title:
date: 2018-8-21 15:16:59
tags:
---
下载题目和数据:百度网盘
解决方案
- 数据预处理:Preprocess.py
首先,打开文件UCI.xls,然后读取数据,然后我们发现数据共分为18列,
第一列是目标值,其余17列是特征值。
目标值是字母,不能用于直接处理,然后我们将字母转化为数字,让计算机可以量化计算。
其次,让处理后的文件输出到另一个Excel文件中。
最后,我们可以得到一个矩阵,它包含了特征变量和目标变量。
如何对这些字母进行分类成为了我们现在的目标,其实这个问题可以归类为一个分类问题。
怎样根据特征对数据进行分类?
很多框架提供了接口,可以供我们直接调用,或者自己设计。
使用接口有一个很大的好处就是,我们会省力,但是也有很大的缺陷,就是不能定制化。
而使用我们自己设计的算法恰好相反,费力可定制,结果或许会更加准确。
首先,我们可以对数据进行一个直观的观察,看这些数据字母有什么区别。
解决问题的过程中,凡是可以用到的工具都可以用,不用考虑什么python处理高大上,用Excel处理就很low。不是这样的。
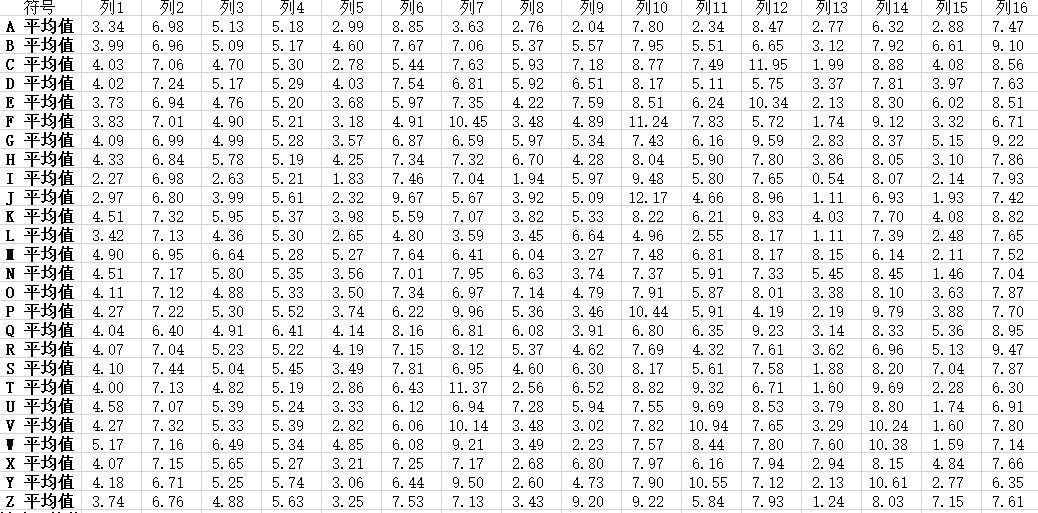
首先对数据按照字母进行排序
然后对每个字母的各个特征值求均值(数据分类汇总)
结果如下:
分类问题一个很重要的特征就是,类间的间距争取最大化,类内间距最小化
根据上面的特征我们可以剔除掉一部分特征值,如果类间间距太小的话,我们选择舍弃。
衡量类间的间距我们选择使用方差来作为一个衡量的指标。
根据分类汇总后的数据,我们求每一列的方差,并剔除掉方差小于1的列。
结果如下:
0.33 0.05 0.60 0.07 0.61 1.31 3.30 2.54 2.88 1.97 4.33 2.40 3.25 1.32 3.08 0.71
因此,我们只剩下了10个特征:列
下面根据这10个特征对数据进行分类:列6-列15
接下来需要对数据做进一步的处理,Input为10个特征值,Output为字母对应的ASCII码
将这些数据整理到一个文件中,方便用到时直接调用
现在,这些数据虽然在一个量级上,但是却不能确定每个特征比较起来还是有些差距的
于是,对数据做归一化处理,目的是为了保证能够更加精准的判断
然后,将一部分数据作为训练数据,剩下的一部分测试
- 建立模型:BuildModel.py
选择使用PaddlePaddle框架中的线性回归模型
首先检查PaddlePaddle是否安装成功:
进入python解释器,然后使用import paddle.fluid验证,无报错,说明成功
安装Paddle的Windows需要专业版,家庭中文版的不行,想安装的话,可以试着用虚拟机,装一个Linux
成功后我们就可以使用这个框架来解决我们的问题了。
首先,线性回归是怎么回事,高中就学过,这里就不做过多解释了
既然使用人家的工具,就需要先阅读使用手册,使用这个工具需要做些什么
首先配置数据提供器:import paddle import paddle.fluid as fluid import numpy from __future__ import print_function
- 主程序:main.py