第1章 设备驱动简介
1.1 驱动程序的角色
机制:提供什么能力.
策略:如何使用这些能力.
1.2. 划分内核
内核的角色可以划分:
一:进程管理
二:内存管理
三:文件系统
四:设备控制
五:网络
1.2.1. 可加载模块
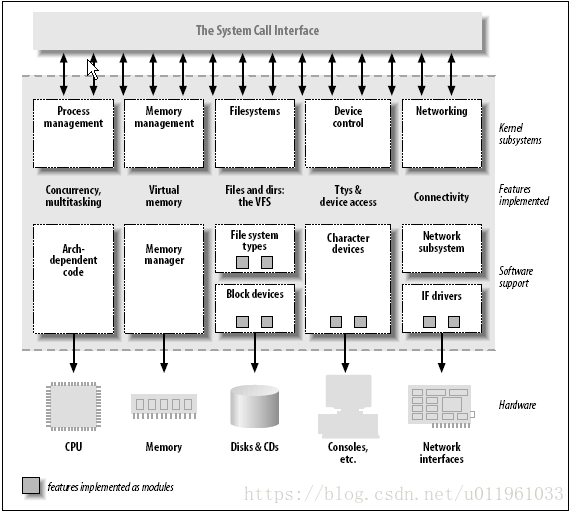
1.3. 设备和模块的分类
字符设备:
块设备:
网络接口
第 2 章 建立和运行模块
2.2. Hello World 模块
1:使用makfile建立内核树
2:第四章介绍内核的消息的传递的机制,消息保存在哪里的问题.
2.3. 内核模块相比于应用程序
应用程序:
1:从头到尾执行单个任务.
2:使用库函数,在链接时能解析外部引用.
3:运行在用户空间
内核模块:
1:模块初始化函数的任务是为以后调用模块的函数做准备,
2:仅能调用内核导出的函数
3:内核空间.
避免名字空间污染(namespace pollution),所有符号采用静态变量(static)见"内核符号表".
2.3.1. 用户空间和内核空间
2.3.2. 内核的并发
2.3.3. 当前进程
current 指针指向当前在运行的进程
2.4. 编译和加载
2.4.1. 编译模块
请参考GNU make
file:E:\26.2012linux%C5%E0%D1%B5\Linux%20Basic\1.1Linux%20Base%20Introduction\makefile\GNU%20MAKE%20%D6%D0%CE%C4%CA%D6%B2%E1.pdf
2.4.2. 加载和卸载模块
insmod,
lsmod,等价cat /proc/modules
rmmod,
modprobe,
cat /proc/iomem
cat /proc/ioports
2.4.3. 版本依赖
2.4.4. 平台依赖性
2.5. 内核符号表
cat /proc/kallsyms 查看内核符号表.
2.7. 初始化和关停
1:初始化
static int __init initialization_function(void)
{
/* Initialization code here */
}
module_init(initialization_function);
2:清理函数
static void __exit cleanup_function(void)
{
/* Cleanup code here */
}
module_exit(cleanup_function);
2.8. 模块参数
static char *whom = "world";
static int howmany = 1;
module_param(howmany, int, S_IRUGO);
module_param(whom, charp, S_IRUGO);
2.10. 快速参考
/sys/module
/proc/modules
/sys/module 是一个 sysfs 目录层次, 包含当前加载模块的信息. /proc/moudles 是旧式的, 那种信息的单个文件版本. 其中的条目包含了模块名, 每个模块占用的内存数量, 以及使用计数. 另外的字串追加到每行的末尾来指定标志, 对这个模块当前是活动的.
eg:
/ # cat /proc/modules
ntfs 98900 0 - Live 0xbf932000
v4l2_common 4980 0 - Live 0xbf91b000
uvcvideo 62464 0 - Live 0xbf908000
videodev 77112 2 v4l2_common,uvcvideo, Live 0xbf8f2000
v4l2_int_device 3520 0 - Live 0xbf8f0000
fuse 69080 0 - Live 0xbf8dc000
mali 233956 6 - Live 0xbf89b000
ump 46392 7 mali, Live 0xbf88e000
blcr 104716 0 - Live 0xbf871000
第 3 章 字符驱动
3.1. scull 的设计
scull0-scull3:
scullpipe0 -scullpipe3:
scullsingle
scullpriv
sculluid
scullwuid
3.2. 主次编号
主编号标识设备相连的驱动:
次编号被内核用来决定引用哪个设备.
3.2.1. 设备编号的内部表示
3.2.2. 分配和释放设备编号
3.2.3. 主编号的动态分配
alloc_chrdev_region
3.3. 一些重要数据结构
3.3.1. 文件操作

struct module *owner
第一个 file_operations 成员根本不是一个操作; 它是一个指向拥有这个结构的模块的指针. 这个成员用来在它的操作还在被使用时阻止模块被卸载. 几乎所有时间中, 它被简单初始化为 THIS_MODULE, 一个在 <linux/module.h> 中定义的宏.
loff_t (*llseek) (struct file *, loff_t, int);
llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值. loff_t 参数是一个"long offset", 并且就算在 32位平台上也至少 64 位宽. 错误由一个负返回值指示. 如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在"file 结构" 一节中描述).
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
用来从设备中获取数据. 在这个位置的一个空指针导致 read 系统调用以 -EINVAL("Invalid argument") 失败. 一个非负返回值代表了成功读取的字节数( 返回值是一个 "signed size" 类型, 常常是目标平台本地的整数类型).
ssize_t (*aio_read)(struct kiocb *, char __user *, size_t, loff_t);
初始化一个异步读 -- 可能在函数返回前不结束的读操作. 如果这个方法是 NULL, 所有的操作会由 read 代替进行(同步地).
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
发送数据给设备. 如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数.
ssize_t (*aio_write)(struct kiocb *, const char __user *, size_t, loff_t *);
初始化设备上的一个异步写.
int (*readdir) (struct file *, void *, filldir_t);
对于设备文件这个成员应当为 NULL; 它用来读取目录, 并且仅对文件系统有用.
unsigned int (*poll) (struct file *, struct poll_table_struct *);
poll 方法是 3 个系统调用的后端: poll, epoll, 和 select, 都用作查询对一个或多个文件描述符的读或写是否会阻塞. poll 方法应当返回一个位掩码指示是否非阻塞的读或写是可能的, 并且, 可能地, 提供给内核信息用来使调用进程睡眠直到 I/O 变为可能. 如果一个驱动的 poll 方法为 NULL, 设备假定为不阻塞地可读可写.
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
ioctl 系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道, 这不是读也不是写). 另外, 几个 ioctl 命令被内核识别而不必引用 fops 表. 如果设备不提供 ioctl 方法, 对于任何未事先定义的请求(-ENOTTY, "设备无这样的 ioctl"), 系统调用返回一个错误.
int (*mmap) (struct file *, struct vm_area_struct *);
mmap 用来请求将设备内存映射到进程的地址空间. 如果这个方法是 NULL, mmap 系统调用返回 -ENODEV.
int (*open) (struct inode *, struct file *);
尽管这常常是对设备文件进行的第一个操作, 不要求驱动声明一个对应的方法. 如果这个项是 NULL, 设备打开一直成功, 但是你的驱动不会得到通知.
int (*flush) (struct file *);
flush 操作在进程关闭它的设备文件描述符的拷贝时调用; 它应当执行(并且等待)设备的任何未完成的操作. 这个必须不要和用户查询请求的 fsync 操作混淆了. 当前, flush 在很少驱动中使用; SCSI 磁带驱动使用它, 例如, 为确保所有写的数据在设备关闭前写到磁带上. 如果 flush 为 NULL, 内核简单地忽略用户应用程序的请求.
int (*release) (struct inode *, struct file *);
在文件结构被释放时引用这个操作. 如同 open, release 可以为 NULL.
int (*fsync) (struct file *, struct dentry *, int);
这个方法是 fsync 系统调用的后端, 用户调用来刷新任何挂着的数据. 如果这个指针是 NULL, 系统调用返回 -EINVAL.
int (*aio_fsync)(struct kiocb *, int);
这是 fsync 方法的异步版本.
int (*fasync) (int, struct file *, int);
这个操作用来通知设备它的 FASYNC 标志的改变. 异步通知是一个高级的主题, 在第 6 章中描述. 这个成员可以是NULL 如果驱动不支持异步通知.
int (*lock) (struct file *, int, struct file_lock *);
lock 方法用来实现文件加锁; 加锁对常规文件是必不可少的特性, 但是设备驱动几乎从不实现它.
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
这些方法实现发散/汇聚读和写操作. 应用程序偶尔需要做一个包含多个内存区的单个读或写操作; 这些系统调用允许它们这样做而不必对数据进行额外拷贝. 如果这些函数指针为 NULL, read 和 write 方法被调用( 可能多于一次 ).
ssize_t (*sendfile)(struct file *, loff_t *, size_t, read_actor_t, void *);
这个方法实现 sendfile 系统调用的读, 使用最少的拷贝从一个文件描述符搬移数据到另一个. 例如, 它被一个需要发送文件内容到一个网络连接的 web 服务器使用. 设备驱动常常使 sendfile 为 NULL.
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
sendpage 是 sendfile 的另一半; 它由内核调用来发送数据, 一次一页, 到对应的文件. 设备驱动实际上不实现 sendpage.
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中. 这个任务通常由内存管理代码进行; 这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求. 大部分驱动可以置这个方法为 NULL.[10]
int (*check_flags)(int)
这个方法允许模块检查传递给 fnctl(F_SETFL...) 调用的标志.
int (*dir_notify)(struct file *, unsigned long);
这个方法在应用程序使用 fcntl 来请求目录改变通知时调用. 只对文件系统有用; 驱动不需要实现 dir_notify
3.3.2. 文件结构
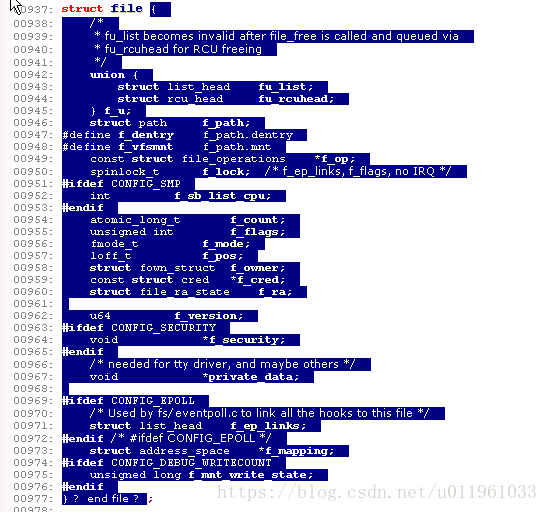
mode_t f_mode;
文件模式确定文件是可读的或者是可写的(或者都是), 通过位 FMODE_READ 和 FMODE_WRITE. 你可能想在你的 open 或者 ioctl 函数中检查这个成员的读写许可, 但是你不需要检查读写许可, 因为内核在调用你的方法之前检查. 当文件还没有为那种存取而打开时读或写的企图被拒绝, 驱动甚至不知道这个情况.
loff_t f_pos;
当前读写位置. loff_t 在所有平台都是 64 位( 在 gcc 术语里是 long long ). 驱动可以读这个值, 如果它需要知道文件中的当前位置, 但是正常地不应该改变它; 读和写应当使用它们作为最后参数而收到的指针来更新一个位置, 代替直接作用于 filp->f_pos. 这个规则的一个例外是在 llseek 方法中, 它的目的就是改变文件位置.
unsigned int f_flags;
这些是文件标志, 例如 O_RDONLY, O_NONBLOCK, 和 O_SYNC. 驱动应当检查 O_NONBLOCK 标志来看是否是请求非阻塞操作( 我们在第一章的"阻塞和非阻塞操作"一节中讨论非阻塞 I/O ); 其他标志很少使用. 特别地, 应当检查读/写许可, 使用 f_mode 而不是 f_flags. 所有的标志在头文件 <linux/fcntl.h> 中定义.
struct file_operations *f_op;
和文件关联的操作. 内核安排指针作为它的 open 实现的一部分, 接着读取它当它需要分派任何的操作时. filp->f_op 中的值从不由内核保存为后面的引用; 这意味着你可改变你的文件关联的文件操作, 在你返回调用者之后新方法会起作用. 例如, 关联到主编号 1 (/dev/null, /dev/zero, 等等)的 open 代码根据打开的次编号来替代 filp->f_op 中的操作. 这个做法允许实现几种行为, 在同一个主编号下而不必在每个系统调用中引入开销. 替换文件操作的能力是面向对象编程的"方法重载"的内核对等体.
void *private_data;
open 系统调用设置这个指针为 NULL, 在为驱动调用 open 方法之前. 你可自由使用这个成员或者忽略它; 你可以使用这个成员来指向分配的数据, 但是接着你必须记住在内核销毁文件结构之前, 在 release 方法中释放那个内存. private_data 是一个有用的资源, 在系统调用间保留状态信息, 我们大部分例子模块都使用它.
struct dentry *f_dentry;
关联到文件的目录入口( dentry )结构. 设备驱动编写者正常地不需要关心 dentry 结构, 除了作为 filp->f_dentry->d_inode 存取 inode 结构.
3.3.3. inode 结构

dev_t i_rdev;
对于代表设备文件的节点, 这个成员包含实际的设备编号.
struct cdev *i_cdev;
struct cdev 是内核的内部结构, 代表字符设备; 这个成员包含一个指针, 指向这个结构, 当节点指的是一个字符设备文件时
3.4. 字符设备注册
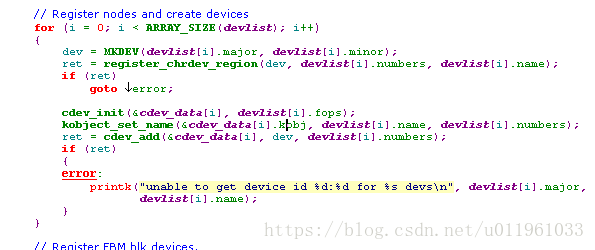
第一步:注册:register_chrdev_region(dev_t,unsigned,const char*)//传入dev_t
第二步:初始化:void cdev_init(struct cdev *cdev, struct file_operations *fops);//得到struct cdev 结构指针
第三步:激活:int cdev_add(struct cdev *dev, dev_t num, unsigned int count);
第四步:销毁:void cdev_del(struct cdev *dev);
3.5. open 和 release
3.5.1. open 方法
int (*open)(struct inode *inode, struct file *filp);
open 方法提供给驱动来做任何的初始化来准备后续的操作. 在大部分驱动中, open 应当进行下面的工作:
1.检查设备特定的错误(例如设备没准备好, 或者类似的硬件错误
2.如果它第一次打开, 初始化设备
3.如果需要, 更新 f_op 指针.
4.分配并填充要放进 filp->private_data 的任何数据结构
3.5.2. release 方法
1.释放 open 分配在 filp->private_data 中的任何东西
2.在最后的 close 关闭设备
3.6. scull 的内存使用
在 scull, 每个设备是一个指针链表, 每个都指向一个 scull_dev 结构. 每个这样的结构, 缺省地, 指向最多 4 兆字节, 通过一个中间指针数组. 发行代码使用一个 1000 个指针的数组指向每个 4000 字节的区域. 我们称每个内存区域为一个量子, 数组(或者它的长度) 为一个量子集. 一个 scull 设备和它的内存区如图一个 scull 设备的布局所示.
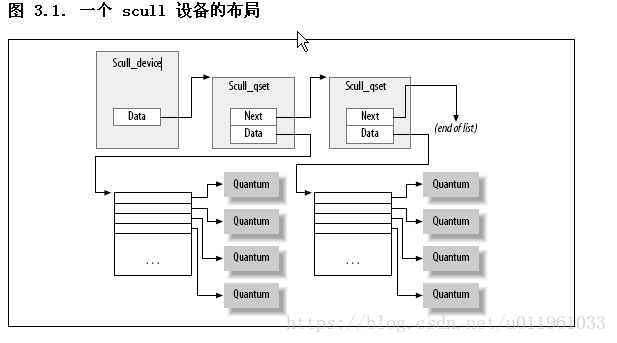
3.7. 读和写
ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);
3.7.1. read 方法
1.如果这个值等于传递给 read 系统调用的 count 参数, 请求的字节数已经被传送. 这是最好的情况.
2.如果是正数, 但是小于 count, 只有部分数据被传送. 这可能由于几个原因, 依赖于设备. 常常, 应用程序重新试着读取. 例如, 如果你使用 fread 函数来读取, 库函数重新发出系统调用直到请求的数据传送完成.
3.如果值为 0, 到达了文件末尾(没有读取数据).
4.一个负值表示有一个错误. 这个值指出了什么错误, 根据 <linux/errno.h>. 出错的典型返回值包括 -EINTR( 被打断的系统调用) 或者 -EFAULT( 坏地址 ).
3.7.2. write 方法
1.如果值等于 count, 要求的字节数已被传送.
2.如果正值, 但是小于 count, 只有部分数据被传送. 程序最可能重试写入剩下的数据.
3.如果值为 0, 什么没有写. 这个结果不是一个错误, 没有理由返回一个错误码. 再一次, 标准库重试写调用. 我们将在第 6 章查看这种情况的确切含义, 那里介绍了阻塞.
4.一个负值表示发生一个错误; 如同对于读, 有效的错误值是定义于 <linux/errno.h>中.
3.7.3. readv 和 writev
第 4 章 调试技术
4.2. 用打印调试
4.2.1. printk
1.记录级别或者优先级在消息上

2.也可以通过文本文件 /proc/sys/kernel/printk 读写控制台记录级别.
# echo 8 > /proc/sys/kernel/printk
4.2.2. 重定向控制台消息
4.2.3. 消息是如何记录的
4.2.4. 打开和关闭消息
4.2.5. 速率限制
4.2.6. 打印设备编号
4.3. 用查询来调试(cat /proc/****)
4.3.1. 使用 /proc 文件系统
4.4. 使用观察来调试
运行命令 strace
4.5. 调试系统故障
4.5.1. oops 消息
4.5.2. 系统挂起
4.6. 调试器和相关工具
第 5 章 并发和竞争情况
5.1. scull中的缺陷
2个进程同时访问一个函数:即由并发引起的竞争.
5.2. 并发和它的管理
矛盾:硬件/软件资源需要共享,共享就存在并发/竞争.
即:当 2 个执行的线路[17]有机会操作同一个数据结构(或者硬件资源), 混合的可能性就一直存在
解决办法:
加锁.数据结构的操作原子化
5.3. 旗标和互斥体
进程在等待锁,去睡眠/阻塞.(但是有几种情况不能使用.)
旗标:在计算机科学中是一个被很好理解的概念. 在它的核心, 一个旗标是一个单个整型值, 结合有一对函数, 典型地称为 P(加锁) 和 V(解锁). 一个想进入临界区的进程将在相关旗标上调用 P; 如果旗标的值大于零, 这个值递减 1 并且进程继续. 相反, 如果旗标的值是 0 ( 或更小 ), 进程必须等待直到别人释放旗标. 解锁一个旗标通过调用 V 完成; 这个函数递增旗标的值, 并且, 如果需要, 唤醒等待的进程.
5.3.1. Linux 旗标实现
linux/semapore.h

1);创建:
void sema_init(struct semaphore *sem, int val);
这里 val 是安排给旗标的初始值.(通常有0/1)
然而, 通常旗标以互斥锁的模式使用. 为使这个通用的例子更容易些, 内核提供了一套帮助函数和宏定义. 因此, 一个互斥锁可以声明和初始化, 使用下面的一种:
DECLARE_MUTEX(name);
DECLARE_MUTEX_LOCKED(name);//注释
这里, 结果是一个旗标变量( 称为 name ), 初始化为 1 ( 使用 DECLARE_MUTEX ) 或者 0 (使用 DECLARE_MUTEX_LOCKED ). 在后一种情况, 互斥锁开始于上锁的状态; 在允许任何线程存取之前将不得不显式解锁它.
如果互斥锁必须在运行时间初始化( 这是如果动态分配它的情况, 举例来说), 使用下列中的一个:
void init_MUTEX(struct semaphore *sem);
void init_MUTEX_LOCKED(struct semaphore *sem);
2) 加锁/P 函数(系列down函数):这个函数递减旗标的值,
void down(struct semaphore *sem);
//注释:down 递减旗标值并且等待需要的时间
int down_interruptible(struct semaphore *sem);
//但是操作是可中断的. 这个可中断的版本几乎一直是你要的那个; 它允许一个在等待一个旗标的用户空间进程被用户中断. 作为一个通用的规则, 你不想使用不可中断的操作, 除非实在是没有选择. 不可中断操作是一个创建不可杀死的进程( 在 ps 中见到的可怕的 "D 状态" )和惹恼你的用户的好方法, 使用 down_interruptible 需要一些格外的小心, 但是, 如果操作是可中断的, 函数返回一个非零值, 并且调用者不持有旗标. 正确的使用 down_interruptible 需要一直检查返回值并且针对性地响应.
int down_trylock(struct semaphore *sem);
//从不睡眠; 如果旗标在调用时不可用, down_trylock 立刻返回一个非零值
3)解锁/U 函数:
void up(struct semaphore *sem);
一旦 up 被调用, 调用者就不再拥有旗标.
5.3.2. 在 scull 中使用旗标
5.3.3. 读者/写者旗标
<linux/rwsem.h>.
1);创建:
void init_rwsem(struct rw_semaphore *sem);
2):读接口
void down_read(struct rw_semaphore *sem);
int down_read_trylock(struct rw_semaphore *sem);
void up_read(struct rw_semaphore *sem);
对 down_read 的调用提供了对被保护资源的只读存取, 与其他读者可能地并发地存取. 注意 down_read 可能将调用进程置为不可中断的睡眠. down_read_trylock 如果读存取是不可用时不会等待; 如果被准予存取它返回非零, 否则是 0. 注意 down_read_trylock 的惯例不同于大部分的内核函数, 返回值 0 指示成功. 一个使用 down_read 获取的 rwsem 必须最终使用 up_read 释放.
3):写接口
读者的接口类似:
void down_write(struct rw_semaphore *sem);
int down_write_trylock(struct rw_semaphore *sem);
void up_write(struct rw_semaphore *sem);
void downgrade_write(struct rw_semaphore *sem);
down_write, down_write_trylock, 和 up_write 全部就像它们的读者对应部分, 除了, 当然, 它们提供写存取. 如果你处于这样的情况, 需要一个写者锁来做一个快速改变, 接着一个长时间的只读存取, 你可以使用 downgrade_write 在一旦你已完成改变后允许其他读者进入.
5.4. Completions 机制
1 问题:在进程之间传递事件完成,效率不高.
内核编程的一个普通模式包括在当前线程之外初始化某个动作, 接着等待这个动作结束. 这个动作可能是创建一个新内核线程或者用户空间进程, 对一个存在着的进程的请求, 或者一些基于硬件的动作. 在这些情况中, 很有诱惑去使用一个旗标来同步 2 个任务, 使用这样的代码:
struct semaphore sem;
init_MUTEX_LOCKED(&sem);
start_external_task(&sem);
down(&sem);
外部任务可以接着调用 up(??sem), 在它的工作完成时.
事实证明, 这种情况旗标不是最好的工具. 正常使用中, 试图加锁一个旗标的代码发现旗标几乎在所有时间都可用; 如果对旗标有很多竞争, 性能会受损并且加锁方案需要重新审视. 因此旗标已经对"可用"情况做了很多的优化. 当用上面展示的方法来通知任务完成, 然而, 调用 down 的线程将几乎是一直不得不等待; 因此性能将受损. 旗标还可能易于处于一个( 困难的 ) 竞争情况, 如果它们表明为自动变量以这种方式使用时. 在一些情况中, 旗标可能在调用 up 的进程用完它之前消失.
2 解决办法:/"completion" 接口
<linux/completion.h>
1) 必须动态创建和初始化
init_completion(&my_completion);
2) 等待 completion
void wait_for_completion(struct completion *c);
3)真正的 completion 事件
void complete(struct completion *c);
void complete_all(struct completion *c);
5.5. 自旋锁
概念:
自旋锁概念上简单. 一个自旋锁是一个互斥设备, 只能有 2 个值:"上锁"和"解锁". 它常常实现为一个整数值中的一个单个位. 想获取一个特殊锁的代码测试相关的位. 如果锁是可用的, 这个"上锁"位被置位并且代码继续进入临界区. 相反, 如果这个锁已经被别人获得, 代码进入一个紧凑的循环中反复检查这个锁, 直到它变为可用. 这个循环就是自旋锁的"自旋"部分
5.5.1. 自旋锁 API 简介
自旋锁原语要求的包含文件是 <linux/spinlock.h>. 一个实际的锁有类型 spinlock_t. 象任何其他数据结构, 一个 自旋锁必须初始化. 这个初始化可以在编译时完成, 如下:
spinlock_t my_lock = SPIN_LOCK_UNLOCKED;
或者在运行时使用:
void spin_lock_init(spinlock_t *lock);
在进入一个临界区前, 你的代码必须获得需要的 lock , 用:
void spin_lock(spinlock_t *lock);
注意所有的自旋锁等待是, 由于它们的特性, 不可中断的. 一旦你调用 spin_lock, 你将自旋直到锁变为可用.
为释放一个你已获得的锁, 传递它给:
void spin_unlock(spinlock_t *lock);
有很多其他的自旋锁函数, 我们将很快都看到. 但是没有一个背离上面列出的函数所展示的核心概念. 除了加锁和释放, 没有什么可对一个锁所作的. 但是, 有几个规则关于你必须如何使用自旋锁. 我们将用一点时间来看这些, 在进入完整的自旋锁接口之前.
5.5.2. 自旋锁和原子上下文
问题:死锁:自旋锁中的操控是原子操作,避免进程去睡眠,失去处理器,如数据copy:copy_from_user,kmalloc==.
第一种情况(内核方面):
想象一会儿你的驱动请求一个自旋锁并且在它的临界区里做它的事情. 在中间某处, 你的驱动失去了处理器. 或许它已调用了一个函数( copy_from_user, 假设) 使进程进入睡眠. 或者, 也许, 内核抢占发威, 一个更高优先级的进程将你的代码推到一边. 你的代码现在持有一个锁, 在可见的将来的如何时间不会释放这个锁. 如果某个别的线程想获得同一个锁, 它会, 在最好的情况下, 等待( 在处理器中自旋 )很长时间. 最坏的情况, 系统可能完全死锁.
第二种情况(设备方面):
你的驱动在执行并且已经获取了一个锁来控制对它的设备的存取. 当持有这个锁时, 设备发出一个中断, 使得你的中断处理运行. 中断处理, 在存取设备之前, 必须获得锁. 在一个中断处理中获取一个自旋锁是一个要做的合法的事情; 这是自旋锁操作不能睡眠的其中一个理由. 但是如果中断处理和起初获得锁的代码在同一个处理器上会发生什么? 当中断处理在自旋, 非中断代码不能运行来释放锁. 这个处理器将永远自旋.
避免这个陷阱需要在持有自旋锁时禁止中断( 只在本地 CPU ). 有各种自旋锁函数会为你禁止中断( 我们将在下一节见到它们 ). 但是, 一个完整的中断讨论必须等到第 10 章了
5.5.3. 自旋锁函数
1)加锁函数:
void spin_lock(spinlock_t *lock);
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);////禁止中断,在获得自旋锁之前; 之前的中断状态保存在 flags 里.
void spin_lock_irq(spinlock_t *lock);//
void spin_lock_bh(spinlock_t *lock);//在获取锁之前禁止软件中断, 但是硬件中断留作打开的.
2)解锁函数:
void spin_unlock(spinlock_t *lock);
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags);
void spin_unlock_irq(spinlock_t *lock);
void spin_unlock_bh(spinlock_t *lock);
3)还有一套非阻塞的自旋锁操作:
int spin_trylock(spinlock_t *lock);
int spin_trylock_bh(spinlock_t *lock);
5.5.4. 读者/写者自旋锁
内核提供了一个自旋锁的读者/写者形式, 直接模仿我们在本章前面见到的读者/写者旗标. 这些锁允许任何数目的读者同时进入临界区, 但是写者必须是排他的存取. 读者写者锁有一个类型 rwlock_t, 在 <linux/spinlokc.h> 中定义. 它们可以以 2 种方式被声明和被初始化:
rwlock_t my_rwlock = RW_LOCK_UNLOCKED; /* Static way */
rwlock_t my_rwlock;
rwlock_init(&my_rwlock); /* Dynamic way */
可用函数的列表现在应当看来相当类似. 对于读者, 下列函数是可用的:
void read_lock(rwlock_t *lock);
void read_lock_irqsave(rwlock_t *lock, unsigned long flags);
void read_lock_irq(rwlock_t *lock);
void read_lock_bh(rwlock_t *lock);
void read_unlock(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void read_unlock_irq(rwlock_t *lock);
void read_unlock_bh(rwlock_t *lock);
有趣地, 没有 read_trylock. 对于写存取的函数是类似的:
void write_lock(rwlock_t *lock);
void write_lock_irqsave(rwlock_t *lock, unsigned long flags);
void write_lock_irq(rwlock_t *lock);
void write_lock_bh(rwlock_t *lock);
int write_trylock(rwlock_t *lock);
void write_unlock(rwlock_t *lock);
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void write_unlock_irq(rwlock_t *lock);
void write_unlock_bh(rwlock_t *lock);
读者/写者锁能够饿坏读者, 就像 rwsem 一样. 这个行为很少是一个问题; 然而, 如果有足够的锁竞争来引起饥饿, 性能无论如何都不行.
5.6. 锁陷阱
1)一个函数需要一个锁,接着调用另外一个函数也试图请求这个锁,就会死锁.
2)外部调用的函数必须明确处理加锁.内部函数/静态函数调用者已经获取了相关的锁,但是call其他函数要明确是否持有锁.
3)尽力避免获取多个锁,如果没法避免,就以同意的顺序去获取锁.
4)如果你确实怀疑锁竞争在损坏性能, 你可能发现 lockmeter 工具有用. 这个补丁(从 http://oss.sgi.com/projects/lockmeter/ 可得到) 装备内核来测量在锁等待花费的时间. 通过看这个报告, 你能够很快知道是否锁竞争真的是问题.
5.7. 加锁的各种选择
5.7.1 环形缓冲
5.7.2. 原子变量(没有必要为一个共享的全局变量而加锁)
<asm/atomic.h>
1)初始化:
atomic_t v = ATOMIC_INIT(0);
void atomic_set(atomic_t *v, int i);
2)数据操作:
int atomic_read(atomic_t *v);
void atomic_add(int i, atomic_t *v);
void atomic_sub(int i, atomic_t *v);
void atomic_inc(atomic_t *v);
void atomic_dec(atomic_t *v);
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
int atomic_add_negative(int i, atomic_t *v);
int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);
5.7.3. 位操作
<asm/bitops.h>/<linux/bitops.h>
2)数据操作:
void set_bit(nr, void *addr);
void clear_bit(nr, void *addr);
void change_bit(nr, void *addr);
test_bit(nr, void *addr);
int test_and_set_bit(nr, void *addr);
int test_and_clear_bit(nr, void *addr);
int test_and_change_bit(nr, void *addr);
5.7.4. seqlock 锁
seqlock 通常不能用在保护包含指针的数据结构, 因为读者可能跟随着一个无效指针而写者在改变数据结构.
<linux/seqlock.h>.
1)初始化:
seqlock_t lock1 = SEQLOCK_UNLOCKED;
seqlock_t lock2;
seqlock_init(&lock2);
2) 读操作:
读存取通过在进入临界区入口获取一个(无符号的)整数序列来工作. 在退出时, 那个序列值与当前值比较; 如果不匹配, 读存取必须重试. 结果是, 读者代码象下面的形式:
unsigned int seq;
do {
seq = read_seqbegin(&the_lock);
/* Do what you need to do */
} while read_seqretry(&the_lock, seq);
IRQ 安全的版本
unsigned int read_seqbegin_irqsave(seqlock_t *lock, unsigned long flags);
int read_seqretry_irqrestore(seqlock_t *lock, unsigned int seq, unsigned long flags);
3) 写操作
void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags);
void write_seqlock_irq(seqlock_t *lock);
void write_seqlock_bh(seqlock_t *lock);
void write_sequnlock_irqrestore(seqlock_t *lock, unsigned long flags);
void write_sequnlock_irq(seqlock_t *lock);
void write_sequnlock_bh(seqlock_t *lock);
5.7.5. 读取-拷贝-更新
使用 RCU 的代码应当包含 <linux/rcupdate.h>.
struct my_stuff *stuff;
rcu_read_lock();
stuff = find_the_stuff(args...);
do_something_with(stuff);
rcu_read_unlock();
第 6 章 高级字符驱动操作

6.1. ioctl 接口
1)在用户空间, ioctl 系统调用有下面的原型:
int ioctl(int fd, unsigned long cmd, ...);
特点:ioctl 调用的非结构化,在不同的系统中控制操作混杂,主要通过包括嵌入命令到数据流/使用虚拟文件系统(要么是 sysfs 要么是设备特定的文件系统.)
2)内核态原型
int (*ioctl) (struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg);
6.1.1. 选择 ioctl 命令

type
魔数. 只是选择一个数(在参考了 ioctl-number.txt之后)并且使用它在整个驱动中. 这个成员是 8 位宽(_IOC_TYPEBITS).
number
序(顺序)号. 它是 8 位(_IOC_NRBITS)宽.
direction
数据传送的方向,如果这个特殊的命令涉及数据传送. 可能的值是 _IOC_NONE(没有数据传输), _IOC_READ, _IOC_WRITE, 和 _IOC_READ|_IOC_WRITE (数据在2个方向被传送). 数据传送是从应用程序的观点来看待的; _IOC_READ 意思是从设备读, 因此设备必须写到用户空间. 注意这个成员是一个位掩码, 因此 _IOC_READ 和 _IOC_WRITE 可使用一个逻辑 AND 操作来抽取.
size
涉及到的用户数据的大小. 这个成员的宽度是依赖体系的, 但是常常是 13 或者 14 位. 你可为你的特定体系在宏 _IOC_SIZEBITS 中找到它的值. 你使用这个 size 成员不是强制的 - 内核不检查它 -- 但是它是一个好主意. 正确使用这个成员可帮助检测用户空间程序的错误并使你实现向后兼容, 如果你曾需要改变相关数据项的大小. 如果你需要更大的数据结构, 但是, 你可忽略这个 size 成员. 我们很快见到如何使用这个成员
6.1.2. 返回值
6.1.3. 预定义的命令
预定义命令分为 3 类:
1)可对任何文件发出的(常规, 设备, FIFO, 或者 socket) 的那些.//
如:
FIOCLEX
设置 close-on-exec 标志(File IOctl Close on EXec). 设置这个标志使文件描述符被关闭, 当调用进程执行一个新程序时.
FIONCLEX
清除 close-no-exec 标志(File IOctl Not CLose on EXec). 这个命令恢复普通文件行为, 复原上面 FIOCLEX 所做的. FIOASYNC 为这个文件设置或者复位异步通知(如同在本章中"异步通知"一节中讨论的). 注意直到 Linux 2.2.4 版本的内核不正确地使用这个命令来修改 O_SYNC 标志. 因为两个动作都可通过 fcntl 来完成, 没有人真正使用 FIOASYNC 命令, 它在这里出现只是为了完整性.
FIOQSIZE
这个命令返回一个文件或者目录的大小; 当用作一个设备文件, 但是, 它返回一个 ENOTTY 错误.
FIONBIO
"File IOctl Non-Blocking I/O"(在"阻塞和非阻塞操作"一节中描述). 这个调用修改在 filp->f_flags 中的 O_NONBLOCK 标志. 给这个系统调用的第 3 个参数用作指示是否这个标志被置位或者清除. (我们将在本章看到这个标志的角色). 注意常用的改变这个标志的方法是使用 fcntl 系统调用, 使用 F_SETFL 命令.
2)只对常规文件发出的那些.
3)对文件系统类型特殊的那些.
6.1.4. 使用 ioctl 参数
<asm/uaccess.h>
1)数据检查

2)从用户空间拷贝数据: copy_from_user

2)拷贝数据到用户空间: copy_to_user

4)其他更高效的函数
put_user(datum, ptr)
__put_user(datum, ptr)
get_user(local, ptr)
__get_user(local, ptr)
6.1.5. 兼容性和受限操作
1)进程能力
<linux/capability.h>
其中设备文件关心的能力:
CAP_DAC_OVERRIDE
这个能力来推翻在文件和目录上的存取的限制(数据存取控制, 或者 DAC).
CAP_NET_ADMIN
进行网络管理任务的能力, 包括那些能够影响网络接口的.
CAP_SYS_MODULE
加载或去除内核模块的能力.
CAP_SYS_RAWIO
进行 "raw" I/O 操作的能力. 例子包括存取设备端口或者直接和 USB 设备通讯.
CAP_SYS_ADMIN
一个捕获-全部的能力, 提供对许多系统管理操作的存取.
CAP_SYS_TTY_CONFIG
进行 tty 配置任务的能力.
2)能力的检查
<linux/capability.c>
int capable(int capability);
6.2. 阻塞 I/O
6.2.1. 睡眠的介绍
1:睡眠的规则:
1)当你运行在原子上下文时不能睡眠,即是你的驱动在持有一个自旋锁, seqlock, 或者 RCU 锁时不能睡眠.
2)如果你已关闭中断你也不能睡眠.
3)在持有一个旗标时睡眠是合法的, 但是你应当仔细查看这样做的任何代码. 如果代码在持有一个旗标时睡眠, 任何其他的等待这个旗标的线程也睡眠. 因此发生在持有旗标时的任何睡眠应当短暂, 并且你应当说服自己, 由于持有这个旗标, 你不能阻塞这个将最终唤醒你的进程
4)结果是你不能关于你醒后的系统状态做任何的假设, 并且你必须检查来确保你在等待的条件是, 确实, 真的.
5)一个另外的相关的点, 当然, 是你的进程不能睡眠除非确信其他人, 在某处的, 将唤醒它. 做唤醒工作的代码必须也能够找到你的进程来做它的工作.
在 Linux 中, 一个等待队列由一个"等待队列头"来管理, 一个 wait_queue_head_t 类型的结构, 定义在<linux/wait.h>中. 一个等待队列头可被定义和初始化, 使用:
DECLARE_WAIT_QUEUE_HEAD(name);
或者动态地, 如下:
wait_queue_head_t my_queue;
init_waitqueue_head(&my_queue);
6.2.2. 简单睡眠
<linux/wait.h>
wait_event(queue, condition)//不可中断地睡眠
wait_event_interruptible(queue, condition)//它可能被信号中断. 这个版本返回一个你应当检查的整数值; 一个非零值意味着你的睡眠被某些信号打断, 并且你的驱动可能应当返回 -ERESTARTSYS.
wait_event_timeout(queue, condition, timeout)
wait_event_interruptible_timeout(queue, condition, timeout)//
等待一段有限的时间; 在这个时间期间(以嘀哒数表达的, 我们将在第 7 章讨论)超时后, 这个宏返回一个 0 值而不管条件是如何求值的.
void wake_up(wait_queue_head_t *queue);
void wake_up_interruptible(wait_queue_head_t *queue);
//通常, 这 2 个是不用区分的
6.2.3. 阻塞和非阻塞操作
只有 read, write, 和 open 文件操作受到非阻塞标志影响.
受struct file flip,中filp->f_flags=0_NONBLOCK控制.
6.2.5. 高级睡眠
睡眠实现的原理:

第一步是创建和初始化一个等待队列. 这常常由这个宏定义完成:
DEFINE_WAIT(my_wait);
下一步是添加你的等待队列入口到队列, 并且设置进程状态. 2 个任务都由这个函数处理:
void prepare_to_wait(wait_queue_head_t *queue, wait_queue_t *wait, int state);
在调用 prepare_to_wait 之后, 进程可调用 schedule -- 在它已检查确认它仍然需要等待之后. 一旦 schedule 返回, 就到了清理时间. 这个任务, 也, 被一个特殊的函数处理:
void finish_wait(wait_queue_head_t *queue, wait_queue_t *wait);
6.2.5.3. 互斥等待

1)当一个等待队列入口有 WQ_FLAG_EXCLUSEVE 标志置位, 它被添加到等待队列的尾部. 没有这个标志的入口项, 相反, 添加到开始.
2)当 wake_up 被在一个等待队列上调用, 它在唤醒第一个有 WQ_FLAG_EXCLUSIVE 标志的进程后停止
6.3. poll 和 select
设备文件设备方法主要负责2步
1. 在一个或多个可指示查询状态变化的等待队列上调用 poll_wait. 如果没有文件描述符可用作 I/O, 内核使这个进程在等待队列上等待所有的传递给系统调用的文件描述符.
2. 返回一个位掩码, 描述可能不必阻塞就立刻进行的操作.
static unsigned int scull_p_poll(struct file *filp, poll_table *wait)
{
struct scull_pipe *dev = filp->private_data;
unsigned int mask = 0;
/*
* The buffer is circular; it is considered full
* if "wp" is right behind "rp" and empty if the
* two are equal.
*/
down(&dev->sem);
poll_wait(filp, &dev->inq, wait);
poll_wait(filp, &dev->outq, wait);
if (dev->rp != dev->wp)
mask |= POLLIN | POLLRDNORM; /* readable */
if (spacefree(dev))
mask |= POLLOUT | POLLWRNORM; /* writable */
up(&dev->sem);
return mask;
}
6.4. 异步通知
问题:
poll/select是查询方式,在低优先级上执行一个长计算循环, 但是需要尽可能快的处理输入数据,比较占CPU资源,
设备异步通知,效率高.
用户程序实现:
signal(SIGIO, &input_handler); /* dummy sample; sigaction() is better */
fcntl(STDIN_FILENO, F_SETOWN, getpid());//第一步:
oflags = fcntl(STDIN_FILENO, F_GETFL);
fcntl(STDIN_FILENO, F_SETFL, oflags | FASYNC);//第二步
第一步:它们指定一个进程作为文件的拥有者. 当一个进程使用 fcntl 系统调用发出 F_SETOWN 命令, 这个拥有者进程的 ID 被保存在 filp->f_owner 给以后使用. 这一步对内核知道通知谁是必要的.
第二步:用户程序必须设置 FASYNC 标志在设备中, 通过 F_SETFL fcntl 命令
注意, 但是, 不是所有的设备都支持异步通知, 并且你可选择不提供它. 应用程序常常假定异步能力只对 socket 和 tty 可用.
输入通知有一个剩下的问题. 当一个进程收到一个 SIGIO, 它不知道哪个输入文件有新数据提供. 如果多于一个文件被使能异步地通知挂起输入的进程, 应用程序必须仍然靠 poll 或者 select 来找出发生了什么.
驱动程序的实现:
1)int fasync_helper(int fd, struct file *filp, int mode, struct fasync_struct **fa);
//fasync_helper 被调用来从相关的进程列表中添加或去除入口项
2)void kill_fasync(struct fasync_struct **fa, int sig, int band);
//当数据到达时 kill_fasync 被用来通知相关的进程.
3)
当文件被关闭来从激活异步读者列表中去除文件.
示范代码:
1:
static int scull_p_fasync(int fd, struct file *filp, int mode)
{
struct scull_pipe *dev = filp->private_data;
return fasync_helper(fd, filp, mode, &dev->async_queue);
}
2:
if (dev->async_queue)
kill_fasync(&dev->async_queue, SIGIO, POLL_IN);
3:
/* remove this filp from the asynchronously notified filp's */
scull_p_fasync(-1, filp, 0);
6.5. 移位一个设备
loff_t scull_llseek(struct file *filp, loff_t off, int whence)
{
struct scull_dev *dev = filp->private_data;
loff_t newpos;
switch(whence)
{
case 0: /* SEEK_SET */
newpos = off;
break;
case 1: /* SEEK_CUR */
newpos = filp->f_pos + off;
break;
case 2: /* SEEK_END */
newpos = dev->size + off;
break;
default: /* can't happen */
return -EINVAL;
}
if (newpos < 0)
return -EINVAL;
filp->f_pos = newpos;
return newpos;
}
6.6. 在一个设备文件上的存取控制
6.6.1. 单 open 设备
提供存取控制的强力方式是只允许一个设备一次被一个进程打开(单次打开).
6.6.2. 一次对一个用户限制存取
单打开设备之外的下一步是使一个用户在多个进程中打开一个设备, 但是一次只允许一个用户打开设备
6.6.3. 阻塞 open 作为对 EBUSY 的替代
6.6.4. 在 open 时复制设备
第 7 章 时间, 延时, 和延后工作
7.1. 测量时间流失
7.1.1. 使用 jiffies 计数器
特点:精度低/可移植性好,更改精度在

函数:
#include <linux/jiffies.h>
int time_after(unsigned long a, unsigned long b);
int time_before(unsigned long a, unsigned long b);
int time_after_eq(unsigned long a, unsigned long b);
int time_before_eq(unsigned long a, unsigned long b);
#include <linux/time.h>
unsigned long timespec_to_jiffies(struct timespec *value);
void jiffies_to_timespec(unsigned long jiffies, struct timespec *value);
unsigned long timeval_to_jiffies(struct timeval *value);
void jiffies_to_timeval(unsigned long jiffies, struct timeval *value);
7.1.2. 处理器特定的寄存器/ TSC ( timestamp counter)
特点:精度高.但是与平台相关.
7.2. 获知当前时间
1)内核函数转变一个墙上时钟时间到一个 jiffies 值.
#include <linux/time.h>
unsigned long mktime (unsigned int year, unsigned int mon,unsigned int day, unsigned int hour, unsigned int min, unsigned int sec);
2)接近毫秒的精度
#include <linux/time.h>
void do_gettimeofday(struct timeval *tv);
7.3. 延后执行

7.3.1. 长延时
用线程做.
7.3.2. 短延时
用操作指令做.

7.4. 内核定时器
7.4.1. 定时器 API
1:内核定时器实际上是软中断.
2:中断上下文,必须遵守下列规则:
1):没有允许存取用户空间. 因为没有进程上下文, 没有和任何特定进程相关联的到用户空间的途径.
2):这个 current 指针在原子态没有意义, 并且不能使用因为相关的代码没有和已被中断的进程的联系.
3):不能进行睡眠或者调度. 原子代码不能调用 schedule 或者某种 wait_event, 也不能调用任何其他可能睡眠的函数. 例如, 调用 kmalloc(..., GFP_KERNEL) 是违犯规则的. 旗标也必须不能使用因为它们可能睡眠.
3)API:
#include <linux/timer.h>
struct timer_list
{
/* ... */
unsigned long expires;
void (*function)(unsigned long);
unsigned long data;
};
void init_timer(struct timer_list *timer);
struct timer_list TIMER_INITIALIZER(_function, _expires, _data);
void add_timer(struct timer_list * timer);
int del_timer(struct timer_list * timer);
int mod_timer(struct timer_list *timer, unsigned long expires);
int del_timer_sync(struct timer_list *timer);
int timer_pending(const struct timer_list * timer);
7.4.2. 内核定时器的实现
具体请参考kernerl/timer.c
7.5. Tasklets 机制
具体参kernel/softirq.c
tasklet 提供了许多有趣的特色:
1)一个 tasklet 能够被禁止并且之后被重新使能; 它不会执行直到它被使能与被禁止相同的的次数.
如同定时器, 一个 tasklet 可以注册它自己.
2)一个 tasklet 能被调度来执行以正常的优先级或者高优先级. 后一组一直是首先执行.
3)taslet 可能立刻运行, 如果系统不在重载下, 但是从不会晚于下一个时钟嘀哒.
4)一个 tasklet 可能和其他 tasklet 并发, 但是对它自己是严格地串行的 -- 同样的 tasklet 从不同时运行在超过一个处理器上. 同样, 如已经提到的, 一个 tasklet 常常在调度它的同一个 CPU 上运行.
tasklet的接口:
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data);
DECLARE_TASKLET(name, func, data);
DECLARE_TASKLET_DISABLED(name, func, data);
void tasklet_disable(struct tasklet_struct *t);
void tasklet_disable_nosync(struct tasklet_struct *t);
void tasklet_enable(struct tasklet_struct *t);
void tasklet_schedule(struct tasklet_struct *t);
void tasklet_hi_schedule(struct tasklet_struct *t);
void tasklet_kill(struct tasklet_struct *t);
7.6. 工作队列
tasklet 与workqueue区别:
1)tasklet 在软件中断上下文中运行的结果是所有的 tasklet 代码必须是原子的. 相反, 工作队列函数在一个特殊内核进程上下文运行; 结果, 它们有更多的灵活性. 特别地, 工作队列函数能够睡眠.
2)tasklet 常常在它们最初被提交的处理器上运行. 工作队列以相同地方式工作, 缺省地.
3)内核代码可以请求工作队列函数被延后一个明确的时间间隔.
linux/workqueue.h
工作队列的API:
//创建struct workqueue_struct
struct workqueue_struct *create_workqueue(const char *name);
struct workqueue_struct *create_singlethread_workqueue(const char *name);
//你需要填充一个 work_struct 结构
DECLARE_WORK(name, void (*function)(void *), void *data);
//
INIT_WORK(struct work_struct *work, void (*function)(void *), void *data);
PREPARE_WORK(struct work_struct *work, void (*function)(void *), void *data);
//
int queue_work(struct workqueue_struct *queue, struct work_struct *work);
int queue_delayed_work(struct workqueue_struct *queue, struct work_struct *work, unsigned long delay);
//
int cancel_delayed_work(struct work_struct *work);
//
void flush_workqueue(struct workqueue_struct *queue);
//
void destroy_workqueue(struct workqueue_struct *queue);
7.6.1. 共享队列
第 8 章 分配内存
8.1. 通用*kmalloc(size_t size, int flags)
8.1.1. flags 参数
#include <linux/slab.h>
void *kmalloc(size_t size, int flags);
經常用:
GFP_KERNEL:内核内存的正常分配. 可能睡眠.
GFP_ATOMIC:用来从中断处理和进程上下文之外的其他代码中分配内存. 从不睡眠
GFP_USER:用来为用户空间页来分配内存; 它可能睡眠
GFP_HIGHUSER:如同 GFP_USER, 但是从高端内存分配, 如果有. 高端内存在下一个子节描述
8.1.2. size 参数
1)程序员应当记住 kmalloc 能够处理的最小分配是 32 或者 64 字节
2)它不能指望可以分配任何大于 128 KB. 如果你需要多于几个 KB, 但是, 有个比 kmalloc 更好的方法来获得内存, 我们在本章后面描述
8.2. 后备缓存
内核经常分配许多大小相同的的对象,使用内存池/mempool,可以大大的提高效率.
1)
kmem_cache_t *kmem_cache_create(const char *name, size_t size,size_t offset,unsigned long flags,void (*constructor)(void *, kmem_cache_t *, unsigned long flags), void (*destructor)(void *, kmem_cache_t *, unsigned long flags));
void *kmem_cache_alloc(kmem_cache_t *cache, int flags);
void kmem_cache_free(kmem_cache_t *cache, const void *obj);
int kmem_cache_destroy(kmem_cache_t *cache);
2)mempool尽力一直保持一个空闲内存列表给紧急时使用.
mempool_t *mempool_create(int min_nr,mempool_alloc_t *alloc_fn,mempool_free_t *free_fn,void *pool_data);
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool);
int mempool_resize(mempool_t *pool, int new_min_nr, int gfp_mask);
void mempool_destroy(mempool_t *pool);
8.3. get_free_page 和其友
inlude/linux/gfp.h
要分配大块的内存的方法page
8.3.1.get_free_page

其中:gfp_mask:GFP_KERNEL,GFP_ATOMIC,GFP_DMA GFP_HIGHMEM
order 表示2n次方X 叶.如:10 表示 1024页.
8.3.2. alloc_pages 接口

nid:NUMA 节点ID.NUMA (非统一内存存取) 计算机是多处理器系统, 这里内存对于特定的处理器组("节点")是"局部的". 对局部内存的存取比存取非局部内存更快
8.3.3. vmalloc 和 其友

vmlloc它在虚拟内存空间分配一块连续的内存区. 尽管这些页在物理内存中不连续, 它与alloc_pages如何使用硬件上没有不同, 不同是在内核如何进行分配任务.
kmalloc 和 __get_free_pages 使用的(虚拟)地址范围特有一个一对一映射到物理内存, 可能移位一个常量 PAGE_OFFSET 值; 这些函数不需要给这个地址范围修改页表. vmalloc 和 ioremap 使用的
地址范围, 另一方面, 是完全地合成的, 并且每个分配建立(虚拟)内存区域, 通过适当地设置页表.
这个区别可以通过比较分配函数返回的指针来获知. 在一些平台(例如, x86), vmalloc 返回的地址只是远离 kmalloc 使用的地址. 在其他平台上(例如, MIPS, IA-64, 以及 x86_64 ), 它们属于一 个完全不同的地址范围. 对 vmalloc 可用的地址在从 VMALLOC_START 到 VAMLLOC_END 的范围中. 2 个符号都定义在 <asm/pgtable.h> 中.
vmalloc 分配的地址不能用于微处理器之外, 因为它们只在处理器的 MMU 之上才有意义. 当一个驱动需要一个真正的物理地址(例如一个 DMA 地址, 被外设硬件用来驱动系统的总线), 你无法轻易使用 vmalloc. 调用 vmalloc 的正确时机是当你在为一个大的只存在于软件中的顺序缓冲分配内存时. 重要的是注意 vamlloc 比 __get_free_pages 有更多开销, 因为它必须获取内存并且建立页表. 因此, 调用 vmalloc 来分配仅仅一页是无意义的.
在内核中使用 vmalloc 的一个例子函数是 create_module 系统调用, 它使用 vmalloc 为在创建的模块获得空间. 模块的代码和数据之后被拷贝到分配的空间中, 使用 copy_from_user. 在这个方式中, 模块看来是加载到连续的内存. 你可以验证, 同过看 /proc/kallsyms, 模块输出的内核符号位于一个不同于内核自身输出的符号的内存范围.
使用 vmalloc 分配的内存由 vfree 释放, 采用和 kfree 释放由 kmalloc 分配的内存的相同方式.
如同 vmalloc, ioremap 建立新页表; 不同于 vmalloc, 但是, 它实际上不分配任何内存. ioremap 的返回值是一个特殊的虚拟地址可用来存取特定的物理地址范围; 获得的虚拟地址应当最终通过调用 iounmap 来释放.
ioremap 和 vmalloc 是面向页的(它通过修改页表来工作); 结果, 重分配的或者分配的大小被调整到最近的页边界. ioremap 模拟一个非对齐的映射通过"向下调整"被重映射的地址以及通过返回第一个被重映射页内的偏移.
vmalloc 的一个小的缺点在于它无法在原子上下文中使用, 因为, 内部地, 它使用 kmalloc(GFP_KERNEL) 来获取页表的存储, 并且因此可能睡眠. 这不应当是一个问题 -- 如果 __get_free_page 的使用对于一个中断处理不足够好, 软件设计需要一些清理
8.4. 每-CPU 的变量
含义:当你创建一个每-CPU变量, 系统中每个处理器获得它自己的这个变量拷贝. 这个可能象一个想做的奇怪的事情, 但是它有自己的优点. 存取每-CPU变量不需要(几乎)加锁, 因为每个处理器使用它自己的拷贝. 每-CPU 变量也可存在于它们各自的处理器缓存中, 这样对于频繁更新的量子带来了显著的更好性能.
<linux/percpu.h>
8.4.1:声明:

8.4.2;如果是抢占CPU 在修改一个每-CPU变量的临界区中不应当被抢占,如2.6.使用如下方法来加锁操作.

get_cpu_var(sockets_in_use)++;
put_cpu_var(sockets_in_use);
per_cpu(variable, int cpu_id);
8.4.3.动态分配每-CPU变量
void *alloc_percpu(type);
void *__alloc_percpu(size_t size, size_t align);
free_percpu (Void __percpu *pdata)
per_cpu_ptr(void *per_cpu_var, int cpu_id);
8.4.4:每-CPU 的变量的封装.
如果你想使用每-CPU变量来创建一个简单的整数计数器, 看一下在 <linux/percpu_counter.h> 中的现成的实现. 最后, 注意一些体系有有限数量的地址空间变量给每-CPU变量. 如果你创建每-CPU变量在你自己的代码, 你应当尽量使它们小.

8.5. 获得大量缓冲
第 9 章 与硬件通讯
9.1. I/O 端口和 I/O 内存
I/O 端口:
一些 CPU 制造商在他们的芯片上实现了一个单个地址空间, 有人认为外设不同于内存, 因此, 应该有一个分开的地址空间. 一些处理器(最有名的是 x86 家族)有分开的读和写电线给 I/O 端口和特殊的 CPU 指令来存取端口.
一些 CPU 制造商,即便那些没有单独地址空间给 I/O 端口的处理器, 也必须在存取一些特殊设备时伪装读写端口.
注意即便外设总线有一个单独的地址空间给 I/O 端口, 不是所有的设备映射它们的寄存器到 I/O 端口,
映射设备寄存器到一个内存地址区I/O 内存
9.1.1. I/O 寄存器和常规内存
不管硬件寄存器和内存之间的强相似性, 存取 I/O 寄存器的程序员必须小心避免被 CPU(或者编译器)优化所戏弄, 它可能修改希望的 I/O 行为.
主要差异:I/O 寄存器和 RAM 的主要不同是 I/O 操作有边际效果, 而内存操作没有(值被缓存,并且 读/写指令被重编排)
因此, 一个驱动必须确保没有进行缓冲并且在存取寄存器时没有发生读或写的重编排.
解决办法:
1)硬件缓冲的问题是最易面对的:底层的硬件已经配置(或者自动地或者通过 Linux 初始化代码)成禁止任何硬件缓冲, 当存取 I/O 区时(不管它们是内存还是端口区域).
2)对编译器优化和硬件重编排的解决方法是安放一个内存屏障在必须以一个特殊顺序对硬件(或者另一个处理器)可见的操作之间. Linux 提供 4 个宏来应对可能的排序需要:
#include <linux/kernel.h>
void barrier(void)
这个函数告知编译器插入一个内存屏障但是对硬件没有影响. 编译的代码将所有的当前改变的并且驻留在 CPU 寄存器的值存储到内存, 并且后来重新读取它们当需要时. 对屏障的调用阻止编译器跨越屏障的优化, 而留给硬件自由做它的重编排.
#include <asm/system.h>
void rmb(void);
void read_barrier_depends(void);
void wmb(void);
void mb(void);
这些函数插入硬件内存屏障在编译的指令流中; 它们的实际实例是平台相关的. 一个 rmb ( read memory barrier) 保证任何出现于屏障前的读在执行任何后续读之前完成. wmb 保证写操作中的顺序, 并且 mb 指令都保证. 每个这些指令是一个屏障的超集.
void smp_rmb(void);
void smp_read_barrier_depends(void);
void smp_wmb(void);
void smp_mb(void);
屏障的这些版本仅当内核为 SMP 系统编译时插入硬件屏障; 否则, 它们都扩展为一个简单的屏障调用.
9.2. 使用 I/O 端口
9.2.1. I/O 端口分配
#include <linux/ioport.h>
struct resource *request_region(unsigned long first, unsigned long n, const char *name);
void release_region(unsigned long start, unsigned long n);
int check_region(unsigned long first, unsigned long n);
9.2.2. 操作 I/O 端口
#include <arm-generic/io.h>
unsigned inb(unsigned port);
void outb(unsigned char byte, unsigned port);
unsigned inw(unsigned port);
void outw(unsigned short word, unsigned port);
unsigned inl(unsigned port);
void outl(unsigned longword, unsigned port);
9.2.3. 从用户空间的 I/O 存取
<sys/io.h>
1):程序必须使用 -O 选项编译来强制扩展内联函数.
2):ioperm 和 iopl 系统调用必须用来获得权限来进行对端口的 I/O 操作. ioperm 为单独端口获取许可, 而 iopl 为整个 I/O 空间获取许可. 这 2 个函数都是 x86 特有的.
3):程序必须作为 root 来调用 ioperm 或者 iopl.[34] 可选地, 一个它的祖先必须已赢得作为 root 运行的端口权限.
9.2.4. 字串操作
void insb(unsigned port, void *addr, unsigned long count);
void outsb(unsigned port, void *addr, unsigned long count);
void insw(unsigned port, void *addr, unsigned long count);
void outsw(unsigned port, void *addr, unsigned long count);
void insl(unsigned port, void *addr, unsigned long count);
void outsl(unsigned port, void *addr, unsigned long count);
9.2.5. 暂停 I/O
9.2.6. 平台依赖性
9.3. 一个 I/O 端口例子
9.4. 使用 I/O 内存
9.4.1. I/O 内存分配和映射
<linux/ioport.h>
struct resource *request_mem_region(unsigned long start, unsigned long len, char *name);
void release_mem_region(unsigned long start, unsigned long len);
int check_mem_region(unsigned long start, unsigned long len);
在存取内存之前, 分配 I/O 内嵌不是唯一的要求的步骤. 你必须也保证这个 I/O 内存已经对内核是可存取的. 使用 I/O 内存不只是解引用一个指针的事情; 在许多系统, I/O 内存根本不是可以这种方式直接存取的. 因此必须首先设置一个映射. 这是 ioremap 函数的功能, 在第 1 章的 "vmalloc 及其友"一节中介绍的. 这个函数设计来特别的安排虚拟地址给 I/O 内存区.
一旦装备了 ioremap (和iounmap), 一个设备驱动可以存取任何 I/O 内存地址, 不管是否它是直接映射到虚拟地址空间. 记住, 但是, 从 ioremap 返回的地址不应当直接解引用; 相反, 应当使用内核提供的存取函数. 在我们进入这些函数之前, 我们最好回顾一下 ioremap 原型和介绍几个我们在前一章略过的细节.
9.4.2. 存取 I/O 内存
unsigned int ioread8(void *addr);
unsigned int ioread16(void *addr);
unsigned int ioread32(void *addr);
void iowrite8(u8 value, void *addr);
void iowrite16(u16 value, void *addr);
void iowrite32(u32 value, void *addr);
void ioread8_rep(void *addr, void *buf, unsigned long count);
void ioread16_rep(void *addr, void *buf, unsigned long count);
void ioread32_rep(void *addr, void *buf, unsigned long count);
void iowrite8_rep(void *addr, const void *buf, unsigned long count);
void iowrite16_rep(void *addr, const void *buf, unsigned long count);
void iowrite32_rep(void *addr, const void *buf, unsigned long count);
9.4.3. 作为 I/O 内存的端口
void *ioport_map(unsigned long port, unsigned int count);
void ioport_unmap(void *addr);
第10章 中断处理
10.1. 准备并口
10.2. 安装一个中断处理
10.2.1 请求一个中断:
<linux/interrupt.h>
1)参数解析:
unsigned int irq
请求的中断号
irqreturn_t (*handler)
安装的处理函数指针.
unsigned long flags
flags 中可以设置的位如下:
SA_INTERRUPT
当置位了, 这表示一个"快速"中断处理. 快速处理在当前处理器上禁止中断来执行
SA_SHIRQ
这个位表示中断可以在设备间共享
SA_SAMPLE_RANDOM
这个位表示产生的中断能够有贡献给 /dev/random 和 /dev/urandom 使用的加密池.
const char *dev_name
这个传递给 request_irq 的字串用在 /proc/interrupts 来显示中断的拥有者(下一节看到)
void *dev_id
用作共享中断线的指针.
2)查看中断, /proc/interrupts和/proc/stat

10.2.2.IRQ号的设置.
1:程序员指定,设备可移植性差.
2:自动检测 IRQ 号
驱动获取中断号通过从设备的一个 I/O 端口或者 PCI 配置空间读一个状态字节
1)内核协助的探测

unsigned long probe_irq_on(void);
这个函数返回一个未安排的中断的位掩码. 驱动必须保留返回的位掩码, 并且在后面传递给 probe_irq_off. 在这个调用之后, 驱动应当安排它的设备产生至少一次中断.
int probe_irq_off(unsigned long);
在设备已请求一个中断后, 驱动调用这个函数, 作为参数传递之前由 probe_irq_on 返回的位掩码. probe_irq_off 返回在"probe_on"之后发出的中断号. 如果没有中断发生, 返回 0 (因此, IRQ 0 不能探测, 但是没有用户设备能够在任何支持的体系上使用它). 如果多于一个中断发生( 模糊的探测 ), probe_irq_off 返回一个负值.
2)Do-it-yourself 探测
10.2.3. 快速和慢速处理
flags =SA_INTERRUPT
现代内核快速和慢速中断不同:
快速中断(那些使用 SA_INTERRUPT 被请求的)执行时禁止所有在当前处理器上的其他中断. 注意其他的处理器仍然能够处理中断, 尽管你从不会看到 2 个处理器同时处理同一个 IRQ.
10.2.3.1. ARM上中断处理的内幕
do_IRQ 做的第一件事是确认中断以便中断控制器能够继续其他事情. 它接着获取给定 IRQ 号的一个自旋锁, 因此阻止任何其他 CPU 处理这个 IRQ. 它清除几个状态位(包括称为 IRQ_WAITING 的一个, 我们很快会看到它)并且接着查看这个特殊 IRQ 的处理者. 如果没有处理者, 什么不作; 自旋锁释放, 任何挂起的软件中断被处理, 最后 do_IRQ 返回.
常常, 但是, 如果一个设备在中断, 至少也有一个处理者注册给它的 IRQ. 函数 handle_IRQ_event 被调用来实际调用处理者. 如果处理者是慢速的( SA_INTERRUPT 没有设置 ), 中断在硬件中被重新使能, 并且调用处理者. 接着仅仅是清理, 运行软件中断, 以及回到正常的工作. "常规工作"很可能已经由于中断而改变了(处理者可能唤醒一个进程, 例如), 因此从中断中返回的最后的事情是一个处理器的可能的重新调度.
探测 IRQ 通过设置 IRQ_WAITING 状态位给每个当前缺乏处理者的 IRQ 来完成. 当中断发生, do_IRQ 清除这个位并且接着返回, 因为没有注册处理者. probe_irq_off, 当被一个函数调用, 需要只搜索不再有 IRQ_WAITING 设置的 IRQ.
10.2.4. 实现一个处理/irqreturn_t (*handler)
中断处理函数一些限制/原则:
1)不能传递数据到或者从用户空间,
2)因为它不在进程上下文执行. 处理者也不能做任何可能睡眠的事情, 例如调用 wait_event, 使用除 GFP_ATOMIC 之外任何东西来分配内存, 或者加锁一个旗标.
3)处理者不能调用调度.
序员应当小心编写一个函数在最小量的时间内执行, 不管是一个快速或慢速处理者. 如果需要进行长时间计算, 最好的方法是使用一个 tasklet 或者 workqueue 来调度计算在一个更安全的时间(我们将在"上和下半部"一节中见到工作如何被延迟.).
10.2.5. 处理者的参数和返回值/irqreturn_t (*handler)
10.2.6. 使能和禁止中断
10.2.6.1. 禁止单个中断
<linux/interrupt.h>
void disable_irq(int irq);
void disable_irq_nosync(int irq);
void enable_irq(int irq);
10.2.6.2. 禁止所有中断
<linux/irqflag.h>
void local_irq_save(unsigned long flags);
void local_irq_restore(unsigned long flags);
// local_irq_save 的调用在当前处理器上禁止中断递交, 在保存当前中断状态到 flags 之后
void local_irq_disable(void);
void local_irq_enable(void);
//local_irq_disable 关闭本地中断递交而不保存状态
10.3. 前和后半部
前半部:实际响应中断的函数,request_irq 注册的那个,即中断回调函数
后半部:由前半部调度来延后执行的函数.
后半部解决方案Tasklet/workquenue
10.3.1. Tasklet 实现
1)先声明:
void short_do_tasklet(unsigned long);
DECLARE_TASKLET(short_tasklet, short_do_tasklet, 0);
2)在前半部call tasklet_schedule(&short_tasklet);来调度.
irqreturn_t short_tl_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
do_gettimeofday((struct timeval *) tv_head); /* cast to stop 'volatile' warning
*/
short_incr_tv(&tv_head);
tasklet_schedule(&short_tasklet);
short_wq_count++; /* record that an interrupt arrived */
return IRQ_HANDLED;
}
3)实现后半部
void short_do_tasklet (unsigned long unused)
{
int savecount = short_wq_count, written;
short_wq_count = 0; /* we have already been removed from the queue */
/*
* The bottom half reads the tv array, filled by the top half,
* and prints it to the circular text buffer, which is then consumed
* by reading processes */
/* First write the number of interrupts that occurred before this bh */
written = sprintf((char *)short_head,"bh after %6i\n",savecount);
short_incr_bp(&short_head, written);
/*
* Then, write the time values. Write exactly 16 bytes at a time,
* so it aligns with PAGE_SIZE */
do {
written = sprintf((char *)short_head,"%08u.%06u\n",
(int)(tv_tail->tv_sec % 100000000),
(int)(tv_tail->tv_usec));
short_incr_bp(&short_head, written);
short_incr_tv(&tv_tail);
} while (tv_tail != tv_head);
wake_up_interruptible(&short_queue); /* awake any reading process */
}
10.3.2. 工作队列//可以睡眠.可以自己实现,一个特定的工作队列.
1)先声明:
static struct work_struct short_wq;
/* this line is in short_init() */
INIT_WORK(&short_wq, (void (*)(void *)) short_do_tasklet, NULL);
2)在前半部call schedule_work(&short_wq);;来调度.
irqreturn_t short_wq_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
/* Grab the current time information. */
do_gettimeofday((struct timeval *) tv_head);
short_incr_tv(&tv_head);
/* Queue the bh. Don't worry about multiple enqueueing */
schedule_work(&short_wq);
short_wq_count++; /* record that an interrupt arrived */
return IRQ_HANDLED;
}
3)实现后半部
10.4. 中断共享
10.4.1. 安装一个共享的处理者
共享中断通过 request_irq 来安装就像不共享的一样, 但是有 2 个不同:
1.SA_SHIRQ 位必须在 flags 参数中指定, 当请求中断时.
2.dev_id 参数必须是独特的. 任何模块地址空间的指针都行, 但是 dev_id 明确地不能设置为 NULL
当请求一个共享的中断, request_irq 成功, 如果下列之一是真
1.中断线空闲.
2.所有这条线的已经注册的处理者也指定共享这个 IRQ
一个使用共享处理者的驱动需要小心多一件事: 它不能使用 enable_irq 或者 disable_irq.
10.4.2. 运行处理者
10.4.3. /proc 接口和共享中断
在系统中安装共享处理者不影响 /proc/stat, 它甚至不知道处理者. 但是, /proc/interrupts 稍稍变化.
10.5. 中断驱动 I/O
10.5.1. 一个写缓存例子
第11章 内核中的数据类型
数据类型分为 3 个主要类型
1.标准 C 类型例如 int
2.明确大小的类型例如 u32
3.以及用作特定内核对象的类型, 例如 pid_t.
11.1. 标准 C 类型的使用
misc-progs 目录可以查看各种体系datesize.
11.2. 安排一个明确大小给数据项
11.3. 接口特定的类型
11.4. 其他移植性问题
11.4.1. 时间间隔
使用HZ宏定义.

11.4.2. 页大小
PAGE_SIZE 不一定是4K,如何在跨系统,得到一个指定大小页的内存:
#include <asm/page.h>
int order = get_order(16*1024);
buf = get_free_pages(GFP_KERNEL, order);
11.4.3. 字节序
方法:1:编译开关包含文件 <asm/byteorder.h> 定义了或者 __BIG_ENDIAN 或者 __LITTLE_ENDIAN
2:宏定义:

11.4.4. 数据对齐
(1)解决办法#include <asm/unaligned.h>

(2)如果不需要对齐,告诉编译器这个结构必须是"紧凑的", 不能增加填充者,在变量前加__attribute__ ((packed)),
11.4.5. 指针和错误值
<linux/err.h>
一个返回指针类型的函数可以返回一个错误值, 使用:

void *ERR_PTR(long error);
这里, error 是常见的负值错误码. 调用者可用使用 IS_ERR 来测试是否一个返回的指针是不是一个错误码:
long IS_ERR(const void *ptr);
如果你需要实际的错误码, 它可能被抽取到, 使用:
long PTR_ERR(const void *ptr);
11.5. 链表
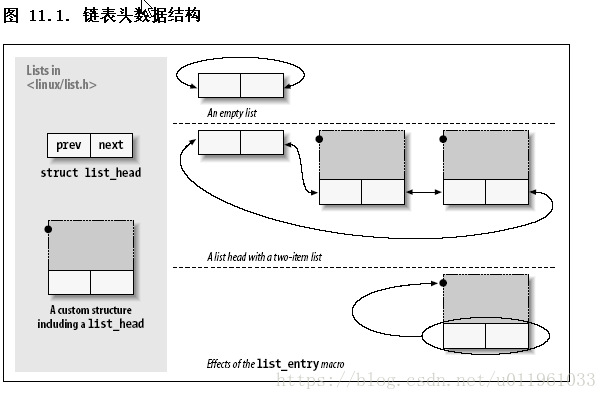
1)声明与初始化:
struct list_head todo_list;
INIT_LIST_HEAD(&todo_list);
或LIST_HEAD(todo_list);
2)链表的操作.
list_add(struct list_head *new, struct list_head *head);
在紧接着链表 head 后面增加新入口项 -- 正常地在链表的开头. 因此, 它可用来构建堆栈. 但是, 注意, head 不需要是链表名义上的头; 如果你传递一个 list_head 结构, 它在链表某处的中间, 新的项紧靠在它后面. 因为 Linux 链表是环形的, 链表的头通常和任何其他的项没有区别.
list_add_tail(struct list_head *new, struct list_head *head);
刚好在给定链表头前面增加一个新入口项 -- 在链表的尾部, 换句话说. list_add_tail 能够, 因此, 用来构建先入先出队列.
list_del(struct list_head *entry);
list_del_init(struct list_head *entry);
给定的项从队列中去除. 如果入口项可能注册在另外的链表中, 你应当使用 list_del_init, 它重新初始化这个链表指针.
list_move(struct list_head *entry, struct list_head *head);
list_move_tail(struct list_head *entry, struct list_head *head);
给定的入口项从它当前的链表里去除并且增加到 head 的开始. 为安放入口项在新链表的末尾, 使用 list_move_tail 代替.
list_empty(struct list_head *head);
如果给定链表是空, 返回一个非零值.
list_splice(struct list_head *list, struct list_head *head);
将 list 紧接在 head 之后来连接 2 个链表
list_entry(struct list_head *ptr, type_of_struct, field_name);
这里 ptr 是一个指向使用的 struct list_head 的指针, type_of_struct 是包含 ptr 的结构的类型, field_name 是结构中列表成员的名子. 在我们之前的 todo_struct 结构中, 链表成员称为简单列表. 因此, 我们应当转变一个列表入口项为它的包含结构, 使用这样一行:
3)链表的遍历
list_for_each(struct list_head *cursor, struct list_head *list)
这个宏创建一个 for 循环, 执行一次, cursor 指向链表中的每个连续的入口项. 小心改变列表在遍历它时.
list_for_each_prev(struct list_head *cursor, struct list_head *list)
这个版本后向遍历链表.
list_for_each_safe(struct list_head *cursor, struct list_head *next, struct list_head *list)
如果你的循环可能删除列表中的项, 使用这个版本. 它简单的存储列表 next 中下一个项, 在循环的开始, 因此如果 cursor 指向的入口项被删除, 它不会被搞乱.
list_for_each_entry(type *cursor, struct list_head *list, member)
list_for_each_entry_safe(type *cursor, type *next, struct list_head *list, member)
这些宏定义减轻了对一个包含给定结构类型的列表的处理. 这里, cursor 是一个指向包含数据类型的指针, member 是包含结构中 list_head 结构的名子. 有了这些宏, 没有必要安放 list_entry 调用在循环里
第 13 章 USB 驱动
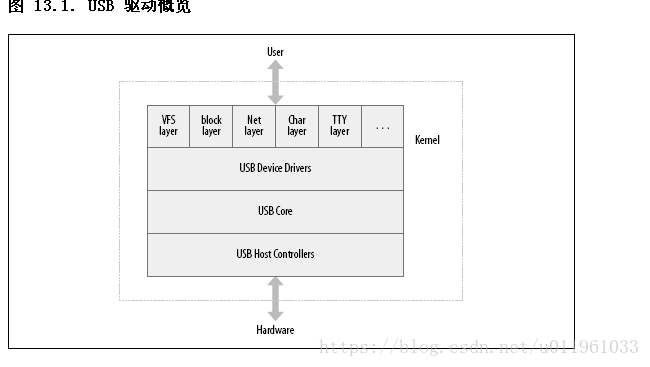
USB 驱动位于不同的内核子系统(块, 网络, 字符, 等等)和硬件控制器之间. USB 核心提供了一个接口给 USB 驱动用来存取和控制 USB 硬件, 而不必担心出现在系统中的不同的 USB 硬件控制器.
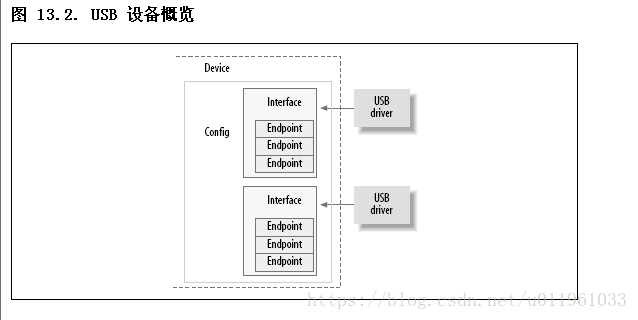
USB 设备如何包含配置, 接口, 和端点, 以及 USB 驱动如何绑定到 USB 接口
Linux 内核支持 2 类 USB 驱动
1)位于主机系统的驱动:控制插入其中的 USB 设备
2)位于设备的驱动(USB 器件驱动):控制单个设备如何作为一个 USB 设备
13.1. USB 设备基础知识
13.1.1. 端点/Endpoint
4 种不同类型的
1)CONTROL
2)INTERRUPT
3)BULK
4)ISOCHRONOUS
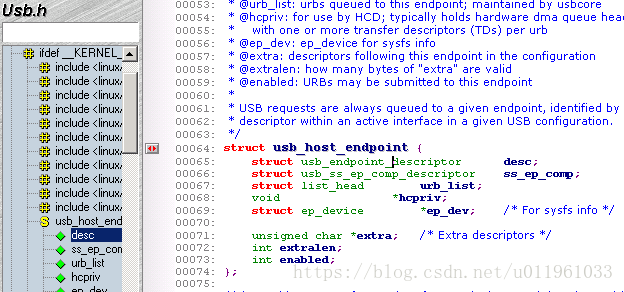
对应的结构体struct usb_host_endpoint 中 struct usb_endpoint_descriptor

关键成员:
bEndpointAddress :这是这个特定端点的 USB 地址. 还包含在这个 8-位 值的是端点的方向. 位掩码 USB_DIR_OUT 和 USB_DIR_IN 可用来和这个成员比对
bmAttributes :这是端点的类型. 位掩码 USB_ENDPOINT_XFERTYPE_MASK 应当用来和这个值比对, 来决定这个端点是否是 USB_ENDPOINT_XFER_ISOC, USB_ENDPOINT_XFER_BULK, 或者是类型 USB_ENDPOINT_XFER_INT. 这些宏定义了同步, 块, 和中断端点, 相应地
wMaxPacketSize:这是以字节计的这个端点可一次处理的最大大小. 注意驱动可能发送大量的比这个值大的数据到端点, 但是数据会被分为 wMaxPakcetSize 的块, 当真正传送到设备时. 对于高速设备, 这个成员可用来支持端点的一个高带宽模式, 通过使用几个额外位在这个值的高位部分. 关于如何完成的细节见 USB 规范
bInterval:如果这个端点是中断类型的, 这个值是为这个端点设置的间隔, 即在请求端点的中断之间的时间. 这个值以毫秒表示
13.1.2. 接口/Inteface
对应struct usb_interface
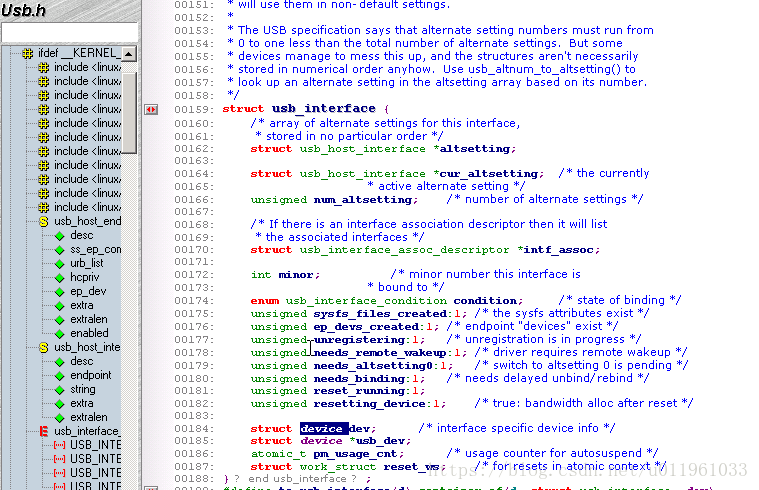
关键成员:
struct usb_host_interface *altsetting
一个包含所有预备设置的接口结构的数组, 可被挑选给这个接口. 每个 struct usb_host_interface 包含一套端点配置, 如同由 struct usb_host_endpoint 结构所定义的. 注意这些接口结构没有特别的顺序.
unsigned num_altsetting
由 altsetting 指针指向的预备设置的数目.
struct usb_host_interface *cur_altsetting
指向数组 altsetting 的一个指针, 表示这个接口当前的激活的设置.
int minor
如果绑定到这个接口的 USB 驱动使用 USB 主编号, 这个变量包含由 USB 核心安排给接口的次编号. 这只在一次成功地调用 usb_register_dev (本章稍后描述)之后才有效.
13.1.3. 配置/config
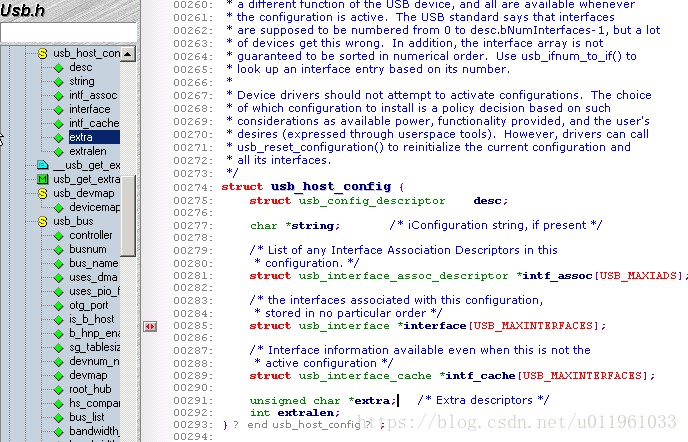
所以总结, USB 设备是非常复杂的, 并且由许多不同逻辑单元组成. 这些单元之间的关系可简单地描述如下:
设备通常有一个或多个配置.
配置常常有一个或多个接口
接口常常有一个或多个设置.
接口有零或多个端点
13.2. USB 和 sysfs
13.3. USB 的 Urbs
linux 内核中的 USB 代码和所有的 USB 设备通讯使用称为 urb 的东西( USB request block)

13.3.1 URB 概述
urb 的典型生命循环
1)被一个 USB 设备驱动创建.
2)安排给一个特定 USB 设备的特定端点.
3)提交给 USB 核心, 被 USB 设备驱动.
4)提交给特定设备的被 USB 核心指定的 USB 主机控制器驱动, .
5)被 USB 主机控制器处理, 它做一个 USB 传送到设备.
6)当 urb 完成, USB 主机控制器驱动通知 USB 设备驱动.
关键成员:
struct usb_device *dev
//指向这个 urb 要发送到的 struct usb_device 的指针
unsigned int pipe:
//端点消息,设置endpoint为4种不同类型.
unsigned int transfer_flags :
//可被设置为不同位值, 根据这个 USB 驱动想这个 urb 发生什么
URB_SHORT_NOT_OK
URB_ISO_ASAP
URB_NO_TRANSFER_DMA_MAP
URB_NO_SETUP_DMA_MAP
URB_ASYNC_UNLINK
URB_NO_FSBR
URB_ZERO_PACKET
URB_NO_INTERRUPT
void *transfer_buffer
//指向用在发送数据到设备(对一个 OUT urb)或者从设备中获取数据(对于一个 IN urb)的缓冲的指针
dma_addr_t transfer_dma
//用来使用 DMA 传送数据到 USB 设备的缓冲.
int transfer_buffer_length
//缓冲的长度
unsigned char *setup_packet
//指向给一个控制 urb 的 setup 报文的指针
dma_addr_t setup_dma
//给控制 urb 的 setupt 报文的 DMA 缓冲.
usb_complete_t complete
//指向完成处理者函数的指针, 它被 USB 核心调用当这个 urb 被完全传送或者当 urb 发生一个错误. 在这个函数中, USB 驱动可检查这个 urb, 释放它, 或者重新提交它给另一次传送.(
void *context
//指向数据点的指针, 它可被 USB 驱动设置.
int actual_length
//当这个 urb 被完成, 这个变量被设置为数据的真实长度, 或者由这个 urb (对于 OUT urb)发送或者由这个 urb(对于 IN urb)接受.
int status
//当这个 urb 被结束, 或者开始由 USB 核心处理, 这个变量被设置为 urb 的当前状态.
int start_frame
//设置或返回同步传送要使用的初始帧号.
int interval
//urb 被轮询的间隔. 这只对中断或者同步 urb 有效.
int number_of_packets
//只对同步 urb 有效, 并且指定这个 urb 要处理的同步传送缓冲的编号.
int error_count
//被 USB 核心设置, 只给同步 urb 在它们完成之后. 它指定报告任何类型错误的同步传送的号码
struct usb_iso_packet_descriptor iso_frame_desc[0]
//单个 urb 来一次定义多个同步传送. 它也用来收集每个单独传送的传送状态.
13.3.2 URB 实现
创建和销毁 urb
struct urb *usb_alloc_urb(int iso_packets, int mem_flags);
void usb_free_urb(struct urb *urb);
初始化成4种类型;
13.3.2.1. 中断 urb
void usb_fill_int_urb(struct urb *urb, struct usb_device *dev,unsigned int pipe, void *transfer_buffer,int buffer_length, usb_complete_t complete,void *context, int interval);
13.3.2.2. 块 urb
void usb_fill_bulk_urb(struct urb *urb, struct usb_device *dev,unsigned int pipe, void *transfer_buffer,int buffer_length, usb_complete_t complete,void *context);
13.3.2.3. 控制 urb
void usb_fill_control_urb(struct urb *urb, struct usb_device *dev,unsigned int pipe, unsigned char *setup_packet, void *transfer_buffer, int buffer_length, usb_complete_t complete, void *context);
13.3.2.4. 同步 urb
没有初始化函数,可以参考 drivers/usb/media 中konicawc.c 使用.
提交 urb
int usb_submit_urb(struct urb *urb, int mem_flags);
取消 urb
int usb_kill_urb(struct urb *urb);
int usb_unlink_urb(struct urb *urb);
完成 urb:
完成回调处理者:
如果函数成功, urb 的完成处理者(如同被完成函数指针指定的)被确切地调用一次, 当 urb 被完成. 当这个函数被调用, USB 核心完成这个 urb, 并且对它的控制现在返回给设备驱动.
13.4. 编写一个 USB 驱动
13.4.1. 驱动支持什么设备
1)include\linux下的 mod_devicetable.c结构体

关键成员:
__u16 match_flags
决定设备应当匹配结构中下列的哪个成员. 这是一个位成员, 由在 include/linux/mod_devicetable.h 文件中指定的不同的 USB_DEVICE_ID_MATCH_* 值所定义. 这个成员常常从不直接设置, 但是由 USB_DEVICE 类型宏来初始化.
__u16 idVendor
这个设备的 USB 供应商 ID. 这个数由 USB 论坛分配给它的成员并且不能由任何别的构成.
__u16 idProduct
这个设备的 USB 产品 ID. 所有的有分配给他们的供应商 ID 的供应商可以随意管理它们的产品 ID.
__u16 bcdDevice_lo
__u16 bcdDevice_hi
定义供应商分配的产品版本号的高低范围. bcdDevice_hi 值包括其中; 它的值是最高编号的设备号. 这 2 个值以BCD 方式编码. 这些变量, 连同 idVendor 和 idProduct, 用来定义一个特定的设备版本.
__u8 bDeviceClass
__u8 bDeviceSubClass
__u8 bDeviceProtocol
定义类, 子类, 和设备协议, 分别地. 这些值被 USB 论坛分配并且定义在 USB 规范中. 这些值指定这个设备的行为, 包括设备上所有的接口.
__u8 bInterfaceClass
__u8 bInterfaceSubClass
__u8 bInterfaceProtocol
非常象上面的设备特定值, 这些定义了类, 子类, 和单个接口协议, 分别地. 这些值由 USB 论坛指定并且定义在 USB 规范中.
kernel_ulong_t driver_info
这个值不用来匹配, 但是它持有信息, 驱动可用来在 USB 驱动的探测回调函数区分不同的设备.
对于一个简单的 USB 设备驱动, 只控制来自一个供应商的一个单一 USB 设备, struct usb_device_id 表可定义如:
/* table of devices that work with this driver */
static struct usb_device_id skel_table [] = {
{ USB_DEVICE(USB_SKEL_VENDOR_ID, USB_SKEL_PRODUCT_ID) },
{ } /* Terminating entry */
};
MODULE_DEVICE_TABLE (usb, skel_table);
2)struct usb_driver

关键成员:
struct module *owner
const char *name
const struct usb_device_id *id_table
//指向 struct usb_device_id 表的指针, 包含这个驱动可接受的所有不同类型 USB 设备的列表. 如果这个变量没被设置, USB 驱动中的探测回调函数不会被调用. 如果你需要你的驱动给系统中每个 USB 设备一直被调用, 创建一个只设置这个 driver_info 成员的入口项:
static struct usb_device_id usb_ids[] = {
{.driver_info = 42},
{}
};
int (*probe) (struct usb_interface *intf, const struct usb_device_id *id)
//指向 USB 驱动中探测函数的指针. 这个函数(在"探测和去连接的细节"一节中描述)被 USB 核心调用当它认为它有一个这个驱动可处理的 struct usb_interface. 一个指向 USB 核心用来做决定的 struct usb_device_id 的指针也被传递到这个函数. 如果这个 USB 驱动主张传递给它的 struct usb_interface, 它应当正确地初始化设备并且返回 0. 如果驱动不想主张这个设备, 或者发生一个错误, 它应当返回一个负错误值.
//探测函数被调用, 当设备被安装时, USB 核心认为这个驱动应当处理; 探测函数应当进行检查传递给它的关于设备的信息, 并且决定是否驱动真正合适那个设备.在探测函数回调中,
(1)USB 驱动应当初始化任何它可能使用来管理 USB 设备的本地结构. 它还应当保存任何它需要的关于设备的信息到本地结构,即interface 结构的初始化.usb_set_intfdata(interface, dev);
/ usb_get_intfdata(interface);
(2)call usb_register_dev(interface, &skel_class);来注册设备.
void (*disconnect) (struct usb_interface *intf)
//当驱动应当不再控制设备
13.4.2. 注册一个 USB 驱动
(1)为创建一个值 struct usb_driver 结构
static struct usb_driver skel_driver = {
.owner = THIS_MODULE,
.name = "skeleton",
.id_table = skel_table,
.probe = skel_probe,
.disconnect = skel_disconnect,
};
(2)调用 usb_register_driver 带一个指向 struct usb_driver 的指针. 传统上在 USB 驱动的模块初始化代码做这个:
static int __init usb_skel_init(void)
{
int result;
/* register this driver with the USB subsystem */
result = usb_register(&skel_driver);
if (result)
err("usb_register failed. Error number %d", result);
return result;
}
(3)当 USB 驱动被卸载, struct usb_driver 需要从内核注销
static void __exit usb_skel_exit(void)
{
/* deregister this driver with the USB subsystem */
usb_deregister(&skel_driver);
}
13.4.3. 探测和去连接的细节// USB 实现原理的理解
13.4.4. 提交和控制一个 urb// 有数据流的实现.
13.5. 无 urb 的 USB 传送//urb简单替代,位于usb/core/message.c
(1) int usb_bulk_msg(struct usb_device *usb_dev, unsigned int pipe,void *data, int len, int *actual_length,int timeout);//对应块 urb
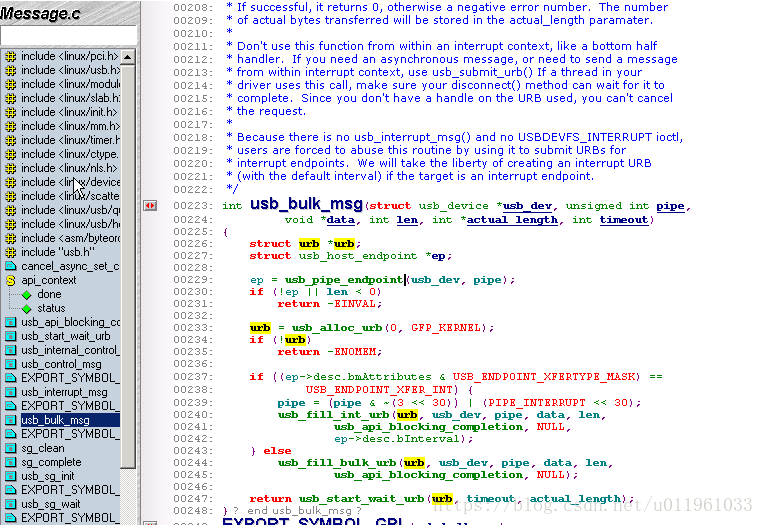
这个函数的参数是:
struct usb_device *usb_dev
发送块消息去的 USB 设备的指针
unsigned int pipe
这个块消息要发送到的 USB 设备的特定端点. 这个值被创建, 使用一个对 usb_sndbulkpipe 或者usb_rcvbulkpipe 的调用.
void *data
如果这是一个 OUT 端点, 指向要发送到设备的数据的指针. 如果是一个 IN 端点, 这是一个在被从设备读出后数据应当被放置的地方的指针.
int len
被 data 参数指向的缓冲的长度
int *actual_length
指向函数放置真实字节数的指针, 这些字节要么被发送到设备要么从设备中获取, 根据端点方向.
int timeout
时间量, 以嘀哒计, 应当在超时前等待的. 如果这个值是 0, 函数永远等待消息完成.
usb_bulk_msg 函数不能被从中断上下文调用, 或者持有一个自旋锁. 还有, 这个函数不能被任何其他函数取消, 因此当使用它时小心; 确认你的驱动的去连接知道足够多来等待调用结束, 在允许它自己被从内存中卸载之前.
(2)//控制 urb
int usb_control_msg(struct usb_device *dev, unsigned int pipe, __u8 request, __u8 requesttype, __u16 value, __u16 index, void *data, __u16 size, int timeout);
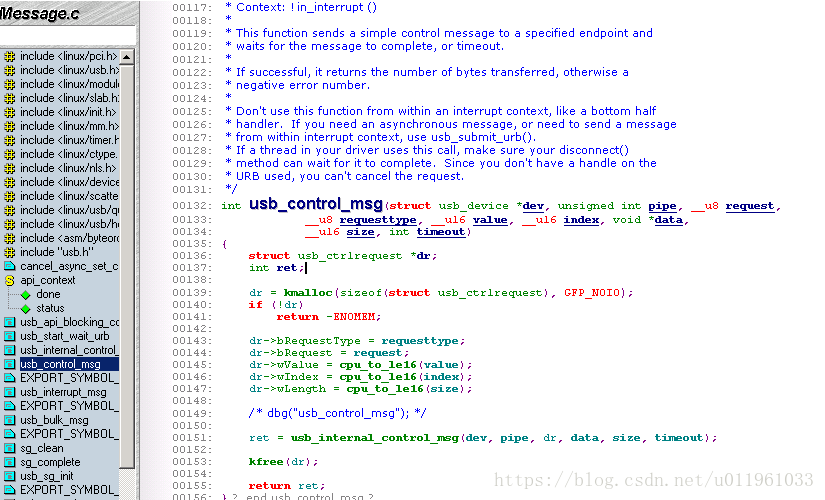
void *data
如果是一个 OUT 端点, 是一个指向要发送到设备的数据的指针. 如果是一个 IN 端点, 是一个在被从设备读取后数据被放置的地方的指针.
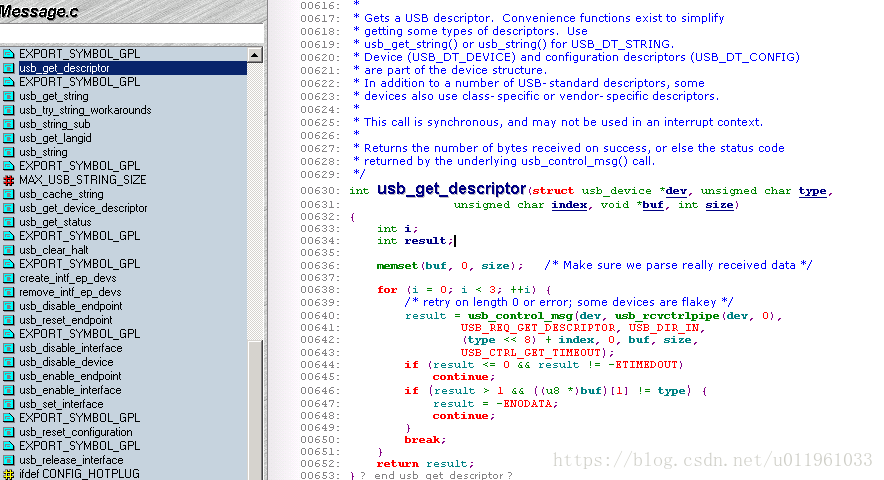
(3)函数 usb_get_descriptor 获取指定的 USB 描述符从特定的设备. 这个函数被定义为:
int usb_get_descriptor(struct usb_device *dev, unsigned char type, unsigned char index, void *buf, int size);
这个函数可被一个 USB 驱动用来从 struct usb_device 结构中, 获取任何还没有在 struct usb_device 和 struct usb_interface 结构中出现的设备描述符, 例如声音描述符或者其他类的特定消息. 这个函数的参数是:
第15章 内存映射和DMA
15.1. Linux 中的内存管理
15.1.1. 地址类型
User virtual addresses
Physical addresses
Bus addresses
Kernel logical addresses
Kernel virtual addresses
15.1.2. 物理地址和页
15.1.3. 高和低内存
Low memory
逻辑地址在内核空间中存在的内存. 在大部分每个系统你可能会遇到, 所有的内存都是低内存.
High memory
逻辑地址不存在的内存, 因为它在为内核虚拟地址设置的地址范围之外.
15.1.4. 内存映射和 struct page
15.1.5. 页表
15.1.6. 虚拟内存区
Text Segment(代码段):主要包括可以执行的文件ELF(Excutable and Linkerable Format)和常量。
Data Segment(数据段):初始化的全局变量和静态变量。
BSS Segment(Block Started by symbol)未初始化的全局变量和静态变量。
heap(堆):用malloc,calloc,realloc分配的
Stack(栈 zhan):函数体中定义的变量,函数指针
(1)cat /proc/pid/maps 查看
start-end perm offset major:minor inode image
start end
这个内存区的开始和结束虚拟地址.
perm
带有内存区的读,写和执行许可的位掩码. 这个成员描述进程可以对属于这个区的页做什么. 成员的最后一个字符要么是给"私有"的 p 要么是给"共享"的 s.
offset
内存区在它被映射到的文件中的起始位置. 0 偏移意味着内存区开始对应文件的开始.
major minor
持有已被映射文件的设备的主次编号. 易混淆地, 对于设备映射, 主次编号指的是持有被用户打开的设备特殊文件的磁盘分区, 不是设备自身.
inode
被映射文件的 inode 号.
image
已被映射的文件名((常常在一个可执行映象中).
例子:
shell@android:/ # cat /proc/973/maps
004e3000-00615000 rwxp 00000000 00:00 0
00f3a000-01071000 rwxp 00000000 00:00 0 [heap]
10000000-10001000 ---p 00000000 00:00 0
10001000-10100000 rwxp 00000000 00:00 0
40005000-40060000 rwxp 00000000 00:00 0
40073000-4007b000 r-xs 00000000 00:0b 269 /dev/__properties__ (deleted)
4007b000-40092000 rwxp 00000000 00:00 0
400a9000-400aa000 r-xp 00000000 00:00 0
400aa000-400bb000 rwxp 00000000 00:00 0
400de000-400df000 ---p 00000000 00:00 0
400df000-401de000 rwxp 00000000 00:00 0
401de000-402a2000 rwxp 00000000 00:00 0
402ae000-402af000 ---p 00000000 00:00 0
402af000-403ae000 rwxp 00000000 00:00 0
403be000-403fb000 rwxp 00000000 00:00 0
40471000-40472000 ---p 00000000 00:00 0
40472000-40571000 rwxp 00000000 00:00 0
405cf000-405d4000 rwxs 1c438000 00:0b 260 /dev/mem
40658000-40659000 ---p 00000000 00:00 0
40659000-40758000 rwxp 00000000 00:00 0
40758000-40759000 ---p 00000000 00:00 0
40759000-40858000 rwxp 00000000 00:00 0
4089d000-4089e000 ---p 00000000 00:00 0
4089e000-4099d000 rwxp 00000000 00:00 0
409d5000-409eb000 rwxp 00000000 00:00 0
40a3e000-40a3f000 ---p 00000000 00:00 0
40a3f000-40b3e000 rwxp 00000000 00:00 0
40b3e000-40b3f000 ---p 00000000 00:00 0
40b3f000-40c3e000 rwxp 00000000 00:00 0
40d26000-41026000 rwxs 2a90a000 00:0b 1415 /dev/feeder
4102d000-4102e000 ---p 00000000 00:00 0
4102e000-4112d000 rwxp 00000000 00:00 0
4117b000-4117c000 ---p 00000000 00:00 0
4117c000-4127b000 rwxp 00000000 00:00 0
412e7000-412e8000 ---p 00000000 00:00 0
412e8000-413e7000 rwxp 00000000 00:00 0
414d3000-414d4000 ---p 00000000 00:00 0
414d4000-415d3000 rwxp 00000000 00:00 0
4167b000-4167c000 ---p 00000000 00:00 0
4167c000-4177b000 rwxp 00000000 00:00 0
41844000-41845000 ---p 00000000 00:00 0
41845000-41944000 rwxp 00000000 00:00 0
419a3000-419a4000 ---p 00000000 00:00 0
419a4000-41aa3000 rwxp 00000000 00:00 0
41aa3000-41aa4000 ---p 00000000 00:00 0
41aa4000-41ba3000 rwxp 00000000 00:00 0
41c20000-42821000 rwxp 00000000 00:00 0
42821000-42822000 ---p 00000000 00:00 0
42822000-42921000 rwxp 00000000 00:00 0
4292f000-42930000 ---p 00000000 00:00 0
42930000-42a2f000 rwxp 00000000 00:00 0
42ae5000-42ae6000 ---p 00000000 00:00 0
42ae6000-42be5000 rwxp 00000000 00:00 0
42c7c000-42c7d000 ---p 00000000 00:00 0
42c7d000-42d7c000 rwxp 00000000 00:00 0
439dd000-439de000 ---p 00000000 00:00 0
439de000-43add000 rwxp 00000000 00:00 0
43b01000-43b02000 ---p 00000000 00:00 0
43b02000-43c01000 rwxp 00000000 00:00 0
43cf8000-43cf9000 ---p 00000000 00:00 0
43cf9000-43df8000 rwxp 00000000 00:00 0
43df8000-43df9000 ---p 00000000 00:00 0
43df9000-43ef8000 rwxp 00000000 00:00 0
43fce000-43fcf000 ---p 00000000 00:00 0
43fcf000-440ce000 rwxp 00000000 00:00 0
440ce000-440cf000 ---p 00000000 00:00 0
440cf000-441ce000 rwxp 00000000 00:00 0
441d2000-441d3000 ---p 00000000 00:00 0
441d3000-442d2000 rwxp 00000000 00:00 0
4435e000-4435f000 ---p 00000000 00:00 0
4435f000-4445e000 rwxp 00000000 00:00 0
444e6000-444e7000 ---p 00000000 00:00 0
444e7000-445e6000 rwxp 00000000 00:00 0
44695000-44696000 ---p 00000000 00:00 0
44696000-44795000 rwxp 00000000 00:00 0
44876000-44877000 ---p 00000000 00:00 0
44877000-44976000 rwxp 00000000 00:00 0
44a4a000-44a4b000 ---p 00000000 00:00 0
44a4b000-44b4a000 rwxp 00000000 00:00 0
44bd4000-44bd5000 ---p 00000000 00:00 0
44bd5000-44cd4000 rwxp 00000000 00:00 0
44d9d000-44d9e000 ---p 00000000 00:00 0
44d9e000-44e9d000 rwxp 00000000 00:00 0
44f69000-44f6a000 ---p 00000000 00:00 0
44f6a000-45069000 rwxp 00000000 00:00 0
4511d000-4511e000 ---p 00000000 00:00 0
4511e000-4521d000 rwxp 00000000 00:00 0
452b8000-452b9000 ---p 00000000 00:00 0
452b9000-453b8000 rwxp 00000000 00:00 0
45465000-45466000 ---p 00000000 00:00 0
45466000-45565000 rwxp 00000000 00:00 0
455f4000-455f5000 ---p 00000000 00:00 0
455f5000-456f4000 rwxp 00000000 00:00 0
45799000-4579a000 ---p 00000000 00:00 0
4579a000-45899000 rwxp 00000000 00:00 0
458b1000-458b2000 ---p 00000000 00:00 0
458b2000-459b1000 rwxp 00000000 00:00 0
45a97000-45a98000 ---p 00000000 00:00 0
45a98000-45b97000 rwxp 00000000 00:00 0
45c2e000-45c2f000 ---p 00000000 00:00 0
45c2f000-45d2e000 rwxp 00000000 00:00 0
45dbc000-45dbd000 ---p 00000000 00:00 0
45dbd000-45ebc000 rwxp 00000000 00:00 0
45f17000-45f18000 ---p 00000000 00:00 0
45f18000-46017000 rwxp 00000000 00:00 0
46023000-46024000 ---p 00000000 00:00 0
46024000-46123000 rwxp 00000000 00:00 0
46157000-46158000 ---p 00000000 00:00 0
46158000-46257000 rwxp 00000000 00:00 0
4630c000-4630d000 ---p 00000000 00:00 0
4630d000-4640c000 rwxp 00000000 00:00 0
4646b000-4646c000 ---p 00000000 00:00 0
4646c000-4656b000 rwxp 00000000 00:00 0
46583000-46584000 ---p 00000000 00:00 0
46584000-46683000 rwxp 00000000 00:00 0
46777000-46778000 ---p 00000000 00:00 0
46778000-46877000 rwxp 00000000 00:00 0
46877000-46878000 ---p 00000000 00:00 0
46878000-46977000 rwxp 00000000 00:00 0
46977000-46978000 ---p 00000000 00:00 0
46978000-46a77000 rwxp 00000000 00:00 0
46aff000-46b00000 ---p 00000000 00:00 0
46b00000-46bff000 rwxp 00000000 00:00 0
46c21000-46c22000 ---p 00000000 00:00 0
46c22000-46d21000 rwxp 00000000 00:00 0
46dba000-46dbb000 ---p 00000000 00:00 0
46dbb000-46eba000 rwxp 00000000 00:00 0
46ec8000-46ec9000 ---p 00000000 00:00 0
46ec9000-46fc8000 rwxp 00000000 00:00 0
46fdf000-46fe0000 ---p 00000000 00:00 0
46fe0000-470df000 rwxp 00000000 00:00 0
9ec00000-9ec01000 r-xp 00000000 b3:06 610 /system/lib/libdtv_getline.so
9ec01000-9ec02000 rwxp 00001000 b3:06 610 /system/lib/libdtv_getline.so
9ef00000-9ef2f000 r-xp 00000000 b3:06 598 /system/lib/libcurl.so
9ef2f000-9ef30000 rwxp 0002f000 b3:06 598 /system/lib/libcurl.so
af700000-af7ad000 r-xp 00000000 b3:06 596 /system/lib/libcrypto.so
af7ad000-af7bd000 rwxp 000ad000 b3:06 596 /system/lib/libcrypto.so
af7bd000-af7bf000 rwxp 00000000 00:00 0
af800000-af828000 r-xp 00000000 b3:06 674 /system/lib/libssl.so
af828000-af82c000 rwxp 00028000 b3:06 674 /system/lib/libssl.so
af900000-af917000 r-xp 00000000 b3:06 716 /system/lib/libz.so
af917000-af918000 rwxp 00017000 b3:06 716 /system/lib/libz.so
afc00000-afc15000 r-xp 00000000 b3:06 641 /system/lib/libm.so
afc15000-afc16000 rwxp 00015000 b3:06 641 /system/lib/libm.so
afd00000-afd01000 r-xp 00000000 b3:06 691 /system/lib/libstdc++.so
afd01000-afd02000 rwxp 00001000 b3:06 691 /system/lib/libstdc++.so
afe00000-afe41000 r-xp 00000000 b3:06 588 /system/lib/libc.so
afe41000-afe44000 rwxp 00041000 b3:06 588 /system/lib/libc.so
afe44000-afe4f000 rwxp 00000000 00:00 0
b0001000-b000c000 r-xp 00001000 b3:06 135 /system/bin/linker
b000c000-b000d000 rwxp 0000c000 b3:06 135 /system/bin/linker
b000d000-b0018000 rwxp 00000000 00:00 0
bee79000-bee9a000 rwxp 00000000 00:00 0 [stack]
ffff0000-ffff1000 r-xp 00000000 00:00 0 [vectors]
(2)vm_area_struct 结构

15.1.7. 进程内存映射
15.2. mmap 设备操作
映射一个设备意味着关联一些用户空间地址到设备内存. 无论何时程序在给定范围内读或写,
mmap 方法是 file_operation 结构的一部分, 当发出 mmap 系统调用时被引用. 用了 mmap, 内核进行大量工作在调用实际的方法之前, 并且, 因此, 方法的原型非常不同于系统调用的原型. 这不象 ioctl 和 poll 等调用, 内核不会在调用这些方法之前做太多.
系统调用原型:
mmap (caddr_t addr, size_t len, int prot, int flags, int fd, off_t offset)
文件操作声明原型:
int (*mmap) (struct file *filp, struct vm_area_struct *vma);
为实现 mmap, 驱动只要建立合适的页表给vma 包含关于用来存取设备的虚拟地址范围, 并且, 如果需要, 用新的操作集合替换 vma->vm_ops.
建立页表的方法:
1):15.2.1. 使用 remap_pfn_range:
int remap_pfn_range(struct vm_area_struct *vma, unsigned long virt_addr, unsigned long pfn, unsigned long size, pgprot_t prot);
int io_remap_page_range(struct vm_area_struct *vma, unsigned long virt_addr, unsigned long phys_addr, unsigned long size, pgprot_t prot);
2):15.2.4. 使用 nopage 映射内存
有下列原型:
struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);
15.2.5. 重新映射特定 I/O 区
15.2.6. 重新映射 RAM
15.2.7. 重映射内核虚拟地址
15.3. 进行直接I/O
15.4. 直接内存存取(DMA)
15.4.1. 一个 DMA 数据传输的概况
DMA数据传输可由 2 种方法触发:
数据传输可由 2 种方法触发:或者软件请求数据(通过一个函数例如 read)或者硬件异步推数据到系统.
在第一种情况, 包含的步骤总结如下:
1. 当一个进程调用 read, 驱动方法分配一个 DMA 缓冲并引导硬件来传输它的数据到那个缓冲. 这个进程被置为睡眠.
2. 硬件写数据到这个 DMA 缓冲并且在它完成时引发一个中断.
3. 中断处理获得输入数据, 确认中断, 并且唤醒进程, 它现在可以读数据了.
第 2 种情况到来是当 DMA 被异步使用
1. 硬件引发一个中断来宣告新数据已经到达.
2. 中断处理分配一个缓冲并且告知硬件在哪里传输数据.
3. 外设写数据到缓冲并且引发另一个中断当完成时.
处理者分派新数据, 唤醒任何相关的进程, 并且负责杂务.
15.4.2. 分配 DMA 缓冲
15.4.4. 通用 DMA 层
15.4.4.1. 处理困难硬件
15.4.4.2. DMA 映射
15.4.4.3. 建立一致 DMA 映射
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int flag);
void dma_free_coherent(struct device *dev, size_t size, void *vaddr, dma_addr_t dma_handle);
15.4.4.4. DMA 池
一个 DMA池 是分配小的, 一致DMA映射的分配机制

15.4.4.5. 建立流 DMA 映射
1)当你有单个缓冲要发送, 使用 dma_map_single 来映射它:
dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction direction);
2)一旦传输完成, 映射应当用 dma_unmap_single 来删除:
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma_data_direction direction);
一些重要的规则适用于流 DMA 映射:
1)缓冲必须用在只匹配它被映射时给定的方向的传输.
2)一旦一个缓冲已被映射, 它属于这个设备, 不是处理器. 直到这个缓冲已被去映射, 驱动不应当以任何方式触动它的内容. 只在调用 dma_unmap_single 后驱动才可安全存取缓冲的内容(有一个例外, 我们马上见到). 其他的事情, 这个规则隐含一个在被写入设备的缓冲不能被映射, 直到它包含所有的要写的数据.
3)这个缓冲必须不被映射, 当 DMA 仍然激活, 否则肯定会有严重的系统不稳定
15.4.4.6. 单页流映射
dma_addr_t dma_map_page(struct device *dev, struct page *page,unsigned long offset, size_t size, enum dma_data_direction direction);
void dma_unmap_page(struct device *dev, dma_addr_t dma_address,size_t size, enum dma_data_direction direction);
15.4.4.7. 发散/汇聚映射
int dma_map_sg(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction direction)
dma_addr_t sg_dma_address(struct scatterlist *sg);
unsigned int sg_dma_len(struct scatterlist *sg);
第16章 块驱动
16.1.1. 块驱动注册
int register_blkdev(unsigned int major, const char *name);
int unregister_blkdev(unsigned int major, const char *name);
16.1.2. 磁盘注册
16.1.2.1. 块设备操作(linux/blkdev.h)

int (*media_changed) (struct gendisk *gd); 用来检查是否用户已经改变了驱动器中的介质.
int (*revalidate_disk) (struct gendisk *gd); 方法被调用来响应一个介质改变.
16.1.2.2. gendisk 结构<linux/genhd.h>

1)成员解析.
char disk_name[32]; 应当被设置为磁盘驱动器名子的成员.
struct block_device_operations *fops;设备操作集合
struct request_queue *queue;.被内核用来管理这个设备的 I/O 请求的结构; 我们在"请求处理"一节中检查它
int flags;
一套标志(很少使用), 描述驱动器的状态. 如果你的设备有可移出的介质, 你应当设置 GENHD_FL_REMOVABLE. CD-ROM 驱动器可设置 GENHD_FL_CD. 如果, 由于某些原因, 你不需要分区信息出现在 /proc/partitions, 设置 GENHD_FL_SUPPRESS_PARTITIONS_INFO.
void *private_data;块驱动可使用这个成员作为一个指向它们自己内部数据的指针.
2)初始化:
struct gendisk 是一个动态分配的结构, 它需要特别的内核操作来初始化.
第一步:struct gendisk *alloc_disk(int minors); 对应释放void del_gendisk(struct gendisk *gd);.
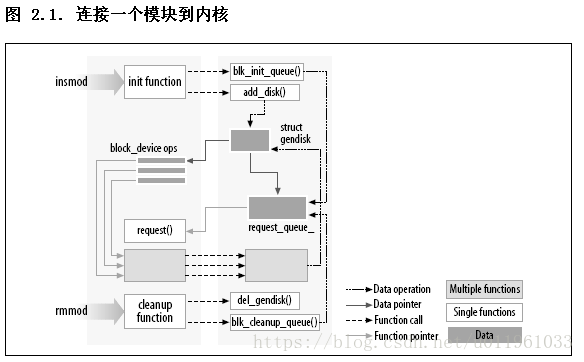
一个 gendisk 是一个被引用计数的结构(它含有一个 kobject). 有 get_disk 和 put_disk 函数用来操作引用计数, 但是驱动应当从不需要做这个. 正常地, 对 del_gendisk 的调用去掉了最一个 gendisk 的最终的引用, 但是不保证这样. 因此, 这个结构可能继续存在(并且你的方法可能被调用)在调用 del_gendisk 之后. 但是, 如果你删除这个结构当没有用户时(即, 在最后的释放之后, 或者在你的模块清理函数), 你可确信你不会再收到它的信息..
第二步:void add_disk(struct gendisk *gd);
这里记住一件重要的事情:一旦你调用add_disk, 这个磁盘是"活的"并且它的方法可被在任何时间被调用. 实际上, 这样的第一个调用将可能发生, 即便在 add_disk 返回之前; 内核将读前几个字节以试图找到一个分区表. 因此你不应当调用 add_disk 直到你的驱动被完全初始化并且准备好响应对那个磁盘的请求
16.1.3 块设备注册列子.
第一步:注册设备.
sbull_major = register_blkdev(sbull_major, "sbull");
if (sbull_major <= 0)
{
printk(KERN_WARNING "sbull: unable to get major number\n");
return -EBUSY;
}
第二部:请求锁lock和队列/queue.
struct sbull_dev {
int size; /* Device size in sectors */
u8 *data; /* The data array */
short users; /* How many users */
short media_change; /* Flag a media change? */
spinlock_t lock; /* For mutual exclusion */
struct request_queue *queue; /* The device request queue */
struct gendisk *gd; /* The gendisk structure */
struct timer_list timer; /* For simulated media changes */
};
memset (dev, 0, sizeof (struct sbull_dev));
dev->size = nsectors*hardsect_size;
dev->data = vmalloc(dev->size);
if (dev->data == NULL)
{
printk (KERN_NOTICE "vmalloc failure.\n");
return;
}
spin_lock_init(&dev->lock);//请求锁
dev->queue = blk_init_queue(sbull_request, &dev->lock);
这里, sbull_request 是我们的请求函数 -- 实际进行块读和写请求的函数. 当我们分配一个请求队列时, 我们必须提供一个自旋锁来控制对那个队列的存取. 这个锁由驱动提供而不是内核通常的部分, 因为, 常常, 请求队列和其他的驱动数据结构在相同的临界区; 它们可能被同时存取. 如同任何分配内存的函数, blk_init_queue 可能失败, 因此你必须在继续之前检查返回值
第三部:增加设备.
dev->gd = alloc_disk(SBULL_MINORS);
if (! dev->gd)
{
printk (KERN_NOTICE "alloc_disk failure\n");
goto out_vfree;
}
dev->gd->major = sbull_major;
dev->gd->first_minor = which*SBULL_MINORS;
dev->gd->fops = &sbull_ops;
dev->gd->queue = dev->queue;
dev->gd->private_data = dev;
snprintf (dev->gd->disk_name, 32, "sbull%c", which + 'a');
set_capacity(dev->gd, nsectors*(hardsect_size/KERNEL_SECTOR_SIZE));
add_disk(dev->gd);
16.1.4. 注意扇区大小/通过queue函数来动态设置
blk_queue_hardsect_size(dev->queue, hardsect_size);
16.2. 块设备操作
16.2.1. open和release 方法
open与release 维护一个用户计数/定时器.
计数:表示有多用户在用设备
定时器:它假装是一个可移出的设备. 无论何时最后一个用户关闭设备, 一个 30 秒的定时器被设置; 如果设备在这个时间内不被打开, 设备的内容被清除, 并且内核被告知介质已被改变. 30 秒延迟给了用户时间
16.2.2. 支持可移出的介质/int(*media_changed)与int(*revalidate_disk)
16.2.3. ioctl 方法
16.3. 请求处理/可以优化block 设备的性能.
16.3.1. 对请求方法的介绍
在设备驱动请求一个请求队列.
dev->queue = blk_init_queue(sbull_request, &dev->lock);
请求函数的启动(常常地)与任何用户空间进程之间是完全异步的. 你不能假设内核运行在发起当前请求的进程上下文. 你不知道由这个请求提供的 I/O 缓冲是否在内核或者用户空间. 因此任何类型的明确存取用户空间的操作都是错误的并且将肯定引起麻烦. 如你将见到的, 你的驱动需要知道的关于请求的所有事情, 都包含在通过请求队列传递给你的结构中
16.3.2. 一个简单的请求方法/请求回调函数.
16.3.3. 请求队列/块设备性能优化的关键
请求队列还实现一个插入接口, 这个接口允许使用多 I/O 调度器(或者电梯). 一个 I/O 调度器的工作是提交 I/O 请求给你的驱动, 以最大化性能的方式. 为此, 大部分 I/O 调度器累积批量的 I/O 请求, 排列它们为递增(或递减)的块索引顺序, 并且以那个顺序提交请求给驱动. 磁头, 当给定一列排序的请求时, 从磁盘的一头到另一头工作, 非常象一个满载的电梯, 在一个方向移动直到所有它的"请求"(等待出去的人)已被满足. 2.6 内核包含一个"底线调度器", 它努力确保每个请求在预设的最大时间内被满足, 以及一个"预测调度器", 它实际上短暂停止设备, 在一个预想中的读请求之后, 这样另一个邻近的读将几乎是马上到达. 到本书为止, 缺省的调度器是预测调度器, 它看来有最好的交互的系统性能.
16.3.3.1. 队列的创建和删除
request_queue_t *blk_init_queue(request_fn_proc *request, spinlock_t *lock)
void blk_cleanup_queue(request_queue_t *);
16.3.3.2. 排队函数
struct request *elv_next_request(request_queue_t *queue); 它返回一个指向下一个要处理的请求的指针(由 I/O 调度器所决定的)或者 NULL 如果没有请求要处理
void blkdev_dequeue_request(struct request *req);从一个队列中去除一个请求
void elv_requeue_request(request_queue_t *queue, struct request *req); 需要放置一个出列请求回到队列中
16.3.3.3. 队列控制函数
void blk_stop_queue(request_queue_t *queue);
void blk_start_queue(request_queue_t *queue);
如果你的设备已到到达一个状态, 它不能处理等候的命令, 你可调用 blk_stop_queue 来告知块层. 在这个调用之后, 你的请求函数将不被调用直到你调用 blk_start_queue. 不用说, 你不应当忘记重启队列, 当你的设备可处理更多请求时. 队列锁必须被持有当调用任何一个这些函数时.
void blk_queue_bounce_limit(request_queue_t *queue, u64 dma_addr);
告知内核你的设备可进行 DMA 的最高物理地址的函数
void blk_queue_max_sectors(request_queue_t *queue, unsigned short max);
//以扇区方式设置任一请求的最大的大小; 缺省是 255
void blk_queue_max_phys_segments(request_queue_t *queue, unsigned short max);
void blk_queue_max_hw_segments(request_queue_t *queue, unsigned short max);
//blk_queue_max_hw_segments 都控制多少物理段(系统内存中不相邻的区)可包含在一个请求中. 使用 blk_queue_max_phys_segments 来说你的驱动准备处理多少段; 例如, 这可能是一个静态分配的散布表的大小. blk_queue_max_hw_segments, 相反, 是设备可处理的最多的段数. 这 2 个参数缺省都是 128
void blk_queue_max_segment_size(request_queue_t *queue, unsigned int max);
//告知内核任一个请求的段可能是多大字节; 缺省是 65,536 字节.
blk_queue_segment_boundary(request_queue_t *queue, unsigned long mask);
//些设备无法处理跨越一个特殊大小内存边界的请求; 如果你的设备是其中之一, 使用这个函数来告知内核这个边界. 例如, 如果你的设备处理跨 4-MB 边界的请求有困难, 传递一个 0x3fffff 掩码. 缺省的掩码是 0xffffffff.
void blk_queue_dma_alignment(request_queue_t *queue, int mask);
//告知内核关于你的设备施加于 DMA 传送的内存对齐限制的函数. 所有的请求被创建有给定的对齐, 并且请求的长度也匹配这个对齐. 缺省的掩码是 0x1ff, 它导致所有的请求被对齐到 512-字节边界.
void blk_queue_hardsect_size(request_queue_t *queue, unsigned short max);
//告知内核你的设备的硬件扇区大小. 所有由内核产生的请求是这个大小的倍数并且被正确对齐. 所有的在块层和驱动之间的通讯继续以 512-字节扇区来表达, 但是.
16.3.4. 请求的分析/原来分析:
每个请求结构代表一个块 I/O 请求, 尽管它可能是由几个独立的请求在更高层次合并而成. 对任何特殊的请求而传送的扇区可能分布在整个主内存, 尽管它们常常对应块设备中的多个连续的扇区. 这个请求被表示为多个段, 每个对应一个内存中的缓冲. 内核可能合并多个涉及磁盘上邻近扇区的请求, 但是它从不合并在单个请求结构中的读和写操作. 内核还确保不合并请求, 如果结果会破坏任何的在前面章节中描述的请求队列限制.
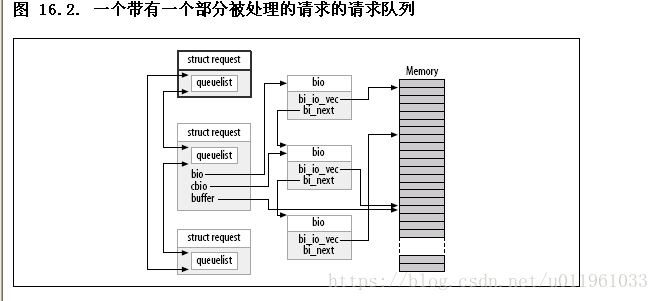
第二cbio 和 buffer 处于指向尚未传送的第一个 bio.
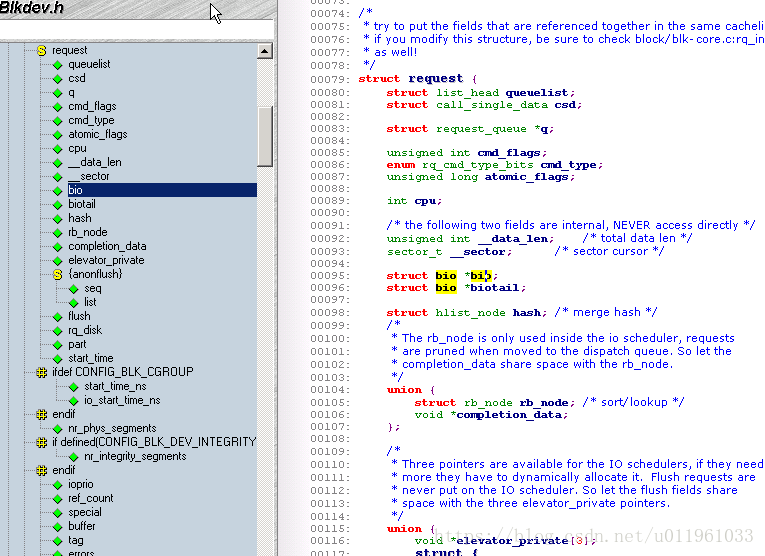
(1)struct request
关键成员:
struct bio *bio;
//bio 是给这个请求的 bio 结构的链表. 你不应当直接存取这个成员; 使用 rq_for_each_bio(后面描述) 代替.
char *buffer;
//本章前面的简单驱动例子使用这个成员来找到传送的缓冲. 随着我们的深入理解, 我们现在可见到这个成员仅仅是在当前 bio 上调用 bio_data 的结果.
unsigned short nr_phys_segments;
//被这个请求在物理内存中占用的独特段的数目, 在邻近页已被合并后.
struct list_head queuelist;
//连接这个请求到请求队列
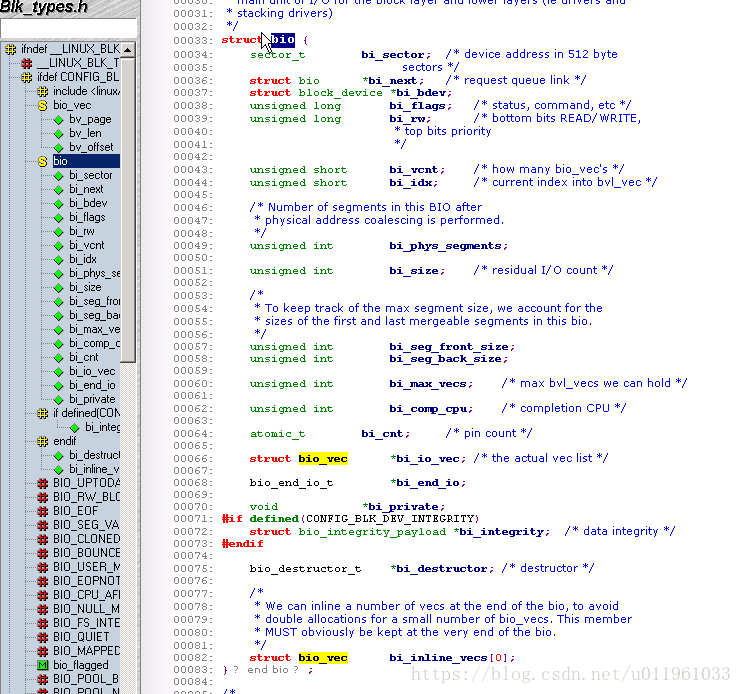
(2) stuct bio
关键成员:
sector_t bi_sector;
这个 bio 要被传送的第一个(512字节)扇区.
unsigned int bi_size;
被传送的数据大小, 以字节计. 相反, 常常更易使用 bio_sectors(bio), 一个给定以扇区计的大小的宏.
unsigned long bi_flags;
一组描述 bio 的标志; 最低有效位被置位如果这是一个写请求(尽管宏 bio_data_dir(bio)应当用来代替直接加锁这个标志).
unsigned short bio_phys_segments;
unsigned short bio_hw_segments;
包含在这个 BIO 中的物理段的数目, 和在 DMA 映射完成后被硬件看到的段数目, 分别地.
struct Bio_Vec *bi_io_vec.
即:struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
所有的一个驱动需要做的事情是步进全部这个结构数组(它们有 bi_vcnt 个), 和在每个页内传递数据(但是只 len 字节, 从 offset 开始).
操作方法:
它简单地循环 bi_io_vec 数组中每个未被处理的项

struct page *bio_page(struct bio *bio);
返回一个指向页结构的指针, 表示下一个被传送的页.
int bio_offset(struct bio *bio);
返回页内的被传送的数据的偏移.
int bio_cur_sectors(struct bio *bio);
返回要被传送出当前页的扇区数.
char *bio_data(struct bio *bio);
返回一个内核逻辑地址, 指向被传送的数据. 注意这个地址可用仅当请求的页不在高内存中; 在其他情况下调用它是一个错误. 缺省地, 块子系统不传递高内存缓冲到你的驱动, 但是如果你已使用 blk_queue_bounce_limit 改变设置, 你可能不该使用 bio_data.
char *bio_kmap_irq(struct bio *bio, unsigned long *flags);
void bio_kunmap_irq(char *buffer, unsigned long *flags);
bio_kmap_irq 给任何缓冲返回一个内核虚拟地址, 不管它是否在高或低内存. 一个原子 kmap 被使用, 因此你的驱动在这个映射被激活时不能睡眠. 使用 bio_kunmap_irq 来去映射缓冲. 注意因为使用一个原子 kmap, 你不能一次映射多于一个段.
3) 屏障请求
矛盾:有些应用程序要求保证某些操作在其他的启动前完成.如, 关系数据库管理者, 必须绝对确保它们的日志信息刷新到驱动器, 在执行在数据库内容上的一次交易之前.
解决方法:设置请求 REQ_HARDBARRER 标志
实现:
驱动通知块层这个事实
void blk_queue_ordered(request_queue_t *queue, int flag);
宏来进行这个测试驱动是否屏蔽请求
int blk_barrier_rq(struct request *req);
4) 不可重入请求
有时标识请求为不可重入的. 这样的请求应当完全尽快失败, 如果它们无法在第一次试的时候执行.
如果你的驱动在考虑重试一个失败的请求, 他应当首先调用:
int blk_noretry_request(struct request *req);
如果这个宏返回非零值, 你的驱动应当放弃这个请求, 使用一个错误码来代替重试它.
16.3.5. 请求完成函数
int end_that_request_first(struct request *req, int success, int count);
void end_that_request_last(struct request *req);
16.3.5.1. 使用 bio
16.3.5.2. 块请求和 DMA
int blk_rq_map_sg(request_queue_t *queue, struct request *req, struct scatterlist *list);
clear_bit(QUEUE_FLAG_CLUSTER, &queue->queue_flags);
16.3.5.3. 不用一个请求队列
原因:软件 RAID 阵列或者被逻辑卷管理者创建的虚拟磁盘, 没有这个块层的请求队列被优化的性能特征. 对于这类设备, 它最好直接从块层接收请求, 并且根本不去烦请求队列.
实现:
1)提供一个"制作请求"函数,
typedef int (make_request_fn) (request_queue_t *q, struct bio *bio);//它可或者直接进行传输, 或者重定向这个请求到另一个设备.
void bio_endio(struct bio *bio, unsigned int bytes, int error);//bytes 是你至今已经传送的字节数. 它可小于由这个 bio 整体所代表的字节数; 在这个方式中, 你可指示部分完成, 并且更新在 bio 中的内部的"当前缓冲"指针.
16.4. 一些其他的细节/高级命令请求
16.4.1. 命令预准备
作用:许驱动提前设立真正的驱动器命令, 决定是否这个请求可被完全处理, 或者进行其他的维护工作.
typedef int (prep_rq_fn) (request_queue_t *queue, struct request *req);
void blk_queue_prep_rq(request_queue_t *queue, prep_rq_fn *func);
16.4.2. 被标识的命令排队
可同时有多个请求被激活的硬件, 常常支持某种被标识的命令排队(TCQ).
int blk_queue_init_tags(request_queue_t *queue, int depth, struct blk_queue_tag *tags);
int blk_queue_resize_tags(request_queue_t *queue, int new_depth);
int blk_queue_start_tag(request_queue_t *queue, struct request *req);
void blk_queue_end_tag(request_queue_t *queue, struct request *req);
struct request *blk_queue_find_tag(request_queue_t *qeue, int tag);
void blk_queue_invalidate_tags(request_queue_t *queue);
16.5. 快速参考
第17章 网络驱动
17.1. snull是如何设计的
17.2. 连接到内核
17.2.1. 设备注册
linux-3.0/net/core/dev.c中.
第一步:申请资源.
struct net_device *alloc_netdev(int sizeof_priv,const char *name,void (*setup)(struct net_device *));
struct net_device *alloc_etherdev(int sizeof_priv);
//;等变异函数,申请资源.
第二部: 初始化,net_device 结果设备.具体参考17.3. net_device 结构的详情
第三步: 注册net device

//注册net device.
第四部:模块卸载

17.3. net_device 结构的详情
linux-3.0/include/linux/netdevice.h

17.3.1. 全局信息成员
17.3.2. 硬件信息成员
17.3.3. 接口信息成员//在alloc_etherdev中的enther_setup(struct net_device *dev)中设置.
17.3.4. 设备方法结果 net_device_ops,ethtool_ops,header_ops,//具体请参考17.4以后的章节;
17.3.5. 公用成员

17.4. 打开与关闭的实现:

对应的命令:ifconfig ethX;
主要做件事情:
1:用户层ioctl(SIOCSIFADDR)( Socket I/O Control Set Interface Address) 来安排地址;即驱动操作net_device中接口信息成员dev_addr[MAX_ADDR_LEN];
2:接着它设置 dev->flag 的 IFF_UP 位
3:启动接口的发送队列:void netif_start_queue(struct net_device *dev);
int snull_open(struct net_device *dev)
{
/* request_region(), request_irq( ), .... (like fops->open) */
/*
* Assign the hardware address of the board: use "\0SNULx", where
* x is 0 or 1. The first byte is '\0' to avoid being a multicast
* address (the first byte of multicast addrs is odd).
*/
memcpy(dev->dev_addr, "\0SNUL0", ETH_ALEN);
if (dev == snull_devs[1])
dev->dev_addr[ETH_ALEN-1]++; /* \0SNUL1 */
netif_start_queue(dev);
return 0;
}
int snull_stop(struct net_device *dev)
{
/* release ports, irq and such -- like fops->close */
netif_stop_queue(dev); /* can't transmit any more */
return 0;
}
17.5. 报文传送

主要包括
1:对socket 操作,
2:硬件传递函数.
int snull_tx(struct sk_buff *skb, struct net_device *dev)
{
int len;
char *data, shortpkt[ETH_ZLEN];
struct snull_priv *priv = netdev_priv(dev);
data = skb->data;
len = skb->len;
if (len < ETH_ZLEN) {
memset(shortpkt, 0, ETH_ZLEN);
memcpy(shortpkt, skb->data, skb->len);
len = ETH_ZLEN;
data = shortpkt;
}
dev->trans_start = jiffies; /* save the timestamp */
/* Remember the skb, so we can free it at interrupt time */
priv->skb = skb;
/* actual deliver of data is device-specific, and not shown here */ snull_hw_tx(data, len, dev);
return 0; /* Our simple device can not fail */
}
17.5.1. 控制发送并发
1:通过net_device 结构中的自旋锁(xmit_lock)来保护避免并发调用,
2:用void netif_wake_queue(struct net_device *dev); netif_start_queue(struct net_device *dev)/void netif_stop_queue(struct net_device *dev),void netif_tx_disable(struct net_device *dev); 控制工作队列;
17.5.2 传送超时函数的实现;
void snull_tx_timeout (struct net_device *dev)
{
struct snull_priv *priv = netdev_priv(dev);
PDEBUG("Transmit timeout at %ld, latency %ld\n", jiffies, jiffies - dev->trans_start);
/* Simulate a transmission interrupt to get things moving */
priv->status = SNULL_TX_INTR;
snull_interrupt(0, dev, NULL);
priv->stats.tx_errors++;
netif_wake_queue(dev);
return;
}
当发生传送超时, 驱动必须在接口统计量中标记这个错误, 并安排设备被复位到一个干净的能发送新报文的状态. 当一个超时发生在 snull, 驱动调用 snull_interrupt 来填充"丢失"的中断并用 netif_wake_queue 重启队列.
17.5.3. 发散/汇聚 I/O
如果net_device中的flag 设置NETIF_F_SG 表示支持发散/汇聚 I/O
实现:
if (skb_shinfo(skb)->nr_frags == 0) {
/* Just use skb->data and skb->len as usual */
}
nr_frags 成员告知多少片要用来建立这个报文. 如果它是 0, 报文存于一个单个片中, 可以如常使用 data 成员来存取. 但是, 如果它是非 0, 你的驱动必须历经并安排发送每一个单独的片. skb 结构的 data 成员方便地指向第一个片(在不分片情况下, 指向整个报文). 片的长度必须通过从 skb->len ( 仍然含有整个报文的长度 ) 中减去 skb->data_len 计算得来. 剩下的片会在称为 frags 的数组中找到, frags 在共享的信息结构中; frags 中每个入口是一个 skb_frag_struct 结构:
struct skb_frag_struct { struct page *page;
__u16 page_offset;
__u16 size;
};
如你所见, 我们又一次遇到 page 结构, 不是内核虚拟地址. 你的驱动应当遍历这些分片, 为 DMA 传送映射每一个, 并且不要忘记第一个分片, 它由 skb 直接指着. 你的硬件, 当然, 必须组装这些分片并作为一个单个报文发送它们. 注意, 如果你已经设置了NETIF_F_HIGHDMA 特性标志, 一些或者全部分片可能位于高端内存.
17.6. 报文接收
发走报文(已经存在内存中)和运行附加信息给上层的网络代码,
void snull_rx(struct net_device *dev, struct snull_packet *pkt)
{
struct sk_buff *skb;
struct snull_priv *priv = netdev_priv(dev);
/*
*
The packet has been retrieved from the transmission
*
medium. Build an skb around it, so upper layers can handle it
*/
skb = dev_alloc_skb(pkt->datalen + 2);
if (!skb) {
if (printk_ratelimit())
printk(KERN_NOTICE "snull rx: low on mem - packet dropped\n"); priv->stats.rx_dropped++; goto out;
}
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
/* Write metadata, and then pass to the receive level */
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
netif_rx(skb);
out:
return;
}
主要是两部分: 1)对socket 操作.2) netif_rx(skb)

17.7. 中断处理
把中断处理函数注册到中断中.中断过程能够告知新报文到达中断和发送完成通知的区别
static void snull_regular_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
int statusword;
struct snull_priv *priv;
struct snull_packet *pkt = NULL;
/*
*
As usual, check the "device" pointer to be sure it is
*
really interrupting.
*
Then assign "struct device *dev"
*/
struct net_device *dev = (struct net_device *)dev_id;
/* ... and check with hw if it's really ours */
/* paranoid */
if (!dev)
return;
/* Lock the device */
priv = netdev_priv(dev);
spin_lock(&priv->lock);
/* retrieve statusword: real netdevices use I/O instructions */
statusword = priv->status;
priv->status = 0;
if (statusword & SNULL_RX_INTR) {
/* send it to snull_rx for handling */
pkt = priv->rx_queue;
if (pkt) {
priv->rx_queue = pkt->next;
snull_rx(dev, pkt);
}
}
if (statusword & SNULL_TX_INTR) {
/* a transmission is over: free the skb */
priv->stats.tx_packets++;
priv->stats.tx_bytes += priv->tx_packetlen;
dev_kfree_skb(priv->skb);
}
/* Unlock the device and we are done */
spin_unlock(&priv->lock);
if (pkt) snull_release_buffer(pkt); /* Do this outside the lock! */
return;
}
17.8. 接收中断缓解/基于查询的接口(称为 NAPI)

第一步:改变中断处理
if (statusword & SNULL_RX_INTR) {
snull_rx_ints(dev, 0); /* Disable further interrupts */
netif_rx_schedule(dev);
}
第二步:实现和注册poll函数.
if (statusword & SNULL_RX_INTR) {
snull_rx_ints(dev, 0); /* Disable further interrupts */
netif_rx_schedule(dev);
}
static int snull_poll(struct net_device *dev, int *budget)
{
int npackets = 0, quota = min(dev->quota, *budget);
struct sk_buff *skb;
struct snull_priv *priv = netdev_priv(dev);
struct snull_packet *pkt;
while (npackets < quota && priv->rx_queue) {
pkt = snull_dequeue_buf(dev);
skb = dev_alloc_skb(pkt->datalen + 2);
if (! skb) {
if (printk_ratelimit())
printk(KERN_NOTICE "snull: packet dropped\n"); priv->stats.rx_dropped++; snull_release_buffer(pkt); continue;
}
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */
netif_receive_skb(skb);
/* Maintain stats */
npackets++;
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
snull_release_buffer(pkt);
}
/* If we processed all packets, we're done; tell the kernel and reenable ints */
*budget -= npackets;
dev->quota -= npackets;
if (! priv->rx_queue) {
netif_rx_complete(dev);
snull_rx_ints(dev, 1);
return 0;
}
/* We couldn't process everything. */
return 1;
}
17.9. 连接状态的改变
void netif_carrier_off(struct net_device *dev);
void netif_carrier_on(struct net_device *dev);
int netif_carrier_ok(struct net_device *dev);
17.10. Socket 缓存
<include/linux/skbuff.h>
关键成员:
unsigned char ip_summed;
这个报文的校验和策略. 由驱动在进入报文上设置这个成员, 如在"报文接收"一节中描述的.
unsigned char pkt_type;
在递送中使用的报文分类. 驱动负责设置它为 PACKET_HOST (报文是给自己的), PACKET_OTHERHOST (不, 这个报文不是给我的), PACKET_BROADCAST, 或者 PACKET_MULTICAST. 以太网驱动不显式修改 pkt_type, 因为 eth_type_trans 为它们做.
作用于 socket 缓存的函数
struct sk_buff *alloc_skb(unsigned int len, int priority);
struct sk_buff *dev_alloc_skb(unsigned int len);
void kfree_skb(struct sk_buff *skb);
void dev_kfree_skb(struct sk_buff *skb);
void dev_kfree_skb_irq(struct sk_buff *skb);
void dev_kfree_skb_any(struct sk_buff *skb);
unsigned char *skb_put(struct sk_buff *skb, int len);
unsigned char *__skb_put(struct sk_buff *skb, int len);
unsigned char *skb_push(struct sk_buff *skb, int len);
unsigned char *__skb_push(struct sk_buff *skb, int len);
int skb_tailroom(struct sk_buff *skb);
int skb_headroom(struct sk_buff *skb);
void skb_reserve(struct sk_buff *skb, int len);
unsigned char *skb_pull(struct sk_buff *skb, int len);
int skb_is_nonlinear(struct sk_buff *skb);
int skb_headlen(struct sk_buff *skb);
void *kmap_skb_frag(skb_frag_t *frag);
void kunmap_skb_frag(void *vaddr);
17.11. MAC 地址解析
Address Resolution Protocol (ARP)
17.11.1. 以太网使用 ARP
17.11.2. 不考虑 ARP
17.11.3. 非以太网头部
17.12. 定制 ioctl 命令

1) 标准的命令定义在linux/sockios.h中
17.13. 统计信息

17.14. 多播
一个多播报文是一个会被多个主机接收的网络报文,但不是所有主机.
内核来跟踪在任何给定时间对哪些多播地址感兴趣. 这个列表可能经常改变, 因为它是在任何给定时间和按照用户意愿运行的应用程序的功能. 驱动的工作是接收感兴趣的多播地址列表并递交给内核任何发向这些地址的报文. 驱动如何实现多播列表是依赖于底层硬件是如何工作的. 典型地, 在多播的角度上, 硬件属于 3 类中的 1 种:
不能处理多播的接口. 这样的接口要么接收特别地发向它们的硬件地址(加上广播报文)的报文, 要么接收每一个报文. 它们只能通过接收每一个报文来接收多播报文, 因此, 潜在地压垮操作系统, 使用大量的"不感兴趣"报文. 你不经常认为这样的接口是有多播能力的, 驱动不会在 dev->flags 设置 IFF_MULTICAST.
点对点接口是特殊情况, 因为它们一直接收每个报文, 不进行任何硬件过滤.
能够区别多播报文和其他报文(主机到主机, 或者广播). 这些接口能够被命令来接收每个多播报文, 让软件决定地址是否是主机感兴趣的. 这种情况下的开销是可接受的, 因为在一个典型网络上的多播报文的数目是少的.
可以进行硬件检测多播地址的接口. 可以传递一个多播地址的列表给这些接口, 这些地址的报文接收, 并忽略其他多播地址的报文. 对内核这是优化的情况, 因为它不浪费处理器时间来丢弃接口收到的"不感兴趣"的报文.
17.14.1. 多播的内核支持
1)设备方法

在与设备相关的机器地址改变时调用. 它也在 dev->flags 被修改时调用, 因为一些标志(例如, IFF_PROMISC) 可能也要求你重新编程硬件过滤器.
2)一个数据结构
struct dev_mc_list { struct dev_mc_list *next; /* Next address in list */
__u8 dmi_addr[MAX_ADDR_LEN]; /* Hardware address */
unsigned char dmi_addrlen; /* Address length */
int dmi_users; /* Number of users */
int dmi_gusers; /* Number of groups */
};
或者:

3)设备标识:
dev->flags /dev->mc_count;
IFF_MULTICAST
除非驱动在 dev->flags 中设置这个标志, 接口不会被要求来处理多播报文. 然而, 内核调用驱动的 set_multicast_list 方法, 当 dev->flags 改变时, 因为多播列表可能在接口未激活时改变了.
IFF_ALLMULTI
在 dev->flags 中设置的标志, 网络软件来告知驱动从网络上接收所有多播报文. 这发生在当多播路由激活时. 如果标志设置了, dev->ma_list 不该用来过滤多播报文.
IFF_PROMISC
在 dev->flags 中设置的标志, 当接口在混杂模式下. 接口应当接收每个报文, 不管 dev->ma_list
17.15. 几个其他细节
17.15.1. 独立于媒介的接口支持
17.15.2. ethtool 支持
17.15.3. netpoll
第18章 TTY 驱动
工作原理:
tty 核心从一个用户获取将要发送给一个 tty 设备的数据. 它接着传递它到一个 tty 线路规程驱动, 接着传递它到一个 tty 驱动. 这个 tty 驱动转换数据为可以发送给硬件的格式. 从 tty 硬件收到的数据向上回流通过 tty 驱动, 进入 tty 线路规程驱动, 再进入 tty 核心, 在这里它被一个用户获取. 有时 tty 驱动直接和 tty 核心通讯, 并且 tty 核心直接发送数据到 tty 驱动, 但是常常 tty 线路规程有机会修改在 2 者之间发送的数据.
其中协议层位于:tty line discipline与tty driver之间,如PPP和bluetooth.
tty 驱动类型:控制台/console,串口,pty.
查看:
1)/proc/tty/drivers 文件. 这个文件包括一个当前存在的不同 tty 驱动的列表
驱动名字 节点名子 主编号 次编号 驱动的类型

2)当前注册的以及在内核中出现的 tty 设备有它们自己的子目录在 /sys/class/tty 下面.
步骤:
18.1.1. tty_driver 结构提:

1).init_termios:提供一个健全的线路设置集合.
2).owner :为了防止 tty 驱动在 tty 端口打开时被卸载
3).driver_name:它在 /proc/tty/drivers 文件中出现来描述这个驱动给用户, 以及在当前已加载的 tty 驱动的 sysfs tty 类目录.
4).name:用来定义一个名子给单独的分配给这个 tty 驱动的 tty 节点在 /dev 树中.
5).major 主编号
6).minor_start:驱动的开始次编号. 这常常设为 name_base 的相同值. 典型地, 这个值设为 0.
7).type/subtype
描述什么类型的 tty 驱动在注册到 tty 核心. subtype 的值依赖于 type. type 成员可能是:
TTY_DRIVER_TYPE_SYSTEM
由 tty 子系统内部使用来记住它在处理一个内部 tty 驱动. subtype 应当设为 SYSTEM_TYPE_TTY, SYSTEM_TYEP_CONSOLE, SYSTEM_TYPE_SYSCONS, 或者 SYSTEM_TYPE_SYSPTMX. 这个类型不应当被任何"正常" tty 驱动使用.
TTY_DRIVER_TYPE_CONSOLE
仅被控制台驱动使用.
TTY_DRIVER_TYPE_SERIAL
被任何串行类型驱动使用. subtype 应当设为 SERIAL_TYPE_NORMAL 或者 SERIAL_TYPE_CALLOUT, 根据你的驱动是什么类型. 这是 type 成员的其中一个最普遍的设置.
TTY_DRIVER_TYPE_PTY
被伪控制台接口(pty)使用. subtype 需要被设置为 PTY_TYPE_MASTER 或者 PTY_TYPE_SLAVE.
8).flags 变量来指示驱动的当前状态和它是什么类型 tty 驱动
9)struct module *owner; 这个驱动的模块拥有者.
10)int magic; 给这个结构的"魔术"值. 应当一直设为 TTY_DRIVER_MAGIC. 在 alloc_tty_driver 函数中被初始化
11)int name_base;使用的起始数字, 当创建设备名子时. 当内核创建分配给这个 tty 驱动的一个特定 tty 设备的字符串表示是使用
12)short num;分配给这个驱动的次编号个数. 如果整个主编号范围被驱动使用了, 这个值应当设为 255. 这个变量在 alloc_tty_driver 函数中初始化.
13)
18.2. tty_driver 函数指针

18.2.1. open 和 close
1:open 函数被 tty 核心调用, 当一个用户对这个 tty 驱动被分配的设备节点调用 open 时. tty 核心使用一个指向分配给这个设备的 tty_struct 结构的指针调用它, 还用一个文件指针. 这个 open 成员必须被一个 tty 驱动为它能正确工作而设置; 否则, -ENODEV 被返回给用户当调用 open 时.
2:close 函数指针被 tty 核心调用, 在用户对前面使用 open 调用而创建的文件句柄调用 close 时. 这表示设备应当在这次被关闭. 但是, 因为 open 函数可被多次调用, close函数也可多次调用. 因此这个函数应当跟踪它被调用的次数来决定是否硬件应当在此次真正被关闭.
18.2.2. 数据流(write/write_room/put_char)
write 函数可从中断上下文和用户上下文中被调用. 知道这一点是重要的, 因为 tty 驱动不应当调用任何可能当它在中断上下文中睡眠的函数
write_room 函数被调用当 tty 核心想知道多少空间在写缓冲中 tty 驱动可用. 这个数字时时改变随着字符清空写缓冲以及调用写函数时, 添加字符到这个缓冲
18.2.3. 其他缓冲函数
chars_in_buffer :这个函数被调用当 tty 核心想知道多少字符仍然保留在 tty 驱动的写缓冲中要被发送
flush_chars :函数回调被调用当 tty 核心要 tty 驱动启动发送这些字符到硬件, 如果它尚未启动. 这个函数被允许在所有的数据发送给硬件之前返回.
wait_until_sent: 函数回调以非常相同的发生工作; 但是它必须等待直到所有的字符在返回到 tty 核心前被发送, 或者知道超时值到时. 如果这个传递给 wait_until_sent 函数回调的超时值设为 0, 函数应当等待直到它完成这个操作.
18.2.4. 无 read 函数?
tty 核心缓冲由 tty 驱动接收到的数据, 在一个称为 struct tty_flip_buffer 的结构中. 一个 flip 缓冲是一个结构包含 2 个主要数据数组. 从 tty 设备接收到的数据被存储于第一个数组. 当这个数组满, 任何等待数据的用户被通知数据可以读. 当用户从这个数组读数据, 任何新到的数据被存储在第 2 个数组. 当那个数组被读空, 数据再次刷新给用户, 并且驱动开始填充第 1 个数组. 本质上, 被接收的数据 "flips" 从一个缓冲到另一个, 期望不会溢出它们 2 个. 为试图阻止数据丢失, 一个 tty 驱动可以监视到来的数组多大, 并且, 如果它添满, 及时告知 tty 驱动在这个时刻刷新缓冲, 而不是等待下一个可用的机会
18.3. TTY线路设置

18.3.1. set_termios 函数
主要功能:
1)byte siz:CS5
2)奇偶值:PARENB/PARODD
3)停止位:CSTOPB
4)基本的流控类型,硬件和软件: CRTSCTS
5)波特率:B115200
18.3.2. tiocmget 和 tiocmset
调用来获得和设置不同的控制线路设置
18.4. ioctls函数

通用的 tty ioctls cmd列表:
1)TIOCSERGETLSR
获得这个 tty 设备的线路状态寄存器( LSR )的值.
2)TIOCGSERIAL
潜在地从 tty 设备获得许多串口线路信息
3)TIOCSSERIAL
设置串口线路信息.
4)TIOCMIWAIT
等待 MSR 改变. 用户在非寻常的情况下请求这个 ioctl, 它想在内核中睡眠直到这个 tty 设备的 MSR 寄存器发生某些事情.
5)TIOCGICOUNT
获得中断计数. 当用户要知道已经产生多少串口线中断时调用
18.5. TTY设备的proc和sysfs处理
1) read_proc 维护在 /proc/tty/driver 目录中文件.
2)tty_driver 结构体中flags来创建文件系统.

18.6. tty_driver 结构的细节(tty_driver.h)
见18.1.1.
18.7. tty_operaions 结构的细节(tty_driver.h)

int (*open)(struct tty_struct * tty, struct file * filp);
open 函数.
void (*close)(struct tty_struct * tty, struct file * filp);
close 函数.
int (*write)(struct tty_struct * tty, const unsigned char *buf, int count);
write 函数.
void (*put_char)(struct tty_struct *tty, unsigned char ch);
单字节写函数. 这个函数被 tty 核心调用当单个字节被写入设备. 如果一个 tty 驱动没有定义这个函数, write 函数被调用来替代, 当 tty 核心想发送一个单个字节.
void (*flush_chars)(struct tty_struct *tty);
void (*wait_until_sent)(struct tty_struct *tty, int timeout);
刷新数据到硬件的函数.
int (*write_room)(struct tty_struct *tty);
指示多少缓冲空闲的函数.
int (*chars_in_buffer)(struct tty_struct *tty);
指示多少缓冲满数据的函数.
int (*ioctl)(struct tty_struct *tty, struct file * file, unsigned int cmd, unsigned long arg);
ioctl 函数. 这个函数被 tty 核心调用, 当 ioctl(2)在设备节点上被调用时.
void (*set_termios)(struct tty_struct *tty, struct termios * old);
set_termios 函数. 这个函数被 tty 核心调用, 当设备的 termios 设置已被改变时.
void (*throttle)(struct tty_struct * tty);
void (*unthrottle)(struct tty_struct * tty);
数据抑制函数. 这些函数用来帮助控制 tty 核心的输入缓存. 这个抑制函数被调用当 tty 核心的输入缓冲满. tty 驱动应当试图通知设备不应当发送字符给它. unthrottle 函数被调用当 tty 核心的输入缓冲已被清空, 并且它现在可以接收更多数据. tty 驱动应当接着通知设备可以接收数据.
void (*stop)(struct tty_struct *tty);
void (*start)(struct tty_struct *tty);
stop 和 start 函数非常象 throttle 和 unthrottle 函数, 但是它们表示 tty 驱动应当停止发送数据给设备以及以后恢复发送数据.
void (*hangup)(struct tty_struct *tty);
挂起函数. 这个函数被调用当 tty 驱动应当挂起 tty 设备. 任何需要做的特殊的硬件操作应当在此时发生.
void (*break_ctl)(struct tty_struct *tty, int state);
线路中断控制函数. 这个函数被调用当这个 tty 驱动要打开或关闭线路的 BREAK 状态在 RS-232 端口上. 如果状态设为 -1, BREAK 状态应当打开. 如果状态设为 0, BREAK 状态应当关闭. 如果这个函数由 tty 驱动实现, tty 核心将处理 TCSBRK, TCSBRKP, TIOCSBRK, 和 TIOCCBRK ioctl. 否则, 这些 ioctls 被发送给驱动 ioctl 函数.
void (*flush_buffer)(struct tty_struct *tty);
刷新缓冲和丢失任何剩下的数据.
void (*set_ldisc)(struct tty_struct *tty);
设置线路规程的函数. 这个函数被调用当 tty 核心已改变这个 tty 驱动的线路规程. 这个函数通常不用并且不应当被一个驱动定义.
void (*send_xchar)(struct tty_struct *tty, char ch);
发送 X-类型 字符 的函数. 这个函数用来发送一个高优先级 XON 或者 XOFF 字符给 tty 设备. 要被发送的字符在 ch 变量中指定.
int (*read_proc)(char *page, char **start, off_t off, int count, int *eof, void *data);
int (*write_proc)(struct file *file, const char *buffer, unsigned long count, void *data);
/proc 读和写函数.version3.0 用 struct file_operation *proc_fops.
int (*tiocmget)(struct tty_struct *tty, struct file *file);
获得当前的特定 tty 设备的线路设置. 如果从 tty 设备成功获取到, 应当返回这个值给调用者.
int (*tiocmset)(struct tty_struct *tty, struct file *file, unsigned int set, unsigned int clear);
设置当前的特定 tty 设备的线路设置. set 和 clear 包含了去设置或者清除的不同的线路设置..
18.8. tty_struct 结构的细节(tty.h)



unsigned long flags;
tty 设备的当前状态. 这是一个位段变量, 并且通过下面的宏定义存取:
TTY_THROTTLED
当驱动以及有抑制函数被调用. 不应当被一个 tty 驱动设置, 只有 tty 核心.
TTY_IO_ERROR
由驱动设置当它不想任何数据被读出或写入驱动. 如果一个用户程序试图做这个, 它接收一个 -EIO 错误从内核中. 这常常在设备被关闭时设置.
TTY_OTHER_CLOSED
只由 pty 驱动使用来通知, 当端口已经被关闭.
TTY_EXCLUSIVE
由 tty 核心设置来指示一个端口在独占模式并且只能一次由一个用户存取.
TTY_DEBUG
内核中任何地方都不用.
TTY_DO_WRITE_WAKEUP
如果被设置, 线路规程的 write_wakeup 函数被允许来被调用. 常常在 tty_driver 调用 wake_up_interruptible 函数的同一时间被调用.
TTY_PUSH
只被缺省的 tty 线路规程内部使用.
TTY_CLOSING
tty 核心用来跟踪是否一个端口在那个时刻及时处于关闭过程.
TTY_DONT_FLIP
被缺省的 tty 线路规程用来通知 tty 核心, 它不应当改变 flip 缓冲, 当它被置位.
TTY_HW_COOK_OUT
如果被一个 tty 驱动设置, 它通知线路规程应当"烹调"发送给它的输出. 如果它没有设置, 线路规程成块拷贝驱动的输出; 否则, 它不得不为线路改变将单个发送的字节逐个求值. 这个标志应当通常不被 tty 驱动设置.
TTY_HW_COOK_IN
几乎和设置在驱动中的 flag 变量中的 TTY_DRIVER_REAL_RAW 标志一致. 这个标志通常应当不被 tty 驱动设置.
TTY_PTY_LOCK
pty 驱动用来加锁和解锁一个端口.
TTY_NO_WRITE_SPLIT
如果设置, tty 核心不将对 tty 驱动的写分成正常大小的块. 这个值不应当用来阻止对 tty 端口通过发送大量数据到端口的DoS攻击,
struct tty_flip_buffer flip;
给 tty 设备的 flip 缓冲.
struct tty_ldisc ldisc;
给 tty 设备的线路规程.
wait_queue_head_t write_wait;
给 tty 写函数的 wait_queue. 一个 tty 驱动应当唤醒它,当它可以接收更多数据时.
struct termios *termios;
指向 tty 设备的当前 termios 设置的指针.
unsigned char stopped:1;
指示是否 tty 设备被停止. tty 驱动可以设置这个值.
unsigned char hw_stopped:1;
指示是否 tty 设备的已经被停止. tty 驱动可以设置这个值.
unsigned char low_latency:1;
指示是否 tty 设备是一个低反应周期的设备, 能够高速接收数据. tty 驱动可以设置这个值.
unsigned char closing:1;
指示是否 tty 设备在关闭端口当中. tty 驱动可以设置这个值.
struct tty_driver driver;
当前控制这个 tty 设备的 tty_driver 结构.
void *driver_data;
指针, tty_driver 可以用来存储对于 tty 驱动本地的数据. 这个变量不被 tty 核心修改.
第二版本;65页/第三版17.6.