一、引入
关于leetcode中第三题Longest Substring Without Repeating Characters 问题,网上已有不少解答,并提出了切实可行的算法实现。我在解答该题时参考了http://articles.leetcode.com/2011/05/longest-substring-without-repeating-characters.html和http://www.aichengxu.com/view/11060的解答。为让读者更直观地阅读和理解本文,先简要摘录问题和相关算法如下:
题目还原
Longest Substring Without Repeating Characters
Given a string, find the length of the longest substring without repeating characters. For example, the longest substring without repeating letters for “abcabcbb” is “abc”, which the length is 3. For “bbbbb” the longest substring is “b”, with the length of 1.解答及算法
用一个left和right下标来记录目前考察的字符子串的开头和结尾;
用mark[256]来标记当前字符子串中出现过的字符;
每次利用mark数组判断right对应的字符是否出现过:
1.若已经出现过,则将left向右移动到该字符之前出现位置的后一位,同时在移动过程中将left经过的位对应的字符在mark中恢复为“未出现”(因为left经过的位已经不在当前考察的字符子串之内),并将right右移一位;
2.若没有出现过,则将right对应的字符在mark中标记为“已出现”,并将right右移一位关键算法图示
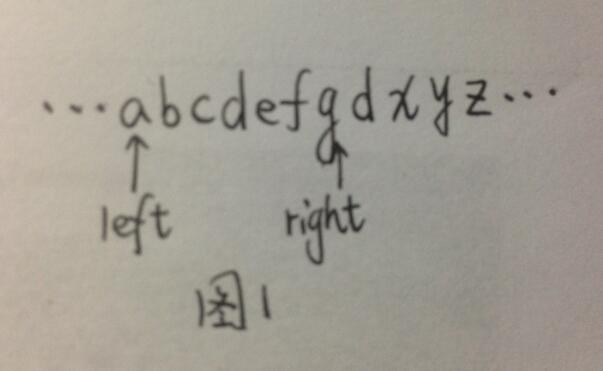
1.如图1所示,假设left当前指在字符’a’处,right指向字符’g’时,由于‘g’在之前未出现过(指left到right的字符子串中未出现),则将g标识为已出现,并将right右移一位;
2.如图2所示,此时left仍指向字符’a’处,right指向第二个’d’,由于’d’在之前已出现过,则将left移动至’e’处(如图3所示),在移动过程中将left经过的’a’,’b’,’c’,’d’对应的mark值恢复为“未出现”(因为’a’,’b’,’c’,’d’已排除到left和right之外),并将right右移一位;
3.重复以上两步。C++代码实现
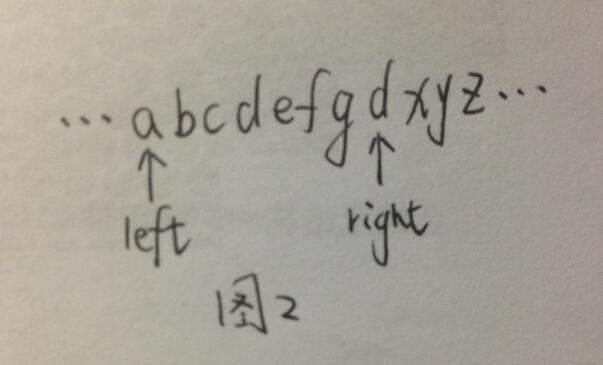
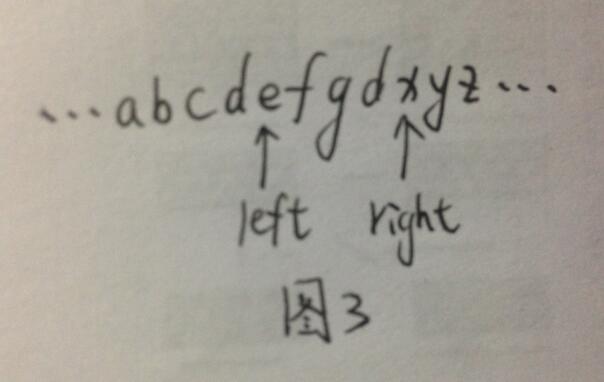
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int len = s.length();
int right = 0;
int left = 0;
int max=-1;
int distance;
int mark[256] = {0};
while(right<len)
{
if(mark[s[right]]==1)
{
distance = right-left;
max = max > distance ? max : distance;
while(s[left]!=s[right])
{
mark[s[left]] = 0;
left++;
}
left++;
right++;
}
else
{
mark[s[right]] = 1;
right++;
}
}
distance = right - left;
return max > distance ? max : distance;
}
};二、问题的提出
经代码的实现检验,以上算法是切实可行的。但如何从数学或逻辑的角度证明以上算法的正确性。
由于left和right都是从字符串的第一个字符开始向右移动的,移动的过程中使用图示的关键算法,只要保证关键算法在移动left和right的过程中不会遗漏更长的非重复字符子串即可。
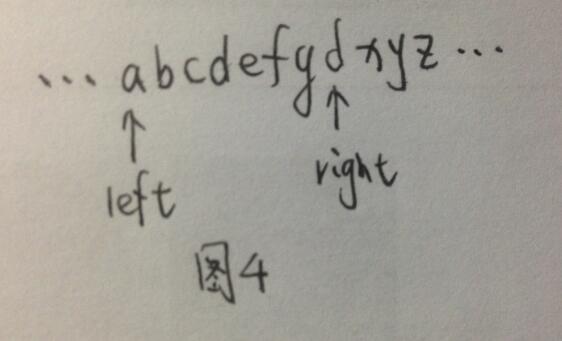
以图4为例,当left在字符’a’处,right在第二个’d’处时,只需证明当left向右移动至’e’时,不会遗漏更长的非重复字符子串。
三、问题的解决
如图5所示,将字符串分割为3个区间。

1.当right右移至区间1或区间2时,此时left到right形成的字符子串不包含重复字符,且right越往右,字符子串越长;
2.当right已经右移至区间3时,若left仍处于区间1,那么left到right形成的字符子串必定包含重复字符,因而left至少右移至区间2。
综合1和2,当left移动至字符’a’时,其之后出现的最长非重复字符子串只可能由两种情况构成:
一种是在right移动至第二个’d’之前出现的最长子串,
另一种是left右移至’e’后,right继续右移形成的子问题。
从而可以证明,图示的关键算法并不会遗漏更长的非重复字符子串。