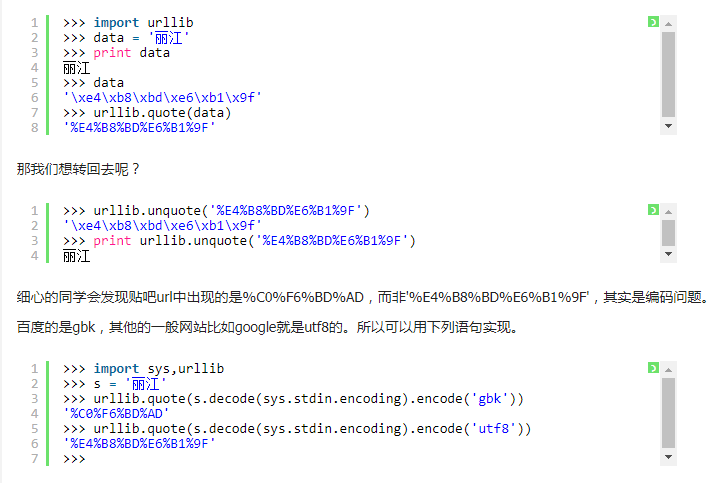
使用urllib中的quote,和unquote方法将汉字编码成gbk(2个百分号对应一个汉字)或者utf8(3个百分号对应一个汉字)
注意用%加密汉字时,汉字不能是Unicode编码格式,否则会报错(解决办法:把Unicode编码的中文转换成str格式----->另一篇博客短文有)
>>> import sys,urllib
>>> s = '汉字' >>> type(s) <type 'str'> >>> s '\xba\xba\xd7\xd6' >>> s1 = u'汉字' >>> type(s1) <type 'unicode'> >>> s1 u'\u6c49\u5b57'
>>> urllib.quote(s.decode(sys.stdin.encoding).encode('gbk')) '%BA%BA%D7%D6' >>> urllib.quote(s1.decode(sys.stdin.encoding).encode('gbk')) Traceback (most recent call last): File "<pyshell#20>", line 1, in <module> urllib.quote(s1.decode(sys.stdin.encoding).encode('gbk')) UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
>>> urllib.quote(s) '%BA%BA%D7%D6' >>> urllib.quote(s1) Traceback (most recent call last): File "<pyshell#22>", line 1, in <module> urllib.quote(s1) File "D:\Python27\lib\urllib.py", line 1298, in quote return ''.join(map(quoter, s)) KeyError: u'\u6c49'