第一题:
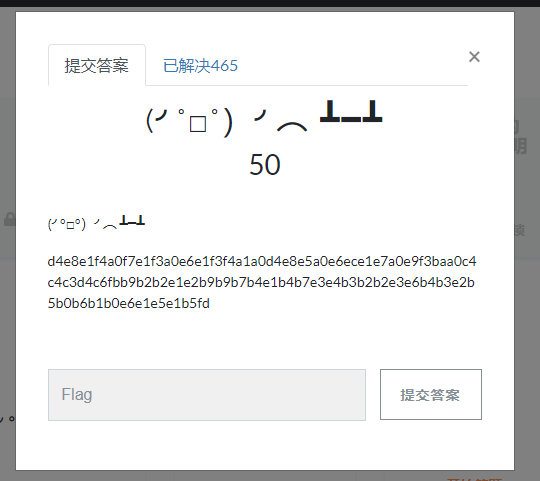
d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd
解题思路:
首先尝试各种解密,无果。
开始研究,分析字符串,首先看看有哪些字符,然后准备分析频率
import string cipertext = "d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd" for i in string.lowercase: if i in cipertext: print i for i in string.digits: if i in cipertext: print i
打印出来发现字符串由a-f 0-9组成,瞬间想到16进制格式,开始向16进制进攻
len()查看到字符长度为134,16进制一般是两个字符组成一个字节,所以两个两个拆解分开试试
cipertext = "d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd" i = 0 plaintext = "" while i < 133: plaintext += str(int(cipertext[i:i + 2], 16)) + " " i += 2 print plaintext
得到212 232 225 244 160 247 225 243 160 230 225 243 244 161 160 212 232 229 160 230 236 225 231 160 233 243 186 160 196 196 195 212 198 251 185 178 178 225 226 185 185 183 180 225 180 183 227 228 179 178 178 227 230 180 179 226 181 176 182 177 176 230 225 229 225 181 253
明显看到超出常规ascii范围,考虑尝试凯撒解密,由于ascii有128字符,尝试先减去128
cipertext = "d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd" i = 0 plaintext = "" while i < 133: asciinum = int(cipertext[i:i + 2], 16)-128 plaintext += chr(asciinum) i += 2 print plaintext
得到flag
第二题:
打开下载的windows.jpg
非常普通的一张图,看到图片,第一联想到隐写术,自行用binwalk看看图片有没有藏东西
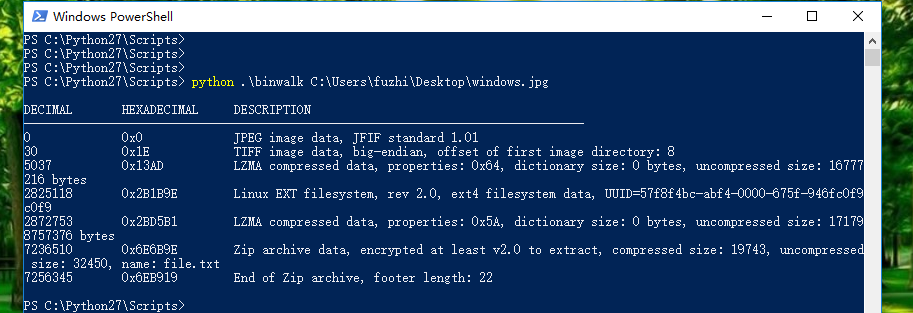
一大堆东西,尝试提取分离,得到一个zip,打开一看需要密码
这里可以用暴力破解,不过花费时间较长,期间可以做一些其他事情,比如去看看图片的详细信息(可能藏东西)
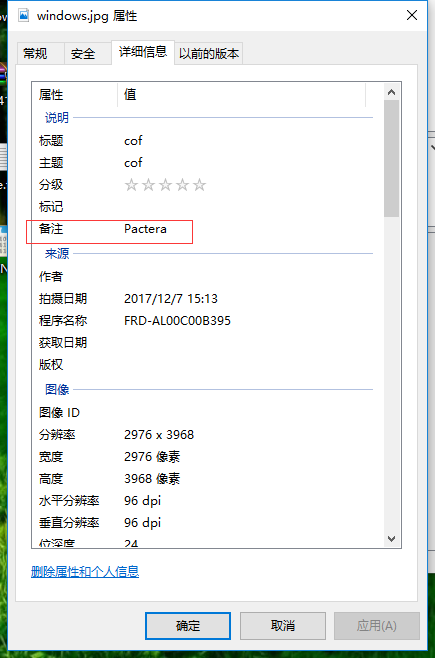
在备注找到Pactera,尝试作为密码输入,解压成功Orz...............
打开file.txt
进行一顿栅栏,编码等解密,无果。
破了很久,最后回头看题目看了的提示

尝试分析字符频率,然后进行排序
file1 = open("file.txt", "r") cipertext = file1.read() dic1 = {} for i in cipertext: if i not in dic1: dic1[i] = 1 else: dic1[i] += 1 z = zip(dic1.values(), dic1.keys()) plaintext = "" for i in sorted(z): plaintext = i[1] + plaintext print plaintext
直接得到flag
第三题:

本题差评!!!干扰项太多,不亲切,这里不再赘述踩的坑
下载得到附件,是一个pcap文件,果断丢入wireshark,把解析的到的文件一次导出
只有IMF的能导出,分析查看,大概在一个文件比较大的地方,看到
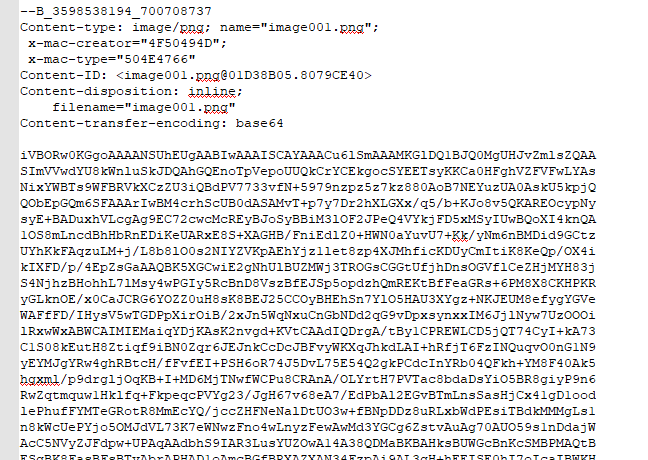
复制出来,看到是base64,解码,得到一串字符
这个看到应该是一张图片,所以这里保存成图片看一看。。
#!/usr/bin/env python # coding=utf-8 import base64 file1 = open("test", "r") cipertext = file1.read() file1.close() plaintext = base64.b64decode(cipertext) # 读取file1进行base64解码 file2 = open("testpng.png", "wb") # 以.png写入保存 file2.write(plaintext) file2.close()
打开我们刚才保存的图片

这里就要使用图像识别了,ocr了解一下
#!/usr/bin/env python # coding=utf-8 import base64 import pytesseract from PIL import Image def getcode(imgurl): """识别图片""" image = Image.open(imgurl) vcode = pytesseract.image_to_string(image) code = base64.b64decode(vcode.encode("utf-8")) return code temp_imgurl = 'testpng.png' code = getcode(temp_imgurl) print code
这里无敌坑,ocr识别准确率不是很高,code得到后还要和图片进行比对检查。
根据提示,补全RSA
-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQDCm6vZmclJrVH1AAyGuCuSSZ8O+mIQiOUQCvN0HYbj8153JfSQ
LsJIhbRYS7+zZ1oXvPemWQDv/u/tzegt58q4ciNmcVnq1uKiygc6QOtvT7oiSTyO
vMX/q5iE2iClYUIHZEKX3BjjNDxrYvLQzPyGD1EY2DZIO6T45FNKYC2VDwIDAQAB
AoGAbtWUKUkx37lLfRq7B5sqjZVKdpBZe4tL0jg6cX5Djd3Uhk1inR9UXVNw4/y4
QGfzYqOn8+Cq7QSoBysHOeXSiPztW2cL09ktPgSlfTQyN6ELNGuiUOYnaTWYZpp/
QbRcZ/eHBulVQLlk5M6RVs9BLI9X08RAl7EcwumiRfWas6kCQQDvqC0dxl2wIjwN
czILcoWLig2c2u71Nev9DrWjWHU8eHDuzCJWvOUAHIrkexddWEK2VHd+F13GBCOQ
ZCM4prBjAkEAz+ENahsEjBE4+7H1HdIaw0+goe/45d6A2ewO/lYH6dDZTAzTW9z9
kzV8uz+Mmo5163/JtvwYQcKF39DJGGtqZQJBAKa18XR16fQ9TFL64EQwTQ+tYBzN
+04eTWQCmH3haeQ/0Cd9XyHBUveJ42Be8/jeDcIx7dGLxZKajHbEAfBFnAsCQGq1
AnbJ4Z6opJCGu+UP2c8SC8m0bhZJDelPRC8IKE28eB6SotgP61ZqaVmQ+HLJ1/wH
/5pfc3AmEyRdfyx6zwUCQCAH4SLJv/kprRz1a1gx8FR5tj4NeHEFFNEgq1gmiwmH
2STT5qZWzQFz8NRe+/otNOHBR2Xk4e8IS+ehIJ3TvyE=
-----END RSA PRIVATE KEY-----
看到这个rsa秘钥,自然联想到ssl,搜索一下(ssl了解一下)

看到了ssl的通信
把秘钥导入

重启wireshark,惊奇地发现在最后多了http

追踪http流
