写博客是用来总结学习知识和成果的,本文为博主原创文章,未经博主允许不得转载,谢谢
软件性能测试大概包括以下几个方面:
一、性能测试理论基础
-
性能测试概念:
指通过自动化测试工具,模拟多种正常,峰值以及异常负载条件来对系统的各项性能指标进行测试。 -
性能测试的目的:
评价系统当前性能,判断系统是否满足预期的性能需求。
寻找软件系统可能存在的性能问题,定位性能瓶颈并解决问题。
判定软件系统的性能表现,预见系统负载压力承受力,在应用部署之前,评估系统性能。 -
性能测试包括什么:
负载测试,压力测试,容量测试。
1、负载测试(Load Testing):负载测试是一种主要为了测试软件系统是否达到需求文档设计的目标,譬如软件在一定时期内,最大支持多少并发用户数,软件请求出错率等,测试的主要是软件系统的性能。2、强度测试(Stress Testing):强度测试主要是为了测试硬件系统是否达到需求文档设计的性能目标,譬如在一定时期内,系统的cpu利用率,内存使用率,磁盘I/O吞吐率,网络吞吐量等,压力测试和负载测试最大的差别在于测试目的不同。
3、容量测试(Volume Testing):确定系统最大承受量,譬如系统最大用户数,最大存储量,最多处理的数据流量等。
二、性能测试术语与关键指标##
-
术语与关键指标:
资源指标:
1、CPU使用率:指用户进程与系统进程消耗的CPU时间百分比,长时间情况下,一般可接受上限不超过85%。
2、内存利用率:内存利用率=(1-空闲内存/总内存大小)*100%,一般至少有10%可用内存,内存使用率可接受上限为85%。
3、磁盘I/O: 磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘读写性能。
4、网络带宽:一般使用计数器Bytes Total/sec来度量,Bytes Total/sec表示为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
系统指标:
1、并发用户数:某一物理时刻同时向系统提交请求的用户数。
2、在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。
3、平均响应时间:系统处理事务的响应时间的平均值。事务的响应时间是从客户端提交访问请求到客户端接收到服务器响应所消耗的时间。对于系统快速响应类页面,一般响应时间为3秒左右。一般分为2、5、8s。
4、吞吐量:每秒钟系统能够处理的请求数、任务数。(吞吐量的指标受到响应时间、服务器软硬件配置、网络状态等多方面因素影响。)
5、超时错误率:主要指事务由于超时或系统内部其它错误导致失败占总事务的比率。
一个系统吞吐量经常由响应时间、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,cpu上下文切换,内存等等其他消耗导致系统性能下降。
-
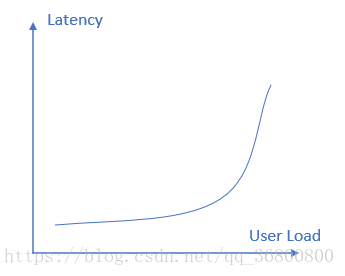
响应时间–负载对应关系:
响应时间突然增加,意味着系统的一种或多种资源利用达到极限。
-
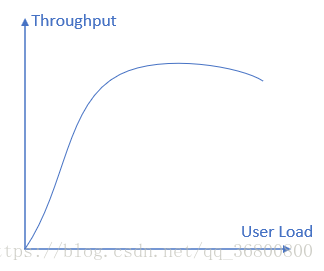
吞吐量–负载对应关系:
吞吐量逐渐达到饱和,意味着系统的一种或多种资源利用达到极限。
三、性能测试分类:
1、预期指标的性能测试
2、独立业务的性能测试:(1)在同一时刻进行完全一样的操作;(2)是在同一时刻使用完全一样的功能
3、组合业务性能测试
4、疲劳强度性能测试
5、大数据量性能测试
6、网络性能测试
7、服务器(操作系统,web服务器,数据库)性能测试
8、一些特殊的测试:配置,内存泄漏等
四、性能测试模型与流程
- 写脚本或者录制脚本
- 使用用户自定义参数
- 场景设计
- 使用控制器来模拟多少用户
- 使用监听器,查看测试结果
五、性能测试工具
- JMeter
- Loadrunner
六、性能监控与分析
详见https://blog.csdn.net/heyongluoyao8/article/details/51413668
七、系统性能定位与调优
- 性能瓶颈可能出现的地方有:网络(波动、延迟等/硬件资源(CPU/内存/缓存/IO读写)/数据库慢查询/线程死锁/异常等
- 瓶颈问题定位方法
网络(波动、延迟等):nmon网络监控,一般来说只需监控事务接入组件服务器的网络数据即可,其他内部组件一般都是属于局域网类型网络。
硬件资源(CPU/内存/缓存/IO读写):nmon硬件资源监控,需监控所有服务器资源(业务组件服务器/数据库服务器/MQ服务器等),经验上看最有可能出现问题的是业务组件服务器.
数据库慢查询:数据库慢查询配置,具体查看 http://www.cnblogs.com/echo-something/archive/2012/07/25/2607771.html
软件问题:先分析日志,查看大概的问题所处业务逻辑位置,再借助工具jstack(java后台)或者pstack(其他后台)记录各线程运行堆栈信息,查看分析线程等待(WAITING)状态原因 - 瓶颈优化方法
网络(波动、延迟等)
运维优化网络环境
硬件资源(CPU/内存/缓存/IO读写)
优化软件程序,重构复杂逻辑、递归,优化日志级别等
增加硬件配置
分布式部署
数据库慢查询
优化sql语句
重构业务逻辑
软件问题
优化程序逻辑
异步模式
八、性能架构,管理
常见性能瓶颈
- 吞吐量到上限时系统负载未到阈值:一般是被测服务分配的系统资源过少导致的。测试过程中如果发现此类情况,可以从ulimit、系统开启的线程数、分配的内存等维度定位问题原因
- CPU的us和sy不高,但wa很高:如果被测服务是磁盘IO密集型型服务,wa高属于正常现象。但如果不是此类服务,最可能导致wa高的原因有两个,一是服务对磁盘读写的业务逻辑有问题,读写频率过高,写入数据量过大,如不合理的数据载入策略、log过多等,都有可能导致这种问题。二是服务器内存不足,服务在swap分区不停的换入换出。
- 同一请求的响应时间忽大忽小:在正常吞吐量下发生此问题,可能的原因有两方面,一是服务对资源的加锁逻辑有问题,导致处理某些请求过程中花了大量的时间等待资源解锁;二是Linux本身分配给服务的资源有限,某些请求需要等待其他请求释放资源后才能继续执行。
- 内存持续上涨:在吞吐量固定的前提下,如果内存持续上涨,那么很有可能是被测服务存在明显的内存泄漏,需要使用valgrind等内存检查工具进行定位。
参考资料:https://www.cnblogs.com/puresoul/p/5456855.html
https://www.jianshu.com/p/d42dab4af1be
http://www.51testing.com/html/01/n-3959101.html