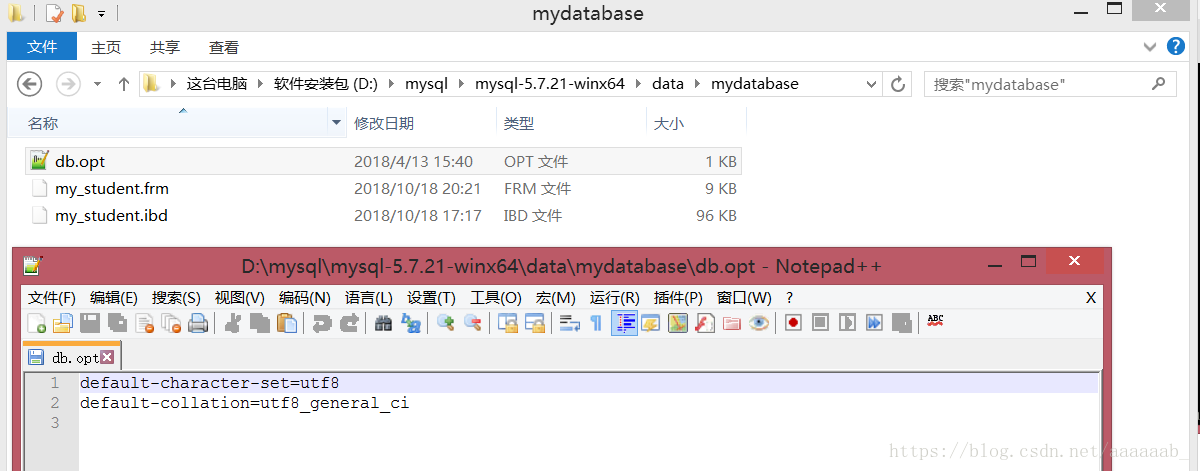
校对集的应用:
只有当数据产生比较的时候,校对集才会生效。我们可以打开Mysql的默认安装的data目录下打开数据库下的opt文件查看默认
校对集,可以看到默认校对集为_ci,意味着不区分大小写。
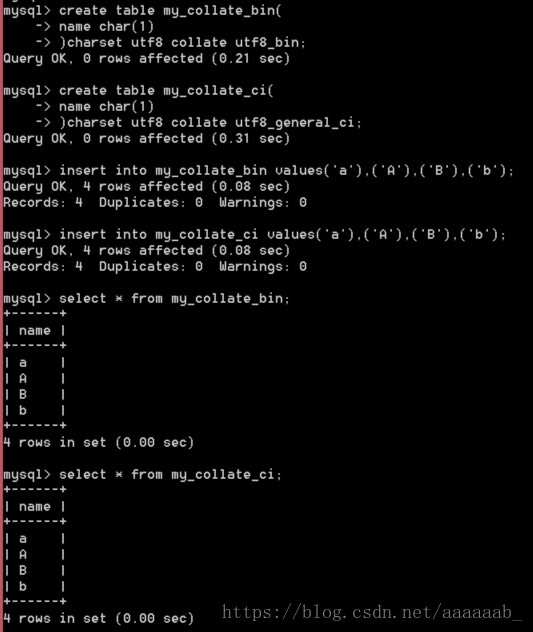
对比校对集不同的效果:
1.创建不同校对集对应的表:
create table my_collate_bin(
name char(1)
) charset utf8 collate utf8_bin;
create table my_collate_ci( ##其实这里不强调默认的也是_ci校对集
name char(1)
) charset utf8 collate utf8_general_ci;
2.插入数据:
insert into my_collate_bin values('a'),('A'),('B'),('b');
insert into my_collate_ci values('a'),('A'),('B'),('b');
3.查看数据,由于没有比较校对集不生效所以看起来一样:
select * from my_collate_bin;
select * from my_collate_ci;
进行比较使得校对集生效:
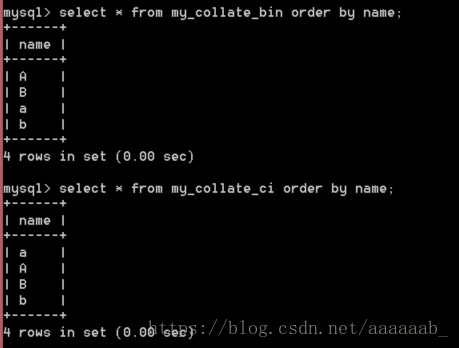
比较:根据某个字段进行排序:order by 字段名 [asc|desc]; asc 升序,desc 降序,默认是升序。
---排序查看区别
select * from my_collate_bin order by name; 排列之后会呈现升序,因为小写的ASCLL码比大写的大。
select * from my_collate_ci order by name; 由于不区分大小写a和A,b和B是一样的,而且b的ASCLLC码比a大
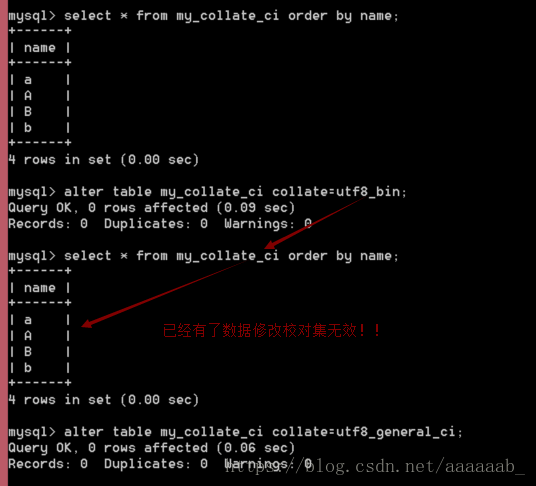
校对集的特点:
校对集:必须在没有数据之前声明好,如果有了数据,那么再进行校对集的修改,此修改无效;
---有数据之后再修改校对集
alter table my_collate_ci collate=utf8_bin;
select * from my_collate_ci order by name; 发现修改校对集之后排序依旧没有变化因为修改没有生效
alter table my_collate_ci collate=utf8_general_ci; 重新改回来
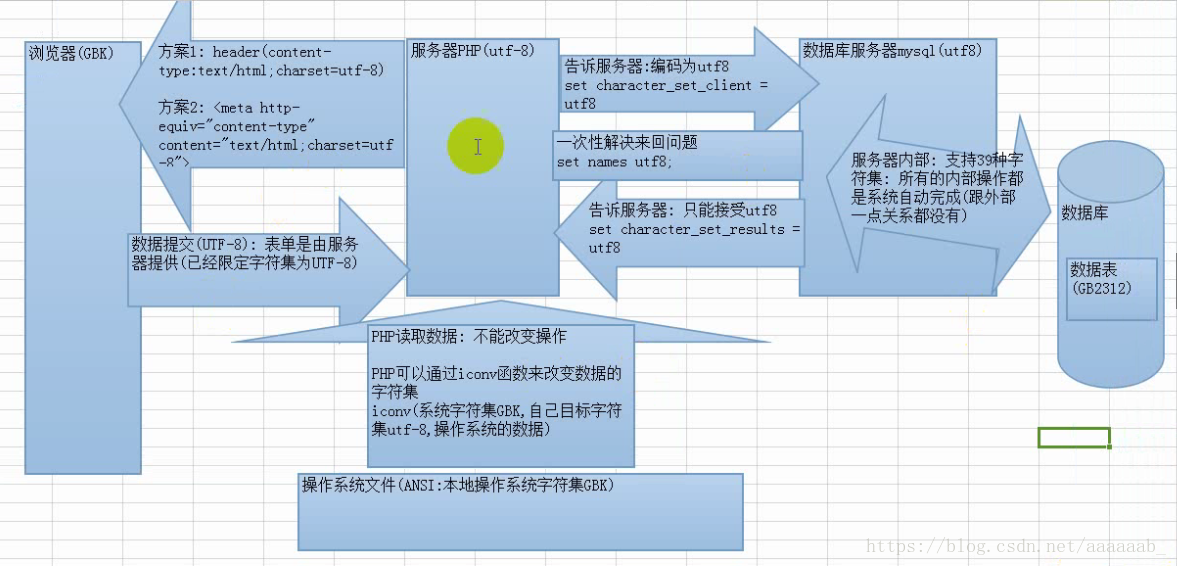
web乱码问题:
动态网站有三个部分组成:浏览器,Apache服务器(PHP),数据库服务器,三个部分都有自己的字符集(中文),数据
在三个部分之间来回传递很容易产生乱码。
如何解决乱码问题:
我们可以规定统一编码(三码合一),但是事实上是不可能的,因为浏览器是用户管理的(根本不可能进行控制),如果真的
要解决这些问题,主要还是看PHP来做。