一、数组相关的其他函数
1、求阶乘
语法:np. prod()
#随机创建一个数组
arr = np.array(np.arange(1,6))
#计算数组的阶乘
np.prod(arr)
2.计算数组元素的累积乘积
语法:np. cumprod()
np.cumprod(arr)
3.数组的修剪
语法:ndarray.clip()
np.ndarray.clip(min,max):大于max的值会被重设成max,小于min的值会被重设成min;不指定min max默认为min 可以只选一个 也可以都选
#创建一个数组
arr1=np.arange(10)
#修剪数组
arr1.clip(2,5) #给定一个最小值2,最大值5,所有比2小的值都变成2(最小值),所有比5大的值都变成5(最大值)
array([2, 2, 2, 3, 4, 5, 5, 5, 5, 5])
4.数组的压缩
语法:ndarray.compress()
返回一个根据给定条件筛选后的数组,用于数据的筛选
# 数组的压缩 ndarray.compres() :返回一个根据给定条件 筛选后的数组
scores = np.random.randint(60,100,9) # 60-100以内的随机数9个
#输出score数组中大于90的数
mark = scores>90 # 输出的是布尔值
#法一:
scores[mark] #输出的是大于90的值
#法二:
scores.compress(mark)
5.求和
语法:np.sum()
# 求和 np.sum()
np.sum(scores)
二、日期处理函数-datetime模块
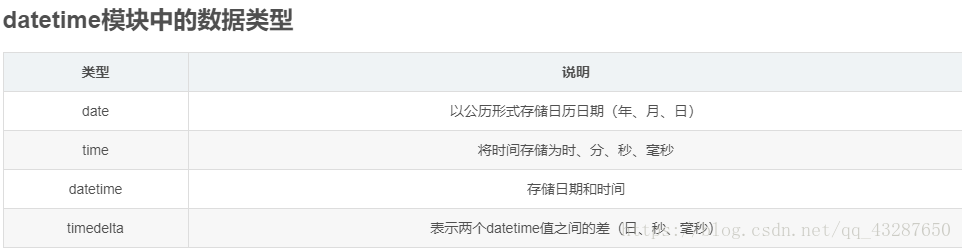
import numpy as np
from datetime import datetime
1.datatime. strptime(‘指定日期’,’格式字符串’)
str='2018-10-01 08:09:10.11'
time1=datetime.strptime(str,'%Y-%m-%d %H:%M:%S.%f')
time1
datetime.datetime(2018, 10, 1, 8, 9, 10, 110000)
将日期转换为字符串
# 将日期转化为字符串
str1 = time1.strftime('%Y-%m-%d %H:%M:%S.%f')
str1
'2018-10-01 08:09:10.110000'
2.获取date类型
只能获取年月日
time1.date()
datetime.date(2018, 10, 1)
获取time1的时分秒
time1.time()
datetime.time(8, 9, 10, 110000)
3.获取星期几
time1.weekday() #10月1号是周一,下标为0
#真实的周几,从1开始 isoweekday()
time1.isoweekday()
4.获取年、月、日、时、分、秒、毫秒、当前时间
time1.year#年
time1.month#月
time1.day #日
time1.hour#小时
time1.minute#分
time1.second#秒
time1.microsecond#微秒
nowtime=datetime.now() #当前时间
注意:获取年~微秒都没有加括号
5.直接生成指定日期
nextyear=datetime(2019,2,5) #只有年月日有值
6.计算时间差
nextyear-nowtime #计算时间差
datetime.timedelta(116, 16934, 726639)
只有三个参数,第一个参数是days(天),第二个参数是seconds(秒),第三个参数是microseconds(毫秒)
(nextyear-nowtime).days #时间差按天数计算
(nextyear-nowtime).seconds #时间差按秒计算
(nextyear-nowtime).microseconds # 时间差显示毫秒
7.时间间隔
from datetime import timedelta #导入模块
time_d=timedelta(10,0,0)#参数是 天,秒,毫秒
nowtime+time_d #现在的时间加上一个时间间隔
三、案例
获取给定时间范围内交易日周一、周二、周三、周四、周五分别对应的平均收盘价及哪天的平均收盘价最高,哪天的平均收盘价最低。
步骤:
1.将给定的日期转换 datetime.strptime()
2.求出日期对应是星期几
3.处理data.csv文件中的日期
4.分别求出各星期的平均收盘价
5.比较高低
1-2步:
#日期是 日-月-年,定义一个函数,将字符串类型的数据转换为datetime类型.并且返回是周几的数字.
#因为我的CSV文件是gbk编码的,所以我在后加上了decode('utf-8')
def weekdayNum(datestr):
return datetime.strptime(datestr.decode('utf-8'),'%d-%m-%Y').isoweekday()
3-4步:
读取数据 loadtxt 参数 converters = {colNum(第几列):函数名}
#读取数据 读取文件的时候,源文件是什么编码比较重要,默认是gbk,如果源文件是utf-8,则要加上 encoding='utf-8'
#如果源文件不是utf-8,记得读取的字符串需要解码,在函数处解决问题即可。
dates,close = np.loadtxt('data.csv',delimiter=',',unpack=True,usecols=(1,-2),
skiprows=1,converters={1:weekdayNum}) # 对第一列的数据使用weekdayNum 这个函数 转化为星期几,一般使用converters参数都要定义函数。
#现在我们要将周一、周二、周三、周四、周五的收盘价分别打包起来
#创建一个数组来存周一~周五的值
averages = np.zeros(5)
#遍历周一-周五的所有数据
for i in range(1,6):
#获取每个数1-5在原始数据中的下标
indices=np.where(dates==i)
# print(i,indices)
#获取结果集
# result = np.take(close,indices) #法一
# result=close[indices]#法二
result = close.compress(dates==i) #法三
print(result)
averages[i-1]=np.mean(result)
5步:
使用np.argmax() 和np.argmin() 获取最大值和最小值对应的下标
maxIndex=np.argmax(averages)
minIndex=np.argmin(averages)
print('一周中星期',maxIndex+1,'平均收盘价最高')
print('一周中星期',minIndex+1,'平均收盘价最低')