本文主要是将之前学习的Trident做一个总结,由于Trident的资料相对较少,排坑过程中相对艰难(也可能是我打开的方式不对orz),本文主要将Trident API的各种实现给罗列了一下,主要分为如下几个部分:
- 概述: 讲述需求
- Trident实现WordCount
- RedisState实践
- Trident DRPC 实践
- TridentKafkaSpout实践
具体的代码不再做过多的解释,均在注解中体现,其他可以参考之前的博文或官方文档具体深入学习。
概述
需求:我们要通过Trident对一个文本中的词频进行统计.
本例将从如下这样一个无限的输入流中读取语句作为输入:
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true); //为了更好理解tuple按照batch处理数据,这里设置为true
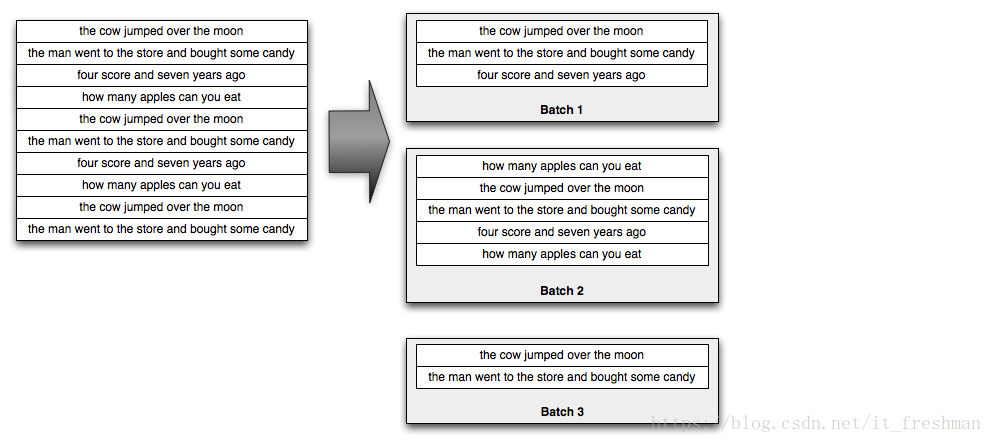
这个 spout 会循环 sentences 数据集,不断输出 sentence stream ,
Trident 在处理输入 stream 的时候会转换成 batch (包含若干个 tuple )来处理. 比如说, 输入的 sentence stream 可能会被拆分成如下的 batch :
pom.xml
由于storm的各组件个版本插件差异较大,这里列出本机的主要的maven依赖。
<properties>
<kafka.version>1.1.1</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>${storm.version}</version>
<type>jar</type>
</dependency>
</dependencies>
普通处理
public class WordCountApp {
//构建topology
private static StormTopology buildTopology() {
FixedBatchSpout spout1 = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout1.setCycle(false);
TridentTopology topology = new TridentTopology();
Stream sentenceStream = topology.newStream("spout1", spout1);
Stream wordStream = sentenceStream.each(new Fields("sentence"), new Split(), new Fields("word"));
TridentState wordCountState = wordStream.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
//打印count后结果
wordCountState.newValuesStream()
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println("【统计】--------" + input);
}
});
return topology.build();
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("app0", conf, buildTopology());
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, buildTopology());
}
}
}
RedisState
package cn.jhs.storm.trident.example.redis;
import com.google.common.collect.Lists;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.redis.common.config.JedisPoolConfig;
import org.apache.storm.redis.common.mapper.RedisDataTypeDescription;
import org.apache.storm.redis.common.mapper.RedisLookupMapper;
import org.apache.storm.redis.common.mapper.RedisStoreMapper;
import org.apache.storm.redis.trident.state.*;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.trident.Stream;
import org.apache.storm.trident.TridentState;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.*;
import org.apache.storm.trident.operation.builtin.Count;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.testing.MemoryMapState;
import org.apache.storm.trident.testing.Split;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.ITuple;
import org.apache.storm.tuple.Values;
import java.util.List;
/**
* @author Trump
* @desc
* @date 2018/10/15 14:12
*/
public class RedisTridentStateApp1 {
//构建topology
private static StormTopology buildTopology() {
//1.构建数据源spout
FixedBatchSpout spout1 = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout1.setCycle(false);
TridentTopology topology = new TridentTopology();
//2.构建sentence Stream
Stream sentenceStream = topology.newStream("spout1", spout1);
//3.构建wordStream
Stream wordStream = sentenceStream.each(new Fields("sentence"), new Split(), new Fields("word"));
//4.构建RedisState Factory
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder().setHost("192.168.129.157").setPort(6379) .build();
RedisState.Factory factory = new RedisState.Factory(poolConfig);
//5.构建query、update Function
RedisStoreMapper storeMapper = new WordCountStoreMapper();
RedisLookupMapper lookupMapper = new WordCountLookupMapper();
//6.统计 word count,并存储到MemoryMapState中
Stream wordCountStream = wordStream.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(),new Fields("word"),new Count(),new Fields("count"))
.newValuesStream();
//7.将wordCount 存储到RedisState中
wordCountStream.partitionPersist(factory, new Fields("word","count"), new RedisStateUpdater(storeMapper).withExpire(86400000) , new Fields());
TridentState state = topology.newStaticState(factory);
//8.1 构建查询stream
FixedBatchSpout queryParamSpout = new FixedBatchSpout(new Fields("param"), 1, new Values("the"));
//8.2 将查询的fields 转换为state中已存在的stream
Stream fmtedQueryParamStream = topology.newStream("querySpout", queryParamSpout)
//将接收的 param 重命名为 word
.map(new MapFunction() {
@Override
public Values execute(TridentTuple input) {
return new Values(input.getString(0));
}
}, new Fields("word"));
//8.3 查询 param 在state 中的count值
fmtedQueryParamStream.stateQuery(state, new Fields("word"),
new RedisStateQuerier(lookupMapper),
new Fields("columnName", "columnValue"))
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
String columnName = input.getStringByField("columnName");
String columnValue = input.getStringByField("columnValue");
System.out.println("lookupMapper=========" + columnName+":"+columnValue);
}
});
return topology.build();
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("app1", conf, buildTopology());
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, buildTopology());
}
}
}
class WordCountLookupMapper implements RedisLookupMapper {
private RedisDataTypeDescription description;
private final String hashKey = "wordCount";
public WordCountLookupMapper() {
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH, hashKey);
}
@Override
public List<Values> toTuple(ITuple input, Object value) {
String member = getKeyFromTuple(input);
List<Values> values = Lists.newArrayList();
values.add(new Values(member, value));
return values;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("wordName", "count"));
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
return null;
}
}
class WordCountStoreMapper implements RedisStoreMapper {
private RedisDataTypeDescription description;
private final String hashKey = "wordCount";
public WordCountStoreMapper() {
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH, hashKey);
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
return tuple.getLongByField("count").toString();
}
}
Redis集群使用
Set<InetSocketAddress> nodes = new HashSet<InetSocketAddress>();
for (String hostPort : redisHostPort.split(",")) {
String[] host_port = hostPort.split(":");
nodes.add(new InetSocketAddress(host_port[0], Integer.valueOf(host_port[1])));
}
JedisClusterConfig clusterConfig = new JedisClusterConfig.Builder().setNodes(nodes).build();
RedisClusterState.Factory factory = new RedisClusterState.Factory(clusterConfig);
wordCountStream.partitionPersist(factory,
fields,
new RedisClusterStateUpdater(storeMapper).withExpire(86400000),
new Fields());
fmtedQueryParamStream.stateQuery(state, new Fields("word"),
new RedisClusterStateQuerier(lookupMapper),
new Fields("columnName","columnValue"));
TridentDrpc
public class WordCountDrpcApp2 {
//将输入的sentence 按照 “ ”分割为 words[]
static class MySplit extends BaseFunction {
private String label;
public MySplit(String label) {
this.label = label;
}
public MySplit() {
this("sentence");
}
@Override
public void execute(TridentTuple input, TridentCollector collector) {
String sentence = input.getString(0);
log(label, sentence);
for (String word : sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
//仅打印出 tuple
static class PrintPeekConsumer implements Consumer {
private String label;
public PrintPeekConsumer(String label) {
this.label = label;
}
@Override
public void accept(TridentTuple input) {
log(label, input);
}
}
//打印工具类
static void log(String label, Object input) {
System.out.println("【" + label + "】--------" + input);
}
//可循环的FixedBatchSpout,可以指定loop循环次数
static class LoopFixedBatchSpout extends FixedBatchSpout {
private int loop = 1;
public LoopFixedBatchSpout(int loop, Fields fields, int maxBatchSize, List<Object>... outputs) {
super(fields, maxBatchSize, outputs);
this.loop = loop;
}
public LoopFixedBatchSpout(Fields fields, int maxBatchSize, List<Object>... outputs) {
super(fields, maxBatchSize, outputs);
}
@Override
public void emitBatch(long batchId, TridentCollector collector) {
while (loop > 0) {
super.emitBatch(batchId, collector);
loop--;
}
}
}
//构建topology
private static StormTopology buildTopology(LocalDRPC drpc) {
int loop = new Random().nextInt(5)+1;
System.out.println("=============初始化loop:"+loop+"=============");
FixedBatchSpout spout1 = new LoopFixedBatchSpout(loop, new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout1.setCycle(false);
TridentTopology topology = new TridentTopology();
Stream sentenceStream = topology.newStream("spout1", spout1);
Stream wordStream = sentenceStream.each(new Fields("sentence"), new MySplit(), new Fields("word"))
.peek(new PrintPeekConsumer("word"));
TridentState wordCountState = wordStream.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
//打印count后结果
wordCountState.newValuesStream()
.peek(new PrintPeekConsumer("count"));
topology.newDRPCStream("countWordFunc", drpc)
.each(new Fields("args"), new MySplit("drpc"), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCountState, new Fields("word"), new MapGet(), new Fields("count"))
.peek(new PrintPeekConsumer("drpc-count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
return topology.build();
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
if (args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("app2", conf, buildTopology(drpc));
for (int i = 0; i < 20; i++) {
Thread.sleep(180L);
//使用LocalDRPC 结果需要在wordCountState处理完成之后,才可正确计算,故后续的结果可能为 e.g.: "[[0]]"或者"[[5 * loop]]".....
System.out.println("############## DRPC RESULT: " + drpc.execute("countWordFunc", "cat dog the man"));
}
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, buildTopology(null));
}
}
}
注意:使用DRPC需要注意,在使用LocalDRPC时,计算的结果可能与预期的结果不同,那是因为storm正在计算中,或者尚未开始执行计算。
TridentKafkaSpout
private static StormTopology buildTopology() {
TridentTopology topology = new TridentTopology();
BrokerHosts zk = new ZkHosts("s163:2181", "/brokers");
//订阅topic=scada
TridentKafkaConfig spoutConf = new TridentKafkaConfig(zk, "testTopic1", "cosumerGroup9");
//schemae定义默认outputFields= "str"
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
// Read latest messages from Kafka
// -1:LatestTime , -2:EarliestTime
spoutConf.startOffsetTime = -1;
OpaqueTridentKafkaSpout spout2 = new OpaqueTridentKafkaSpout(spoutConf);
Stream stream = topology.newStream("spout2", spout2)
.each(new Fields("str"), new BaseFunction() {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String msg = tuple.getStringByField("str");
try {
Map info = new ObjectMapper().readValue(msg, Map.class);
//解析获取 消息中的latnId,并emit
String latnId = MapUtils.getString(info, "latnId");
collector.emit(new Values(msg, latnId));
} catch (IOException e) {
e.printStackTrace();
}
}
}, new Fields("msg", "latnId"))
.groupBy(new Fields("latnId"))
//统计各个批次中 按照latnId分区的数据总量有多少条
.aggregate(new Fields("latnId"), new Count(), new Fields("count"))
.parallelismHint(5)
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println("=========" + input.getStringByField("latnId") + "::" + input.getLongByField("count"));
}
});
return topology.build();
}
msg消息为json格式,如下
{
"key4" : "value4",
"latnId" : "010",
"msg" : "xxxx",
"msgId" : "1"
}