RabbitMQ:消息队列
PY里的队列有:线程QUEUE、进程QUEUE
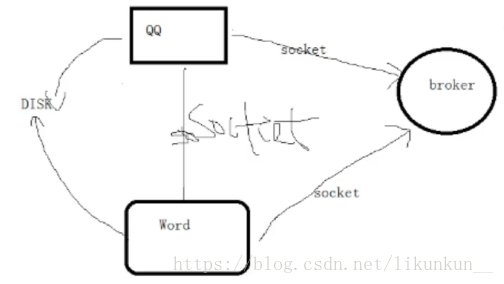
进程queue可以用于父进程与子进程进行交互,或者同属于一父进程下多个子进程进行交互,但如果是两个独立的程序,是不能用这个QUEUE进行通讯的。
两个独立的程序之间,要找一个中间代理,比如可以用socket通讯,或者用json通讯(放在硬盘上,然后在读取,速度慢),还有就是RabbitMQ消息队列。
这个中间代理的好处在于:
1、完全封装好,不用考虑消息的处理。
2、可以多个消息之间建立连接,而不必每两个程序就要建立socket连接。
中间代理代表是rabbitMQ。
RabbitMQ在python里的调用模块是pika
基本用法如下面:
生产者:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel = connection.channel() #声明一个管道
#在管道里,再声明queue
channel.queue_declare(queue='hello',
# durable=True #durable=True为队列持续化
)
#真正发消息,用管道发
channel.basic_publish(exchange='',
routing_key='hello', #消息队列名称
body='Hello World!', #消息内容
# properties=pika.BasicProperties(delivery_mode=2,) #消息持续化
)
print('[x] sent "Hello World!"')
connection.close()
消费者:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel = connection.channel()
#这里再次声明从那个队列去收消息(可以不写,但必须要有这个队列,不然会报错)
channel.queue_declare(queue='hello',
# durable=True #durable=True为队列持续化
)
def callback(ch, method, properties, body):
print('[x] 收到%r'%body)
# 给队列发一个确认执行完的信息,否则消息会保存起来,不会被消费掉,会转给下个消费者
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
callback,
queue='hello',
# no_ack=True #取消发送消息中断处理功能,不管有没有处理完,都不会给服务器端发确认
)
print('[*] Waiting for messages. Toexit press CTRL+C')
channel.start_consuming()生产消费者模型默认是轮询处理机制:如果有3个消费者,一个生产者,则是先给第一个启动的消费者,在给第二个……
回调函数(callback函数):表示消息来了就调这个函数。
有的时候发送消息,会中断,那么RabbitMQ会有处理机制:在回调函数最后加上ch.basic_ack(delivery_tag=method.delivery_tag),RabbitMQ在函数没处理完就中断的话,消息会保存起来,不会被消费掉,会转给下个消费者。取消这个功能代码是:no_ack=True,代表不管有没有处理完,都不会给服务器端发确认(在服务器端不关心消息有没有处理完的时候用)。
在sbin目录下ctl是管理队列的工具。命令行用rabbitmqctl.bat list_queues可以看到队列和他的消息有多少个。
如果服务器突然断开了,那么怎么办呢。在每次声明队列的时候,加上队列持续化durable=True。和消息持续化:

怎么样能够根据cpu处理速度调整发多少消息呢?
在消费者的basic_consume方法前面加上:

怎么吧一条消息发给所有人(广播)?
要用到exchange:
发布方:要定义exchange,类型是fanout。
channel.exchange_declare(exchange='logs', type='fanout')完整代码如下
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', type='fanout')
message = "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()接受方:直接看完整代码
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
#这里是一样的定义exchange
channel.exchange_declare(exchange='logs',
type='fanout')
#消费者还是要有一个queue,这里声明一个随机queue
# 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue #拿到queue
#然后要bind一个exchange,后面就可以开始收了
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
如果想要选择性的接收:接收方的type换成direct就行
Rpc:发一条消息到远程机器去执行,然后吧执行结果返回,这种模式叫rpc(remote procedure call)