接上文SQL Server On Linux(1)——CentOS 7 安装SQL Server2019
在安装过程中,作者发现了一些信息,这些信息引起了作者的兴趣,那么下面作者把自己研究的结果分享出来,如果读者对此有深入研究过,欢迎指正。
为什么要研究这些东西?说白了就是为了Troubleshooting。当你的安装报错或者安装后启动失败时,这些信息可能会有所帮助,并且既然使用了Linux,那么不妨看看一些技术内幕,这些内容在Windows平台很难获得。
在上文中,安装过后会看到下图红框部分,这是第一个使作者感兴趣的地方,毕竟我也长期从事Windows平台的SQL Server:
然后就是检查服务状态时的第二个图:
本文重点讨论一下这两个图中的内容,其实它们本质上就是两个内容,第一个是ForceFlush,第二个就是symlink。

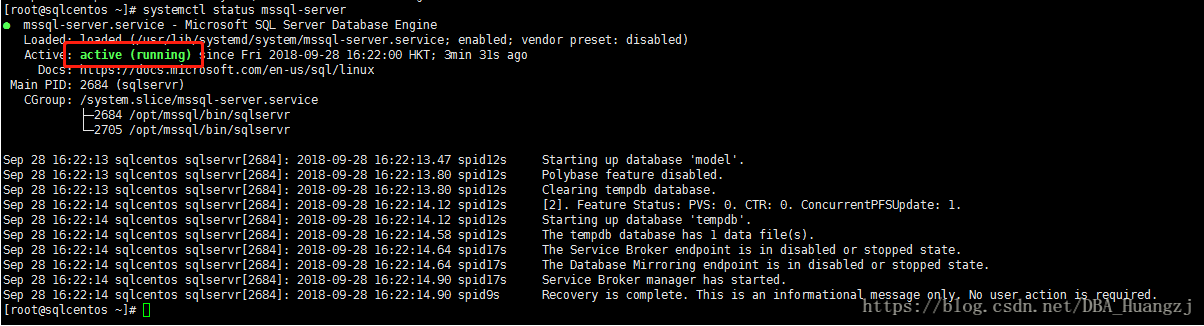
Forced Flush
暂且我们也叫强制刷新(flush也有译成冲刷),翻译倒是没所谓,建议搜索时尽可能使用英文原文。从图中可以看到原句是“ForceFlush feature is enabled for log durability”。这个是什么鬼?google一下(你做不到的话就bing一下,建议用国际版),会发现一篇微软的官方文档:Control Transaction Durability。这里作者重新整理一下里面的内容。
关系数据库事务日志原理
注意,从这里开始,作者已经不再是简单地做操作演示,而是在这个过程中嵌套很多SQL Server的知识,但是主要是为了自身的总结、巩固。
关系数据库的操作都产生事务日志,用于记录每个事务对数据库的操作。我们可以从逻辑上和物理上了解事务。
从逻辑层面,每个变更操作(如update、delete、insert等,还有DDL、索引表的变动等)都产生一个对于的事务,在用户角度看来这些操作可以是并行的,但是在事务产生的角度来看,只能是串行,每个事务有一个日志序列号(log sequence number,LSN)标识,每个新事务都追加到已有事务的尾部,并且新的LSN比前面的LSN更高。
从物理层面,SQL Server的每个库都最少包含数据文件(mdf/ndf)和日志文件(ldf),ldf文件是用于持久化存储事务日志,当系统出现奔溃时可以从中恢复数据(所以千万不要暴力删除。很可能你的数据库从此废掉)。虽然系统不会阻止你创建多个ldf文件,但是由于事务日志是串行的,实际上就是写满一个ldf再写另外一个ldf,因此多个ldf文件在绝大部分情况下是没有意义的,反而会带来管理麻烦。目前已知的唯一一个用处就是当原有的ldf文件已满甚至可能出现爆盘,却又无法进行常规的截断和收缩操作时,可以通过添加另外一个ldf来应急,注意这是应急操作。物理日志文件在使用时被分为多个虚拟日志文件(VLF),VLF没有固定大小,视乎事务的数量,SQL Server会尝试维护少量的VLF。VLF完全由SQL Server控制,VLF的创建逻辑如下:
- 下一次增长少于当前LDF物理大小的1/8,则创建1个VLF。从SQL 2014开始引入。
- 如果超过1/8,则使用SQL 2014之前的逻辑:
- 增长少于64MB,创建4个VLF。比如只增长1MB,那么创建4个256KB的VLF。
- 增长在64MB到1GB时,创建8个VLF。比如增长512MB,则为8个64MB的VLF。
- 增长大于1GB时,创建16个VLF。比如需要增长8GB,则创建16个512MB的VLF。
上面的逻辑读者看过就好,基本上没用处。反正作者没用到的时候。提到这个内容主要是为了下面这个常见的运维问题。
默认情况下SQL Server数据库的LDF自动增长设置为10%,对于LDF很大的情况下(比如已经有100GB,这已经不应该但是又经常在没有合理维护的系统中出现),那么10%将会一次性分配大量的空间。抛开可能导致已经存在压力的磁盘直接爆掉之外,事务日志文件是无法使用SQL Server即时文件初始化功能来快速初始化,比如以填充0的方式来扩容,试想要填充多少个0才够10GB(100G的10%),即使当前最快的磁盘,都需要用户足以察觉的时间来完成,这个时间大部分的SQL Server操作都处于等待状态,最终结果就是系统响应速度明显降低。所以通常来说,LDF的增长设置不要使用10%甚至百分比设置。应该使用以MB为单位的增长方式,不过到底多少最合适?这个跟实际系统繁忙程度和事务操作的规模有关系,如果系统的事务非常小但是很多,那么会产生很多VLF,因为数据库启动、日志备份/还原、高可用都需要扫描VLF,那么会导致整体过程非常慢(作者维护过一个事务复制环境,由于VLF到达几十万导致同步延时十几个小时)。但是如果LDF设置增长或初始化非常大而事务量非常小,那么VLF数量虽小但占用空间非常大。官方提供了一个很好的脚本Fix_VLFs大家不妨用一下。
另外如何设置日志文件,可以参考官方建议:管理日志文件建议
回到日常操作,当事务生成后,SQL Server会把事务(log record)写入内存的日志缓存(log cache),只有log cache中的信息写入到磁盘后,数据缓存中被修改过的数据(称为脏数据)才可以写入到磁盘。常规情况下,SQL Server使用检查点(checkpoints)来完成这个操作。
Checkpoint是一个后台进程,定期发起并扫描buffer中的脏数据,然后把所有脏数据写入磁盘。目的是减少恢复时需要redo(重做)或undo(回滚)的时间。这个操作也叫刷新页(flushing the page)。当以下情况出现时,checkpoint就会触发:
- 显式执行checkpoint语句:在当前数据库中触发检查点。
- 执行了最小日志操作:如使用大容量日志恢复模式的数据库执行大容量复制操作。
- 用ALTER DATABASE添加或删除数据库文件。
- 使用SHUTDOWN或停止SQL Server服务的方式停止SQL Server实例。都会产生一个checkpoint。
- SQL Server内部自动定期生成。
- 执行数据库备份。
- 关闭数据库的活动:如AUTO_CLOSE设为ON并最后一个用户断开连接时。
下面来看看自动检查点,自动检查点由SQL Server数据库引擎生成,根据日志空间使用情况和上一次checkpoint以来的时间间隔而定。如果很少修改,那么自动检查点的时间可能会很长,否则将很频繁,所以这个checkpoint可以从侧面去反映一个数据库的繁忙程度。但是注意不要以偏概全。特别注意在简单恢复模式下,当日志已满70%时可能出现checkpoint。不过内部机制比较负责,这里就不展开。
说了这么多,为的是介绍为什么要flush,因为事务日志极其重要,但是它首先是写入到内存的日志缓存中,由于内存的不稳定性,一旦出现异常,内存的信息将会丢失。所以需要把信息flush到磁盘,磁盘的信息能够尽可能保证持久存储。
假设现在使用的是SQL Server 2017 On Linux,Forced flush机制从SQL 2017 On Linux CU6开始引入,在某些情况下,SQL Server可能会遇到因为缓存出现问题导致的数据丢失。这些意外情况常见的有缓存数据写入磁盘之前就出现断电。为了尽量降低这种风险,forced flush应运而生。
Forced flush行为发生在数据库写入操作如checkpoint和事务日志写入期间。默认情况下,它有两个配置(writethrough和alternatewritethrough,默认值均为1),writethrough默认值的作用是SQL Server确保写操作已经持久地刷新(flushed,也可以理解为写入)到块设备中。而后者alternatewritethrough主要起到“优化”作用。下面简要说明一下这两个参数:
- writethrough :值为0或1,1 是将FILE_FLAG_WRITE_THROUGH 请求转换成O_DSYNC open,0 则是阻止这个行为。
- alternatewritethough :值为0或1,仅在writethrough为1时才可以设置为1,允许Host Extension对FILE_FLAG_WRITE_THROUGH 请求进行优化刷新,在文件上的写入操作被优化成对块设备的fdatasync调用。
使用跟踪标记3979可以禁用forced flush,同时使用mssql.conf使alternatewritethrough 和 writethrough选项设置0。mdf和ldf在SQL 2017 On Linux CU6中默认并不使用 writethrough 和 alternatewritethrough,跟踪标记只在forced flush生效时才禁用。在SQL SERVER中使用FILE_FLAG_WRITE_THROUGH 打开的其他文件,如快照、DBCC CHECKDB产生的内部快照、SQL Trace、扩展事件等,也会使用writethrough 和 alternatewritethrough。
前面一堆文字可能会看的比较头痛,但是这里列出来是为了做深入研究,那么研究什么?几个关键点:FILE_FLAG_WRITE_THROUGH、O_DSYNC open、fdatasync调用。
- FILE_FLAG_WRITE_THROUGH:这是win32中的API,就是我们常识中的通过缓存写入磁盘的行为。
- O_DSYNC:是系统调用Open操作(打开文件)时的选项,意味着当写入时只有写到磁盘才算成功。
- fdatasync:在数据写入文件时,通常使用的是fsync,你可以理解为完全写入后才返回成功。而fdatasync作为“优化”,只需要确认数据写入而不需要等待元数据等信息写入完成就可返回成功。这个类似异步写入的方式。
总结来说,ForceFlush通过把Windows上的API——FILE_FLAG_WRITE_THROUGH转换成Linux的O_DSYNC调用进行强制刷新,如果alternatewritethough被启用,那么这种行为将变成异步。前面提到,Forced flush行为发生在数据库写入操作如checkpoint和事务日志写入期间,而Checkpoint本身就具有flush功能,所以更重点的是在事务日志写入时,就会随之写入磁盘,确保事务的安全性。
建议:如果存储系统不能在断电出现时保证数据完整地、持久地写入,那么建议使用SQL 2017 CU6及以上版本并启用该功能。
symlink
接下来看看第二个细节,symlink。说到这里,我们先来了解一下systemctl这个Linux上的命令,这个命令在SQL On Linux上会被广泛地使用。
在Linux中,Systemd是一个标准的系统初始化进程和系统管理进程。但是毕竟systemd是“进程”,我们对其进行管理时还是需要命令,这个命令就是systemctl。这个命令主要用于管理服务,对于SQL Server来说,就是对引擎服务进行以下操作,注意需要特权操作(如果不是root用户则需要加sudo)
- 开启和停止:
sudo systemctl start application.service和sudo systemctl stop application.service,其中application是服务名,如SQL Server中的mssql-server。后面的.service可有可无,systemctl会自动识别。 - 重启服务:
sudo systemctl restart application.service。 - 启用和禁用:
sudo systemctl enable application.service和sudo systemctl disable application.service,启用和禁用意味着在服务器启动时是否一并启用,一般正式环境下通常对数据库服务都会设置自动启动。这就需要enable服务。启用服务会创建一个symbolic链接(也就是symlink),指向服务文件(通常是在/lib/sysemd/system或/etc/systemd/system),systemd会寻找自动启动文件(通常在/etc/systemd/system/下)。如果禁用服务,则会移除这个链接。这就是本文第一个图的第二行的含义所在。 - 检查状态:
sudo systemctl status application.service。执行之后可以看到本文第二个图的样子。另外3个类似的命令见下图:
到目前为止,基本上搞清楚了安装过程的两个“疑惑”点,作者暂时不打算研究太深,毕竟作者的目标是SQL Server,所以本文到此为止。下面的表可能在后续会使用到,放在这里备用。

总结
本文的目的在于列出两个在作者安装SQL Server On Linux过程中发现的疑惑点,由于作者一直从事Windows上的SQL Server工作,所以对于某些读者来说可能这个并不值得深究,但是作者觉得学习过程有余力就应该学深入一点,并且要具有一定的怀疑习惯。
总得来说,ForceFlush是为了让SQL Server 2017 On Linux(CU6+)能尽快地把事务日志刷新到磁盘确保事务的持久性而出现的。而创建symlink的目的则是使Linux在启动操作系统时一并启动SQL Server服务。
下一篇文章作者打算演示一下示例数据库的准备工作。SQL Server On Linux(3)——SQL Server 2019 For Linux 下载并部署示例数据库
命令总结
服务管理:
- 开启和停止服务:
sudo systemctl start application.service和sudo systemctl stop application.service - 重启服务:
sudo systemctl restart application.service - 启用和禁用:
sudo systemctl enable application.service和sudo systemctl disable application.service - 查看服务状态:
sudo systemctl status application.service