Shell编程
1、简单介绍
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。Shell 编程跟 java、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。简单地讲,shell编程就是对一堆Linux命令的逻辑化处理。
在计算机科学中,Shell俗称壳(用来区别于核),是指“提供使用者使用界面”的软件(命令解析器)。它类似于DOS下的command。com和后来的cmd。exe。它接收用户命令,然后调用相应的应用程序。
文字操作系统与外部最主要的接口就叫做shell。shell是操作系统最外面的一层。shell管理你与操作系统之间的交互:等待你输入,向操作系统解释你的输入,并且处理各种各样的操作系统的输出结果。
同时它又是一种程序设计语言。作为命令语言,它交互式解释和执行用户输入的命令或者自动地解释和执行预先设定好的一连串的命令;作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
在排序算法中,Shell是希尔排序的名称。
Shell注释:
以"#"开头的行就是注释,会被解释器忽略。

sh里没有多行注释,只能每一行加一个#号。
示例1
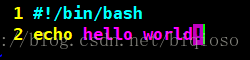
第一行表示选择使用bash shell。在shell中,#符号表示注释。但是shell的第一行比较特殊,一般都会以#!开始来告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。在linux中,bash shell使用是最多的。
第二行的echo命令用于向窗口输出文本。,在这里就是输出hello world。
Shell程序文件在创建之后(如hello_world.sh,一般将shell保存为xxx.sh看起来会直观一些),要赋予此文件的可执行权限。
输入命令:chmod +x hello_world.sh #使脚本具有执行权限
然后执行:./hello_world.sh #执行权限
执行时,文件前面一定要加./,告诉系统就在当前目录找,运行其他二进制程序也一样。因为直接写文件名的话,linux系统回去PATH里面的路径找,通常当前目录是没有加到PATH里面的。
示例2
#!/bin/bash
#自定义变量hello
hello="hello world"
#使用自定义变量
echo $hello
#使用环境变量
echo $PATH
#添加/home/hzj/bin到PATH环境变量
PATH=$PATH:/home/hzj/bin
#使用环境变量
echo $PATH
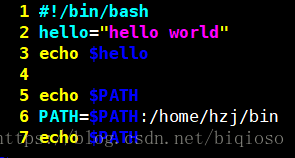
执行./test.sh

注意:定义变量不用$符号,使用变量要加$。定义变量的时候,“=”左右千万不要有空格。
第二行在自定义变量时,使用了双引号,在shell编程中,如果变量出现了空格或者引号,那么也必须加引号,否则就可以省略。如果没有单引号或双引号,shell会把空格后的字符串解释为命令。这样基本就会出错。
第五行显示当前PATH环境变量,该变量的值又一系列冒号分隔的目录名组成。如:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games。当我们执行程序时,shell自动跟据PATH变量的值去搜索该程序。
第六行是添加/home/hzj/bin到PATH环境变量。
示例3
这个表示将pwd执行结果(当前所在目录)赋值给path变量。
2、Shell变量
1、Bourne shell有如下四种变量
用户自定义变量
位置变量,即命令行参数
预定义变量
环境变量
2、自定义变量
有以下几点规则:
1)命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
2)中间不能有空格,可以使用下划线(_)
3)不能使用标点符号
4)不能使用bash里的关键字(可用help命令查看保留关键字)。
5)变量名和等号之间不能有空格
3、位置变量,即命令行参数
$0 与键入的命令行一样,包含脚本文件名
$1, $2, ……,$9 分别包含第一个到第九个命令行参数
$# 包含命令行参数的个数
$@ 包含所有命令行参数: “$1, $2, ……,$9”会一个一个拆分解析
$? 包含前一个命令的退出状态
$* 包含所有命令行参数: “$1, $2, ……,$9”所有包括在一起解析的
$$ 包含正在执行进程的ID号
4、环境变量
HOME : /etc/passwd文件中列出的用户主目录
IFS: Internal Field Separator,默认为空格,tab及换行符
PATH: shell 搜索路径
PS1, PS2: 默认提示符($)及换行提示符( > )
TERM: 终端类型,常用的有vt100, ansi, vt200, xterm等
这类变量是linux已定义的,我们可以直接使用。
5、使用变量
使用变量很简单。$符号加上变量名就可以了。
如:
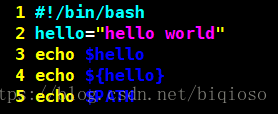
第四行的变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界推荐给所有变量加上花括号,这是个好的编程习惯。
6、只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
如:
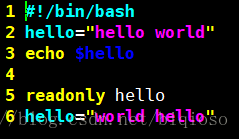
执行之后会报错:

7、删除变量
使用unset命令可以删除变量,变量被删除后不能再次使用。
如:

执行之后没有任何输出。
注意: unset 命令不能删除只读变量
8、变量类型
运行shell时,会同时存在三种变量:
1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
2) 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
3) shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
9、shell字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。单双引号的区别跟PHP类似。
1)单引号
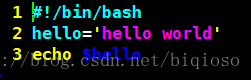
规则:
单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
单引号字串中不能出现单引号(对单引号使用转义符后也不行)。
2)双引号
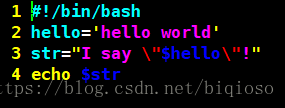
执行结果:
优点:
双引号里可以有变量
双引号里可以出现转义字符
3)拼接字符串
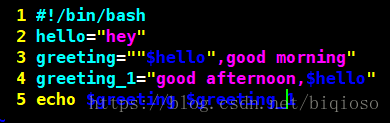
执行结果:

4)获取字符串
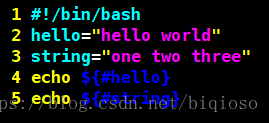
执行结果:

5)提取子字符串
从字符串第三个字符开始截取6个字符
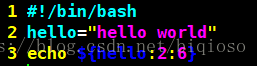
执行结果:
6)查找子字符串
查找字符“w”的位置
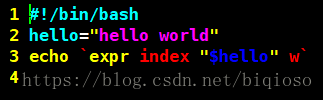
执行结果:
注意:脚本中是反引号`,这个符号在tab键上面,并且要在英文模式下使用。
3、shell传递参数
在执行 Shell 脚本时,可以向脚本传递参数,脚本内获取参数的格式为:$n。.n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……
示例:
test.sh文件内容为

执行输入:./test.sh 1 2
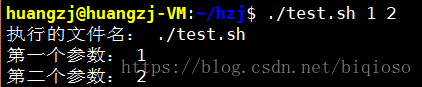
以上就是向脚本传递了两个参数并输出,其中$0为执行的文件名。
还有其他的参数处理:
$0 与键入的命令行一样,包含脚本文件名
$1, $2, ……,$9 分别包含第一个到第九个命令行参数
$# 包含命令行参数的个数
$@ 包含所有命令行参数: “$1, $2, ……,$9”会一个一个拆分解析
$? 包含前一个命令的退出状态
$* 包含所有命令行参数: “$1, $2, ……, $9”所有包括在一起解析的
$$ 包含正在执行进程的ID号
$*与 $@ 区别:
相同点:都是引用所有参数。
不同点:只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3,,则 " * " 等价于 "1 2 3"(传递了一个参数),而 "@" 等价于 "1" "2" "3"(传递了三个参数)。
4、shell数组
bash支持一维数组(不支持多维数组),初始化时不需要定义数组大小(与 PHP 类似)。与C语言类似,数组元素的下标由0开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于0。Shell 数组用括号来表示,元素用空格符号分割开
1)定义数组
在Shell中,用括号来表示数组,数组元素用"空格"符号分割开。
数组名=(值1 值2 值3 … 值n)
如:array_name=(value0 value1 value2)
my_array=(A B "C" D)
也可以单独定义数组的各个分量:
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen
可以不使用连续的下标,而且下标的范围没有限制。
2)读取数组
${数组名[下标]}
${array_name[index]}
如:value=${array_name[n]}
使用@或*符号可以获取数组中的所有元素
如:echo ${array_name[@]}
echo ${array_name[*]}
3)获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}
示例:

执行结果:

5、shell基本运算符
1、运算符种类:
算数运算符
关系运算符
布尔运算符
字符串运算符
文件测试运算符
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
如:
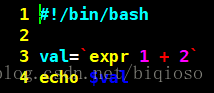
执行结果:
注意:
表达式和运算符之间要有空格,例如 1+2 是不对的,必须写成1 + 2。
完整的表达式要被 ` ` 包含,注意这个字符不是常用的单引号,使用的是反引号 `,在 Esc 键下边。
2、算术运算符
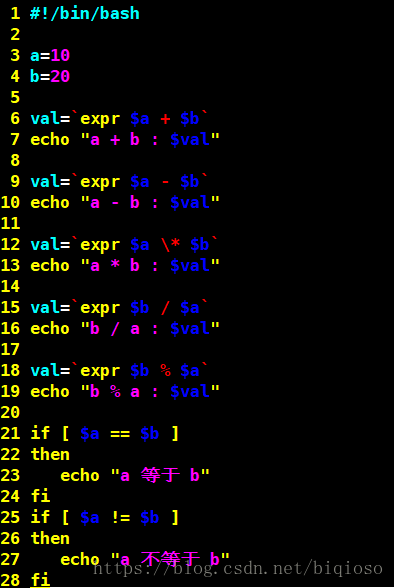
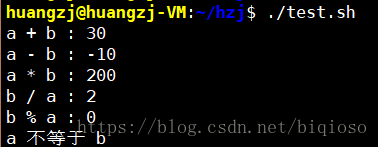
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 |
说明 |
举例 |
| + |
加法 |
`expr $a + $b` 结果为 30。 |
| - |
减法 |
`expr $a - $b` 结果为 -10。 |
| * |
乘法 |
`expr $a \* $b` 结果为 200。 |
| / |
除法 |
`expr $b / $a` 结果为 2。 |
| % |
取余 |
`expr $b % $a` 结果为 0。 |
| = |
赋值 |
a=$b 将把变量 b 的值赋给 a。 |
| == |
相等。用于比较两个数字,相同则返回 true。 |
[ $a == $b ] 返回 false。 |
| != |
不相等。用于比较两个数字,不相同则返回 true。 |
[ $a != $b ] 返回 true。 |
注意:
1、条件表达式要放在方括号之间,并且要有空格,例如: [$a==$b] 是错误的,必须写成 [ $a == $b ]。
2、乘号(*)前边必须加反斜杠(\)才能实现乘法运算
示例:
执行结果:
3、关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
| 运算符 |
说明 |
举例 |
| -eq |
检测两个数是否相等,相等返回 true。 |
[ $a -eq $b ] 返回 false。 |
| -ne |
检测两个数是否相等,不相等返回 true。 |
[ $a -ne $b ] 返回 true。 |
| -gt |
检测左边的数是否大于右边的,如果是,则返回 true。 |
[ $a -gt $b ] 返回 false。 |
| -lt |
检测左边的数是否小于右边的,如果是,则返回 true。 |
[ $a -lt $b ] 返回 true。 |
| -ge |
检测左边的数是否大于等于右边的,如果是,则返回 true。 |
[ $a -ge $b ] 返回 false。 |
| -le |
检测左边的数是否小于等于右边的,如果是,则返回 true。 |
[ $a -le $b ] 返回 true。 |
4、布尔运算符
| 运算符 |
说明 |
举例 |
| ! |
非运算,表达式为 true 则返回 false,否则返回 true。 |
[ ! false ] 返回 true。 |
| -o |
或运算,有一个表达式为 true 则返回 true。 |
[ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a |
与运算,两个表达式都为 true 才返回 true。 |
[ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
5、逻辑运算符
| 运算符 |
说明 |
举例 |
| && |
逻辑的 AND |
[[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || |
逻辑的 OR |
[[ $a -lt 100 || $b -gt 100 ]] 返回 true |
6、字符串运算符
| 运算符 |
说明 |
举例 |
| = |
检测两个字符串是否相等,相等返回 true。 |
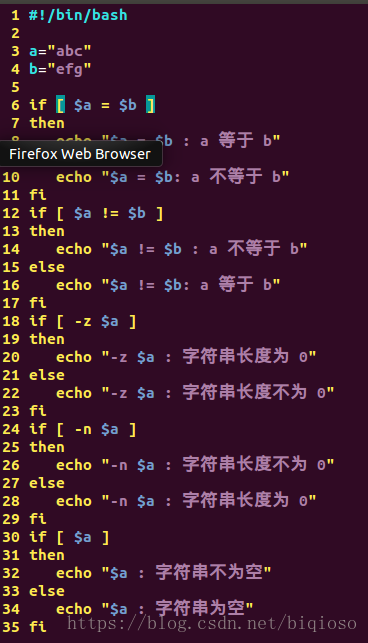
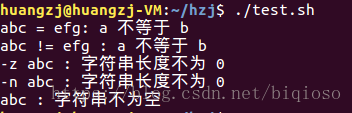
[ $a = $b ] 返回 false。 |
| != |
检测两个字符串是否相等,不相等返回 true。 |
[ $a != $b ] 返回 true。 |
| -z |
检测字符串长度是否为0,为0返回 true。 |
[ -z $a ] 返回 false。 |
| -n |
检测字符串长度是否为0,不为0返回 true。 |
[ -n $a ] 返回 true。 |
| str |
检测字符串是否为空,不为空返回 true。 |
[ $a ] 返回 true。 |
注意:将字符串运算符“=”与算术运算符的“==”区分,“==”是用于比较两个数字,“=”是用于比较两个字符串。
示例
执行结果
7、文件测试运算符
| 操作符 |
说明 |
举例 |
| -b file |
检测文件是否是块设备文件,如果是,则返回 true。 |
[ -b $file ] 返回 false。 |
| -c file |
检测文件是否是字符设备文件,如果是,则返回 true。 |
[ -c $file ] 返回 false。 |
| -d file |
检测文件是否是目录,如果是,则返回 true。 |
[ -d $file ] 返回 false。 |
| -f file |
检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 |
[ -f $file ] 返回 true。 |
| -g file |
检测文件是否设置了 SGID 位,如果是,则返回 true。 |
[ -g $file ] 返回 false。 |
| -k file |
检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 |
[ -k $file ] 返回 false。 |
| -p file |
检测文件是否是有名管道,如果是,则返回 true。 |
[ -p $file ] 返回 false。 |
| -u file |
检测文件是否设置了 SUID 位,如果是,则返回 true。 |
[ -u $file ] 返回 false。 |
| -r file |
检测文件是否可读,如果是,则返回 true。 |
[ -r $file ] 返回 true。 |
| -w file |
检测文件是否可写,如果是,则返回 true。 |
[ -w $file ] 返回 true。 |
| -x file |
检测文件是否可执行,如果是,则返回 true。 |
[ -x $file ] 返回 true。 |
| -s file |
检测文件是否为空(文件大小是否大于0),不为空返回 true。 |
[ -s $file ] 返回 true。 |
| -e file |
检测文件(包括目录)是否存在,如果是,则返回 true。 |
[ -e $file ] 返回 true。 |
6、shell echo命令
Shell 的 echo 指令与 PHP 的 echo 指令类似,都是用于字符串的输出。
1。显示普通字符串
echo "It is a test"
这里的双引号完全可以省略,以下命令与上面实例效果一致:
echo It is a test
2。显示转义字符
echo "\"It is a test\""
执行结果:
"It is a test"
同样,双引号也可以省略
3。显示变量
read 命令从标准输入中读取一行,并把输入行的每个字段的值指定给 shell 变量。如果执行read语句时标准输入无数据,则程序在此停留等候,知道数据的到来或被终止运行
如:
#!/bin/sh
read name
echo "$name It is a test"
这里的name 是接收标准输入的变量
执行结果:
hahaha #标准输入
hahaha It is a test #输出
示例

执行结果:

4。显示换行
echo -e "OK! \n" # -e 开启转义
echo "It it a test"
输出结果:
OK!
It it a test
5。显示不换行
#!/bin/sh
echo -e "OK! \c" # -e 开启转义 \c 表示不换行
echo "It is a test"
输出结果:
OK! It is a test
6。显示结果定向至文件
echo "It is a test" > myfile
7。原样输出字符串,不进行转义或取变量(用单引号)
echo '$name\"'
输出结果:
$name\"
上面的结果说明了“$”这个取变量符号失去了它的功能,只是把它当做一个字符直接输出。
8。显示命令执行结果
echo `date`
注意: 这里使用的是反引号 `, 而不是单引号 '。
结果将显示当前日期
2018年 03月 30日 星期五 18:42:11 CST
7、shell的printf命令
printf 命令模仿 C 程序库(library)里的 printf() 程序。
printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。
printf 使用引用文本或空格分隔的参数,外面可以在 printf 中使用格式化字符串,还可以制定字符串的宽度、左右对齐方式等。默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf 命令的语法:
printf format-string [arguments…]
参数说明:
format-string: 为格式控制字符串
arguments: 为参数列表。
示例
#!/bin/bash
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876
执行脚本,输出结果如下所示:
姓名 性别 体重kg
郭靖 男 66.12
杨过 男 48.65
郭芙 女 47.99
%s %c %d %f都是格式替代符
%-10s 指一个宽度为10个字符(-表示左对齐,没有则表示右对齐),任何字符都会被显示在10个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中.2指保留2位小数。
%d %s %c %f 格式替代符详解:
d: Decimal 十进制整数 -- 对应位置参数必须是十进制整数,否则报错!
s: String 字符串 -- 对应位置参数必须是字符串或者字符型,否则报错!
c: Char 字符 -- 对应位置参数必须是字符串或者字符型,否则报错!
f: Float 浮点 -- 对应位置参数必须是数字型,否则报错
Printf的转义序列
| 序列 |
说明 |
| \a |
警告字符,通常为ASCII的BEL字符 |
| \b |
后退 |
| \c |
抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略 |
| \f |
换页(formfeed) |
| \n |
换行 |
| \r |
回车(Carriage return) |
| \t |
水平制表符 |
| \v |
垂直制表符 |
| \\ |
一个字面上的反斜杠字符 |
| \ddd |
表示1到3位数八进制值的字符。仅在格式字符串中有效 |
| \0ddd |
表示1到3位的八进制值字符 |
8、shell的test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
每种测试对象都有若干测试操作符
例如:
test “$answer”= “yes”
变量answer的值是否为字符串yes
test $num -eq 18
变量num的值是否为整数18
test –d tmp
测试tmp是否为一个目录名
1、数值测试
| 参数 |
说明 |
| -eq |
等于则为真 |
| -ne |
不等于则为真 |
| -gt |
大于则为真 |
| -ge |
大于等于则为真 |
| -lt |
小于则为真 |
| -le |
小于等于则为真 |
示例:

执行结果:
注意:代码中的 [] 执行基本的算数运算,如:
#!/bin/bash
a=5
b=6
result=$[a+b] # 注意等号两边不能有空格
echo "result 为: $result"
执行结果:
result 为: 11
2、字符串测试
| 参数 |
说明 |
| = |
等于则为真 |
| != |
不相等则为真 |
| -z 字符串 |
字符串的长度为零则为真 |
| -n 字符串 |
字符串的长度不为零则为真 |
示例:
num1="ru1noob"
num2="runoob"
if test $num1 = $num2
then
echo '两个字符串相等!'
else
echo '两个字符串不相等!'
fi
输出结果:
两个字符串不相等!
3、文件测试
| 参数 |
说明 |
| -e 文件名 |
如果文件存在则为真 |
| -r 文件名 |
如果文件存在且可读则为真 |
| -w 文件名 |
如果文件存在且可写则为真 |
| -x 文件名 |
如果文件存在且可执行则为真 |
| -s 文件名 |
如果文件存在且至少有一个字符则为真 |
| -d 文件名 |
如果文件存在且为目录则为真 |
| -f 文件名 |
如果文件存在且为普通文件则为真 |
| -c 文件名 |
如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 |
如果文件存在且为块特殊文件则为真 |
示例:
if test -e ./bash
then
echo '文件已存在!'
else
echo '文件不存在!'
fi
输出结果:
文件已存在!
Shell还提供了与( -a )、或( -o )、非( ! )三个逻辑操作符用于将测试条件连接起来,其优先级为:"!"最高,"-a"次之,"-o"最低。
例如:
if test -e ./notFile -o -e ./bash
then
echo '至少有一个文件存在!'
else
echo '两个文件都不存在'
fi
输出结果:
至少有一个文件存在!
9、shell流程控制
1、if…then…fi
格式:
if condition
then
command1
command2
...
commandN
fi
写成一行(适用于终端命令提示符):
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi
末尾的fi就是if倒过来拼写
2、if…then…else…fi
格式:
if condition
then
command1
command2
...
commandN
else
command
fi
示例
if else语句经常与test命令结合使用

执行结果
3、if…then…else-if…then…else…fi
格式:
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
示例

执行结果
4、for…do…done
格式:
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
写成一行:
for var in item1 item2 ... itemN; do command1; command2… done;
当变量值在列表里,for循环即执行一次所有命令,使用变量名获取列表中的当前取值。命令可为任何有效的shell命令和语句。in列表可以包含替换、字符串和文件名。
in列表是可选的,如果不用它,for循环使用命令行的位置参数。
示例1
顺序输出当前列表中的数字

执行结果

示例2
顺序输出字符串中的字符

执行结果
5、while…do…done
while循环用于不断执行一系列命令,也用于从输入文件中读取数据;命令通常为测试条件。while语句的退出状态为命令表中被执行行的最后一条命令的推出状态。
格式:
while condition
do
command
done
示例

执行结果

上面使用中使用了 Bash let 命令,它用于执行一个或多个表达式,变量计算中不需要加上 $ 来表示变量
6、无限循环
格式:
while :
do
command
done
或者
while true
do
command
done
或者
for (( ; ; ))
7、until…do…done
until循环执行一系列命令直至条件为真时停止。
until循环与while循环在处理方式上刚好相反。
一般while循环优于until循环,但在某些时候—也只是极少数情况下,until循环更加有用。
格式:
until condition
do
command
done
条件可为任意测试条件,测试发生在循环末尾,因此循环至少执行一次。
8、case…esac
Shell case语句为多选择语句。可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。
格式:
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
注意:
取值后面必须为单词in,每一模式必须以右括号结束。取值可以为变量或常数。匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。既然取值可以为变量,那么模式也就可以为变量的值,不一定是常数。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不再继续其他模式。如果无一匹配模式,使用星号 * 捕获该值,再执行后面的命令。
case语句只能检测字符串变量
各模式中可用文件名元字符,以有括号结束
命令表以单独的双分号行结束,退出case语句
模式n常写为字符* 表示所有其它模式
最后一个双分号行可以省略
示例:

执行结果

9、跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用两个命令来实现该功能:break和continue。
1)break命令
break命令允许跳出所有循环(终止执行后面的所有循环)。
示例
执行结果
2)continue命令
continue命令与break命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。
示例
执行结果
可以看到,这个程序的循环不会结束,永远不会执行 echo“游戏结束” 这条语句。
10、shell函数
linux shell 可以用户定义函数,然后在shell脚本中可以随便调用。
函数定义格式
[ function ] funname [()]
{
action;
[return int;]
}
说明
1、可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
2、参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255)。函数不需要指定是返回什么类型。
示例1
执行结果
示例2
下面这个函数是带有return语句的函数
执行结果
函数返回值在调用该函数后通过 $? 来获得。
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数...
示例
执行结果
注意:$10 不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用${n}来获取参数。
几个特殊字符用来处理参数:
| 参数处理 |
说明 |
| $# |
传递到脚本的参数个数 |
| $* |
以一个单字符串显示所有向脚本传递的参数 |
| $$ |
脚本运行的当前进程ID号 |
| $! |
后台运行的最后一个进程的ID号 |
| $@ |
与$*相同,但是使用时加引号,并在引号中返回每个参数。 |
| $- |
显示Shell使用的当前选项,与set命令功能相同。 |
| $? |
显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
11、shell输入/输出重定向
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端。
重定向命令列表如下:
| 命令 |
说明 |
| command > file |
将输出重定向到 file。 |
| command < file |
将输入重定向到 file。 |
| command >> file |
将输出以追加的方式重定向到 file。 |
| n > file |
将文件描述符为 n 的文件重定向到 file。 |
| n >> file |
将文件描述符为 n 的文件以追加的方式重定向到 file。 |
| n >& m |
将输出文件 m 和 n 合并。 |
| n <& m |
将输入文件 m 和 n 合并。 |
| << tag |
将开始标记 tag 和结束标记 tag 之间的内容作为输入。 |
注意:文件描述符 0 通常是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
输出重定向
重定向一般通过在命令间插入特定的符号来实现。
格式:
command1 > file1
上面这个命令执行command1然后将输出的内容存入file1。
注意任何file1内的已经存在的内容将被新内容替代。如果要将新内容添加在文件末尾,请使用>>操作符。
输入重定向
和输出重定向一样,Unix 命令也可以从文件获取输入
格式:
command1 < file1
这样,本来需要从键盘获取输入的命令会转移到文件读取内容。
注意:输出重定向是大于号(>),输入重定向是小于号(<)。
command1 < infile > outfile
同时替换输入和输出,执行command1,从文件infile读取内容,然后将输出写入到outfile中。
重定向深入讲解
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
默认情况下,command > file 将 stdout 重定向到 file,command < file 将stdin 重定向到 file。
如果希望 stderr 重定向到 file,可以这样写:
$ command 2 > file
如果希望 stderr 追加到 file 文件末尾,可以这样写:
$ command 2 >> file
2 表示标准错误文件(stderr)。
如果希望将 stdout 和 stderr 合并后重定向到 file,可以这样写:
$ command > file 2>&1
或者
$ command >> file 2>&1
如果希望对 stdin 和 stdout 都重定向,可以这样写:
$ command < file1 >file2
command 命令将 stdin 重定向到 file1,将 stdout 重定向到 file2。
Here Document
Here Document 是 Shell 中的一种特殊的重定向方式,用来将输入重定向到一个交互式 Shell 脚本或程序。
格式:
command << delimiter
document
delimiter
它的作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。
注意:
1、结尾的delimiter 一定要顶格写,前面不能有任何字符,后面也不能有任何字符,包括空格和 tab 缩进。
2、开始的delimiter前后的空格会被忽略掉。
/dev/null 文件
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null
输入:
$ command > /dev/null
/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到"禁止输出"的效果。
如果希望屏蔽 stdout 和 stderr,可以这样写:
$ command > /dev/null 2>&1
注意:0 是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
12、shell文件包含
和其他语言一样,Shell 也可以包含外部脚本。这样可以很方便的封装一些公用的代码作为一个独立的文件。
格式:
. filename # 注意点号(.)和文件名中间有一空格
或
source filename
在一个文件中添加这样的语句,就可以将另一个文件包含进去。
注意:被包含的文件不需要可执行权限。
13、其他
1、shell的分号“;”:分号是用来隔断每个语法关键字或命令的 。对于字符的比较及其他shell语法关键字之间分号的使用方式相同。需要知道的是在不同的语法命令之间要用分号隔开或是换行方能执行,否则将会在调用脚本的时候报错。
2、if语句后的表达式比较变量要与比较操作符用空格分开。
3、Shell中用arrary=(arr1 arr2 arr3 ……) 的方式声明数组
访问数组时使用${arrary[@]}访问整个数组 ,@表示数组索引表,使用${p[index]}访问数组中的某个特定的值
4、变量赋值时变量名跟等号之间不能有空格
5、$# ——传给shell程序的位置参数个数;$0 ——脚本名称;$? ——最后命令的完成码或在shell程序内所执行的shell程序;$n (n>0)——获取传递的第n个参数
6、 cd /opt/tomcat/tomcat*0 * 号代表匹配0..n个字符;
cd /opt/tomcat/to?cat ? 号代表匹配1个字符
7、其实,在linux中,“[]”与“test命令”是等效的。
如:test –n “$b” 和 [ -n “$b” ] 是等效的。注意使用test或者“[]”,变量是有加双引号的。
8、 当“[]”中使用“-n”或者“-z”这些选项判断变量是否为空时,“[]”和“[[]]”是有区别的。
结论:使用“[]”时需要在变量的外侧加上双引号,这样才保险。与“test命令”的使用方法相同。使用“[[]]”时则不用。
9、Shell脚本中,经常要同时对多个条件进行判断,就要用到“-a”或者“-o”对多个条件进行连接,然后进行“与运算”或者“或运算”,也可以使用“&&”或者“||”对多个条件进行连接。但是这两种方法对于“[ ]”或者“[[ ]]”来说,是有区别的。
结论: 在使用“[[ ]]”时,不能使用“-a”或者“-o”对多个条件进行连接。
在使用“[ ]”时,如果使用“-a”或者“-o”对多个条件进行连接,“-a”或者“-o”必须被包含在“[ ]”之内。
在使用“[ ]”时,如果使用“&&”或者“||”对多个条件进行连接,“-“&&”或者“||”必须在“[ ]”之外。
10、在使用符号“=~”去匹配正则表达式时,只能使用“[[ ]]”,不能应用于“[ ]”,当使用“>”或者“<”判断字符串的ASCII值大小时,如果结合“[]”使用,则必须对“>”或者“<”进行转义。
11、特殊符号
echo "num = $num" # 双引号是保留特殊字符(也就是$有取变量的功能)
echo 'num = $num' # 单引号当做字符串($失去了取变量的功能)
echo `pwd` # 反单引号解析为shell 命令
12、所谓的转义,意思就是去掉它的特殊含义。让shell把他们当做一般字符对待,不要进行特殊处理。
在shell中,特殊字符的转义有三种办法
1)用\转义: 把\字符放在特殊字符的前面
2)用单引号(‘’)转义: 用单引号把参数括起来
3)用双引号(“”)转义: 用双引号把参数括起来
上面三种转义方法的范围,第一种是最大的,第三种是最小的。
单引号告诉shell忽略所有特殊字符,而双引号忽略大多数,但不包括$、\、`。
注意:在shell中,"`"中间的东西将被视为命令替换。shell对参数进行预先处理时,将把两个"`"中间的东西当做shell命令进行执行,再将执行结果替换掉他们本身。
举个例子:
echo today is `date`
将显示
today is Mon Oct 12 16:14:16 CST 2015
我们说单引号可以转义"`", 而双引号不行,意思就是,单引号之间的"`"将失去它的特殊含义,而双引号之间的"`"将依然有特殊含义,所以
echo 'today is `date`'
将显示
today is `date`
而
echo “today is `date`”
将显示
today is Mon Oct 12 16:23:23 CST 2015
常见的一些特殊字符
* 任意个任意字符
? 一个任意字符
[..] []中的任意一个字符,这里也类似于正则表达式,中括号内可以是具体的一些字符,如[abcd]也可以是用-指定的一个范围,如[a-d]
# 注释
(空格) 参数分隔符
cmd 命令替换
| 管道
& 后台执行
; 命令分隔符(可以在同一行执行两个命令,用;分割)
~ 用户home目录
13、linux shell 脚本编写好要经过漫长的调试阶段,可以使用sh -x 执行。但是这种情况在远程调用脚本的时候,就有诸多不便。
又想知道脚本内部执行的变量的值或执行结果,这个时候可以使用在脚本内部用 set -x 。
Shell编程调试技巧:
set去追踪一段代码的显示情况,执行后在整个脚本有效
set -x 开启
set +x关闭
set -o 查看
14、在shell中,“-gt”或者“-lt”只能用于比较两个数字的大小,当我们想要比较两个字符的ASCII值时,则必须使用“>”或者“<”,而且需要注意,当使用“[[ ]]”进行判断时,“>”或者“<”不用进行转义即可正常使用,当使用“[]”进行判断时,“>”或者“<”需要转义后才能正常使用。
15、shell常用命令
cat 文件名 输出文件内容到基本输出(屏幕 or 加>fileName 到另一个文件)
cb 格式化源代码
chmod //change mode,改变文件的权限
cp copy
date 当前的时间和日期
echo $abc 在变量赋值之后,只需在变量前面加一个$去引用。
lint 语法检查程序
ls dir
man help
more type
du 查看磁盘空间状况
ps 查看当前进程状况
who 你的用户名和终端类型
定义变量 name=abc? (bash/pdksh) || set name = abc (tcsh)
mkdir 创建目录
rmdir 删除目录
cd 进入目录
rm 删除文件
more 显示文件
echo 显示指定文本
mv 改文件名 /移动文件
pwd 显示目录路径命令
反汇编
反汇编(Disassembly):把目标代码转为汇编代码的过程,也可以说是把机器语言转换为汇编语言代码、低级转高级的意思,常用于软件破解(例如找到它是如何注册的,从而解出它的注册码或者编写注册机)、外挂技术、病毒分析、逆向工程、软件汉化等领域。学习和理解反汇编语言对软件调试、漏洞分析、OS的内核原理及理解高级语言代码都有相当大的帮助,在此过程中我们可以领悟到软件作者的编程思想。总之一句话:软件一切神秘的运行机制全在反汇编代码里面。
编译原理
通常,编写程序是利用高级语言如C,C++,Delphi等高级语言进行编程的,然后再经过编译程序生成可以被计算机系统直接执行的文件(机器语言)。反汇编即是指将这些执行文件反编译还原成汇编语言或其他语言。但通常反编译出来的程序与原程序会存在些许不同,虽然执行效果相同,但程序代码会发生很大的变化,要读懂反汇编需要有扎实的高级语言编写功底和汇编功底。
了解一下汇编:
它的别名叫助记符号。顾名思义,它是帮助你记忆的符号。因为机器语言都是0和1组成的,不容易记忆。虽然我们尝试使用BCD码来表示它们。使其更有效率的方式是让具体的运算操作用有明确含义的字符来表示。然后通过查表找到它们对应的关系。反汇编是机器码向助记符转换的过程,汇编是用助记符表示机器码的样子。
汇编语言有很多种,不同平台有不同的汇编语言,如8086汇编、ARM汇编。
linux下objdump命令常见用法
objdump是linux下一款反汇编工具,能够反汇编目标文件、可执行文件。
用法:objdump <选项> <文件> 显示来自目标 <文件> 的信息。
objdump -x obj 以某种分类信息的形式把目标文件的数据组成输出;<可查到该文件的的所有动态库>
objdump -t obj 输出目标文件的符号表()
objdump -h obj 输出目标文件的所有段概括()
objdump -j ./text/.data -S obj 输出指定段的信息(反汇编源代码)
objdump -S obj 输出目标文件的符号表() 当gcc -g时打印更明显
objdump -j .text -Sl stack1 | more
-S 尽可能反汇编出源代码,尤其当编译的时候指定了-g这种调试参数时,效果比较明显。隐含了-d参数。
-l 用文件名和行号标注相应的目标代码,仅仅和-d、-D或者-r一起使用,使用-ld和使用-d的区别不是很大,在源码级调试的时候有用,要求编译时使用了-g之类的调试编译选项。
-j name 仅仅显示指定section的信息
这是按Section的名称列出的,其中跟动态连接有关的Section也出现在前面名为Dynamic的Segment中,只是在那里是按类型列出的。例如,前面类型为HASH的表项说与此有关的信息在0x8048128处,而这里则说有个名为.hash的Section,其起始地址为0x8048128。还有,前面类型为PLTGOT的表项说与此有关的信息在0x804a2c4处,这里则说有个名为.got的Section,其起始地址为0x804a2c4,不过Section表中提供的信息更加详细一些,有些信息则互相补充。在Section表中,只要类型为PROGBITS,就说明这个Section的内容都来自映像文件,反之类型为NOBITS就说明这个Section的内容并非来自映像文件。
跟区段头表中的信息一对照,就可以知道在第16项.data以前的所有区段都是要装入用户空间的。这里面包括了大家所熟知的.text即“代码段”。此外,.init、.fini两个区段也有着特殊的重要性,因为映像的程序入口就在.init段中,实际上在进入main()之前的代码都在这里。而从main()返回之后的代码,包括对exit()的调用,则在.fini中。还有一个区段.plt也十分重要,plt是“Procedure Linkage Table”的缩写,这就是用来为目标映像跟共享库建立动态连接的。
有些Section名是读者本来就知道的,例如.text、.data、.bss;有些则从它们的名称就可猜测出来,例如.symtab是符号表、.rodata是只读数据、还有.comment和.debug_info等等。还有一些可能就不知道了,这里择其要者先作些简略的介绍:
● .hash。为便于根据函数/变量名找到有关的符号表项,需要对函数/变量名进行hash计算,并根据计算值建立hash队列。
● .dynsym。需要加以动态连接的符号表,类似于内核模块中的INPORT符号表。这是动态连接符号表的数据结构部分,须与.dynstr联用。
● .dynstr。动态连接符号表的字符串部分,与.dynsym联用。
● .rel.dyn。用于动态连接的重定位信息。
● .rel.plt。一个结构数组,其中的每个元素都代表着GOP表中的一个表项GOTn(见下)。
● .init。在进入main()之前执行的代码在这个Section中。
● .plt。“过程连接表(Procedure Linking Table)”,见后。
● .fini。从main()返回之后执行的代码在这个Section中,最后会调用exit()。
● .ctors。表示“Constructor”,是一个函数指针数组,这些函数需要在程序初始化阶段(进入main()之前,在.init中)加以调用。
● .dtors。表示“Distructor”,也是一个函数指针数组,这些函数需要在程序扫尾阶段(从main()返回之后,在.fini中)加以调用。
● .got。“全局位移表(Global Offset Table)”,见后。
● .strtab。与符号表有关的字符串都集中在这个Section中。
Linux下C程序的反汇编
https://blog.csdn.net/u011192270/article/details/50224267
如何使用linux下objdump命令对任意一个二进制文件进行反汇编?
可以使用如下命令:
objdump -D -b binary -m i386 a.bin
-D表示对全部文件进行反汇编,-b表示二进制,-m表示指令集架构,a.bin就是我们要反汇编的二进制文件
objdump -m可以查看更多支持的指令集架构,如i386:x86-64,i8086等
另外上面的所有objdump命令的参数同样适用于arm-linux-objdump。
同时我们也可以指定big-endian或little-endian(-eb或-el),我们可以指定从某一个位置开始反汇编等。
objdump命令是Linux下的反汇编目标文件或者可执行文件的命令,它还有其他作用,下面以ELF格式可执行文件test为例详细介绍:
objdump -f test 显示test的文件头信息
objdump -d test 反汇编test中的需要执行指令的那些section
objdump -D test 与-d类似,但反汇编test中的所有section
objdump -h test 显示test的Section Header信息
objdump -x test 显示test的全部Header信息
objdump -s test 除了显示test的全部Header信息,还显示他们对应的十六进制文件代码
objdump:支持的目标: elf64-x86-64 elf32-i386 elf32-iamcu elf32-x86-64 a.out-i386-linux pei-i386 pei-x86-64 elf64-l1om elf64-k1om elf64-little elf64-big elf32-little elf32-big plugin srec symbolsrec verilog tekhex binary ihex
objdump:支持的体系结构: i386 i386:x86-64 i386:x64-32 i8086 i386:intel i386:x86-64:intel i386:x64-32:intel i386:nacl i386:x86-64:nacl i386:x64-32:nacl iamcu iamcu:intel l1om l1om:intel k1om k1om:intel plugin
反汇编的原因
1.逆向破解
2.我们在调试程序时侯,反汇编代码可以帮助我们理解程序
3.把c源代码编译链接生成的可执行程序,反汇编后得到对应汇编代码,可以帮助我们理解c语言和汇编语言之间的对应关系,非常有助于深入理解c语言,尤其是在理解链接脚本,链接地址,时候帮助非常大
反汇编工具帮助我们分析链接脚本
反汇编的时候得到的指令地址是链接器考虑了链接脚本之后得到的地址,而我们写代码时通过指定连接脚本来让链接器给我们链接合适的地址。
但是有时候我们写的链接脚本有误(或者我们不知道这个链接脚本会怎么样),这时候可以通过看反汇编文件来分析这个链接脚本的效果,看是不是我们想要的,如果不是可以改了再看。
gdb调试
可以使用 gdb 来调试用户空间程序或 Linux 内核,输入命令sudo apt-get instll gdb安装gdb调试器。
当需要使用gdb调试代码时,需要在gcc\g++编译选项中添加-g选项。
调试步骤:
首先,输入gdb test启动调试器
进入到gdb的调试界面之后,输入list,即可看到test.c源文件
设置断点,输入 b main
启动test程序,输入run
程序在main开始的地方设置了断点,所以程序在printf处断住
这时候,可以单步跟踪。s单步可以进入到函数,而n单步则越过函数
如果希望从断点处继续运行程序,输入c
希望程序运行到函数结束,输入finish
查看断点信息,输入 info break
如果希望查看堆栈信息,输入bt
希望查看内存,输入 x/64xh + 内存地址
删除断点,则输入delete break + 断点序号
希望查看函数局部变量的数值,可以输入print + 变量名
希望修改内存值,直接输入 print + *地址 = 数值
希望实时打印变量的数值,可以输入display + 变量名
查看函数的汇编代码,输入 disassemble + 函数名
退出调试输入quit即可
基本操作:
list 从第一行列出代码
按回车重复上次命令
quit退出
file装入想要调试的可执行文件
cd改变工作mulu
pwd返回当前工作目录
run 执行当前被调试的程序
kill停止正在调试的程序
break设置断点后面跟行号或者函数名
tbreak设置临时断点
watch 设置监视点,监视表达式的变化
next执行下一条代码,不进入函数内部,要先run了才能执行
setp执行下一条代码,进入函数内部
display停止运行时显示的表达式
info break显示当前断点列表
info func显示所有函数名
info local显示当前所有局部变量信息
info prog显示调试程序的执行状态
print 显示表达式的值
delete删除断点
shell执行命令
make 不退出而重新编译生成可执行文件
set 变量=值
c可以继续运行程序
共用体
共用体(union,联合,联合体)
共用体union在定义和使用形式上,和结构体struct很相似。但是两种数据结构是完全不同的两类东西。
结构体,是对多个数据的组合与封装。而共用体中只有一个东西,只是它被好几个名字(和类型)共用。
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
格式:
//定义共用体类型
union MyUnion
{
int a;
char b;
float c;
};
union MyUnion u1; // 使用自定义的union类型来定义变量
u1.a = 12933; //赋值
(可以先定义共用体,再创建变量,也可以在定义共用体的同时创建变量)
a、b、c其实都是同一个东西,只是从不同的角度去看不一样而已。叫MyUnion.a的时候是int型,叫MyUnion.b的时候是char型,叫MyUnion.c的时候是float型
变量的值与各数据类型的范围有关
char -128 ~ 127
int -xxxx ~ + xxxx
关键字:union
参考资料:http://www.jb51.net/article/91141.htm
位域
位域是指信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可。为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为“位域”或“位段”。所谓“位域”是把一个字节中的二进位划分为几 个不同的区域, 并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。 这样就可以把几个不同的对象用一个字节的二进制位域来表示。
位域定义
与结构定义相仿,其形式为:
struct 位域结构名
{
位域列表
};
其中位域列表的形式为: 类型说明符 位域名:位域长度
例如:
struct bs
{
int a:8;
int b:2;
int c:6;
};
位域变量的说明
与结构变量说明的方式相同。 可采用先定义后说明,同时定义说明或者直接说明这三种方式。例如:
struct bs
{
int a:8;
int b:2;
int c:6;
}data;
说明data为bs变量,共占2个字节。其中位域a占8位,位域b占2位,位域c占6位。
(以下转自https://blog.csdn.net/ccjjnn19890720/article/details/6612299)
1、位域又叫位段(位字段),是一种特殊的结构成员或联合成员(即只能用在结构或联合中),用于指定该成员在内存存储时所占用的位数,从而可以在机内更紧凑地表示数据。
2、位域的使用主要出现在如下两种情况:
(1)当机器可用内存空间较少而使用位域可以大量节省内存时。如,当把结构作为大数组的元素时。
(2)当需要把一结构或联合映射成某预定的组织结构时。例如,当需要访问字节内的特定位时。
3、当要把某个成员说明成位域时,其类型只能是int,unsigned int与signed int三者之一(说明:int类型通常代表特定机器中整数的自然长度。short类型通常为16位,long类型通常为32位,int类型可以为16位或32位。各编译器可以根据硬件特性自主选择合适的类型长度。见The C Programming Language中文 P32)。
4、带位域的结构在内存中各个位域的存储方式取决于具体的编译程序;它们既可以从左到右,也可以从右到左存储。
5、在一包含位域说明的强构或联合区分符中也可以同时说明普通成员,例如:
struct st1
{
unsigned a:7;
unsigned b:4;
unsigned c:5;
int i; //i是普通成员,这会被存放在下一个字,即字对齐
};
6、int值不能跨字存放,同样位域也最好不要跨字存放(意思说是说:各位域的分配位数加起来要在16位或32位以内,如果编译器分配int为16位,则加起来要在16位以内,如果加起来大于16位,则最好空出剩余的位域,从下一个字开始分配位域)。
7、特殊宽度0或者说长度为0的无名位域有着特殊的用途。它用于指示将其前后的两个位域或成员分开放在两个字中, 即将位于该无名位域后的下一个位域从下一个字开始存放。
8、位域备注:
关于位域还需要提醒读者注意如下几点:
其一,位域的长度不能大于int对象所占用的字位数。例如,若int对象占用16位,则如下位域说明是错误的:
unsigned int x:17;
其二,由于位域的实现会因编译程序的不同而不同,在此使用位域会影响程序的可移植性,在不是非要使用位域不可时最好不要使用位域。
其三,尽管使用位域可以节省内存空间,但却增加了处理时间,在为当访问各个位域成员时需要把位域从它所在的字中分解出来或反过来把一值压缩存到位域所在的字位中。
其四,位域的位置不能访问,因些不能对位域使用地址运算符号&(而对非位域成员则可以使用该运算符)。从而,即不能使用指向位域的旨针也不能使用位域的数组(因为数组实际上就是一种特殊的指针)。另外,位域也不能作为函数返回的结果。
最后还要强调一遍:位域又叫位段(位字段),是一种特殊的结构成员或联合成员(即只能用在结构或联合中)。
const和volatile的理解
const修饰变量
在c语言中,const修饰的是只读变量,并不是一个常量,本质还是一个变量。const修饰的变量会占用内存空间,本质上const只对编译器有用,它告诉编译器,这个变量是只读的,不能对其进行左值操作,运行时没用。
如果要对const修饰的只读变量赋值,可以使用指针,取地址操作符,因为它占用了内存空间
const修饰数组
在c语言中,const修饰的数组是只读的,const修饰的数组空间不可被改变。
const修饰指针
使用方法和判断技巧:
const int* p; //p可变,p指向的内容不可变
int const* p; //p可变,p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p和p指向的内容都不可变
口诀:左数右指
当const出现在*号左边时指针指向的数据为常量
当const出现在*后右边时指针本身为常量
所以在定义的时候,只需要看const和*的位置,const在左边的时候指向的数据为常量,那么去赋值就会出错,在右边的时候指针本身是常量,不可以给这个指针赋值。
const修饰函数参数和返回值
const修饰函数参数,表示在函数体内,不希望改变参数的值。
const修饰函数的返回值,表示返回值不可变,多用于返回指针。
这里如果函数被const修饰,在读取返回值的时候,最好还是把左值也定义为const类型的。
volatile的意义
变量加了volatile之后,会告诉编译器,不要去优化它,以免出错。原因就是比如在两次读取一个变量的值时,虽然两次读取中间没有进行修改变量的操作(赋值),但是中间可能会因为某些情况(硬件中断,多线程访问或者其他位置因素)改变了变量的值,如果编译器进行优化的话,在第二次读取的时候就不会到变量的地址去重新读取,而是把上一次读取到的值直接当成第二次读取到的值,这样,就导致出错,所以就需要用volatile来修饰变量,告诉编译器不要去优化,每次读取变量都去它的地址读。
因此,如果是一个寄存器变量或者一个端口数据就可以用volatile来修饰, volatile可以保证对特殊地址的稳定访问,不会容易出错。
const volatile int i=0分析
这里用const和volatile同时修饰i是没有问题的,因为他们的使用并不矛盾:
“const”含义是“请做为常量使用”,而并非“放心吧,那肯定是个常量”。
“volatile”的含义是“请不要做没谱的优化,这个值可能变掉的”,而并非“你可以修改这个值”。
所以这里的i的属性是在本程序中,i应该是只读的,不应该被修改的,但是它也可能被外部的例如中断、共享的线程通过某种方式修改,所以这里也不该被编译器优化,虽然它是只读的不该被修改的,但是它还是会改变,我们在程序中使用的时候,还是要每次都去读它的值,这是一种“双重保险”。
这个问题可以结合实际的使用场合来分析,举个例子:在程序A中,我们要访问一个只读寄存器c,这时候修饰它为const,但是在程序B中,我们又会改变c的值,为了在A中避免编译优化造成程序逻辑错误,我们将其修饰为volatile,这样c就具有了双重属性。
因此const和volatile放在一起的意义在于:
(1)本程序段中不能对a作修改,任何修改都是非法的,或者至少是粗心,编译器应该报错,防止这种粗心;
(2)另一个程序段则完全有可能修改,因此编译器最好不要做太激进的优化。
调试技巧——宏定义开关和printf
使用格式:
#define __DEBUG__
#ifdef __DEBUG__
#define DEBUG(format,...) printf("File: "__FILE__", Line: %05d: "format"\n", __LINE__, ##__VA_ARGS__)
#else
#define DEBUG(format,...)
#endif
输出格式:
FILE: xxx, LINE: xxx, …….
示例:
注意:
1、上面的%0nd表示输出的整型宽度至少为n位,不足n位用0填充
如:printf("%05d",1)输出:00001
2、如果可变参数被忽略或为空,‘ ## ’操作将使预处理器( preprocessor )去除掉它前面的那个逗号。如果你在宏调用时,确实提供了一些可变参数, GNU CPP 也会工作正常,它会把这些可变参数放到逗号的后面。
ANSI C标准中有几个标准预定义宏(也是常用的):
__LINE__:在源代码中插入当前源代码行号;
__FILE__:在源文件中插入当前源文件名;
__DATE__:在源文件中插入当前的编译日期
__TIME__:在源文件中插入当前编译时间;
__STDC__:当要求程序严格遵循ANSI C标准时该标识被赋值为1;
__cplusplus:当编写C++程序时该标识符被定义。
编译器在进行源码编译的时候,会自动将这些宏替换为相应内容。
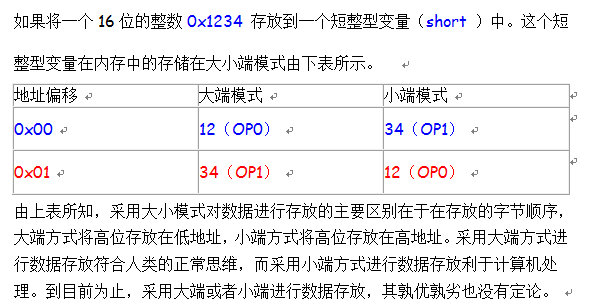
判断CPU大小端模式
大端模式和小端模式
在 各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机 通信领 域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正 确的编/译码从而导致通信失败。目前在各种体系的计算机中通常采用的字节存储机制主要有两种:Big-Endian和Little-Endian,下面先从字节序说起。
一、什么是字节序
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。其实大部分人在实际的开 发中都很少会直接和字节序打交道。唯有在跨平台以及网络程序中字节序才是一个应该被考虑的问题。
在所有的介绍字节序的文章中都会提到字节序分为两类:Big-Endian和Little-Endian,引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
1.1 什么是高/低地址端
首先我们要知道C程序映像中内存的空间布局情况:在《C专 家编程》中或者《Unix环境高级编程》中有关于内存空间布局情况的说明,大致如下图:
----------------------- 最高内存地址 0xffffffff
栈底
栈
栈顶
-----------------------
NULL (空洞)
-----------------------
堆
-----------------------
未初始 化的数据
----------------------- 统称数据段
初始化的数据
-----------------------
正 文段(代码段)
----------------------- 最低内存地址 0x00000000
由图可以看出,在内存分布中,栈是向下增长的,而堆是向上增长的。
以上图为例如果我们在栈 上分配一个unsigned char buf[4],那么这个数组变量在栈上是如何布局的呢?看下图:
栈底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
栈顶 (低地址)
其实,我们可以自己在编译器里面创建一个数组,然后分别输出数组种每个元素的地址,来验证一下。
1.2 什么是高/低字节
现在我们弄清了高/低地址,接着考虑高/低字节。有些文章中称低位字节为最低有效位,高位字节为最高有效位。如果我们有一个32位无符号整型0x12345678,那么高位是什么,低位又是什么呢? 其实很简单。在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。就拿 0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
高/低地址端和高/低字节都弄清了。我们再来回顾 一下Big-Endian和Little-Endian的定义,并用图示说明两种字节序:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下图:
栈底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下图:
栈底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
栈 顶 (低地址)
二、各种Endian
2.1 Big-Endian
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最重要字节(MSB)存放在最低端的地址 上。采用这种机制的处理器有IBM3700系列、PDP-10、Mortolora微处理器系列和绝大多数的RISC处理器。
+----------+
| 0x34 |<-- 0x00000021
+----------+
| 0x12 |<-- 0x00000020
+----------+
图 1:双字节数0x1234以Big-Endian的方式存在起始地址0x00000020中
在Big-Endian中,对于bit序列 中的序号编排方式如下(以双字节数0x8B8A为例):
bit 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+----------------------------------------+
图 2:Big-Endian的bit序列编码方式
2.2 Little-Endian
计算机体系结构中 一种描述多字节存储顺序的术语,在这种机制中最不重要字节(LSB)存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列微处理器和一些网络通信设备。该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
+----------+
| 0x12 |<-- 0x00000021
+----------+
| 0x34 |<-- 0x00000020
+----------+
图3:双字节数0x1234以Little-Endian的方式存在起始地址0x00000020中
在 Little-Endian中,对于bit序列中的序号编排和Big-Endian刚好相反,其方式如下(以双字节数0x8B8A为例):
bit 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+-----------------------------------------+
图 4:Little-Endian的bit序列编码方式
注意:通常我们说的主机序(Host Order)就是遵循Little-Endian规则。所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序 (Little-Endian)和网络序(Big-Endian)的转换。
采用 Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。 32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 0x4000 0x4001 0x4002 0x4003
存放内容 0x78 0x56 0x34 0x12
而在Big- endian模式CPU内存中的存放方式则为:
内存地址 0x4000 0x4001 0x4002 0x4003
存放内容 0x12 0x34 0x56 0x78
具体的区别如下:
三、Big-Endian和Little-Endian优缺点
Big-Endian优点:靠首先提取高位字节,你总是可以由看看在偏移位置为0的字节来确定这个数字是 正数还是负数。你不必知道这个数值有多长,或者你也不必过一些字节来看这个数值是否含有符号位。这个数值是以它们被打印出来的顺序存放的,所以从二进制到十进制的函数特别有效。因而,对于不同要求的机器,在设计存取方式时就会不同。
Little-Endian优点:提取一个,两个,四个或者更长字节数据的汇编指令以与其他所有格式相同的方式进行:首先在偏移地址为0的地方提取最低位的字节,因为地址偏移和字节数是一对一的关系,多重精度的数学函数就相对地容易写了。
如果你增加数字的值,你可能在左边增加数字(高位非指数函数需要更多的数字)。 因此, 经常需要增加两位数字并移动存储器里所有Big-endian顺序的数字,把所有数向右移,这会增加计算机的工作量。不过,使用Little- Endian的存储器中不重要的字节可以存在它原来的位置,新的数可以存在它的右边的高位地址里。这就意味着计算机中的某些计算可以变得更加简单和快速。
判断大小端模式
请写一个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1。
#include <stdio.h>
#include <stdlib.h>
int checkCPU(void)
{
union word {
int a;
char b;
}c;
c.a = 1;
return (c.b == 1);
}
int main(void)
{
int i;
i = checkCPU();
if (i == 0)
printf(“this is Big_endian\n”);
else if (i == 1)
printf(“this is Little_endian\n”);
return 0;
}
剖析:由于联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little- endian还是Big-endian模式读写。
说明:
1 在c中,联合体(共用体)的数据成员都是从低地址开始存放。
2 若是小端模式,由低地址到高地址c.a存放为0x01 00 00 00,c.b被赋值为0x01;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 01 00 00 00
c.b 01 00
————————————————————————————
3 若是大端模式,由低地址到高地址c.a存放为0x00 00 00 01,c.b被赋值为0x0;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 00 00 00 01
c.b 00 00
————————————————————————————
4 根据c.b的值的情况就可以判断cpu的模式了。
举例,一个16进制数是 0x11 22 33,其存放的位置是
地址0x3000 中存放11
地址0x3001 中存放22
地址0x3002 中存放33
连起来就写成地址0x3000-0x3002中存放了数据0x112233
而这种存放和表示方式,正好符合大端。
linux文件编程
Linux文件系统
Linux系统对物理磁盘的访问都是通过设备驱动程序来进行的,而对设备驱动程序的访问则有两种途径:通过设备驱动本身提供的接口和通过VFS提供给上层应用程序的接口。
Linux系统文件IO的主要实现方式为系统调用。操作系统提供的基本IO服务于Linux内核绑定,特用于Linux/UNIX系统。
文件IO 和 标准IO
文件I/O 又称为低级磁盘I/O,遵循POSIX相关标准。任何兼容POSIX标准的操作系统上都支持文件I/O。标准I/O被称为高级磁盘I/O,遵循ANSI C相关标准。只要开发环境中有标准I/O库,标准I/O就可以使用。(Linux 中使用的是GLIBC,它是标准C库的超集。不仅包含ANSI C中定义的函数,还包括POSIX标准中定义的函数。因此,Linux 下既可以使用标准I/O,也可以使用文件I/O)。
通过文件I/O读写文件时,每次操作都会执行相关系统调用。这样处理的好处是直接读写实际文件,坏处是频繁的系统调用会增加系统开销,标准I/O可以看成是在文件I/O的基础上封装了缓冲机制。先读写缓冲区,必要时再访问实际文件,从而减少了系统调用的次数。
文件I/O中用文件描述符表现一个打开的文件,可以访问不同类型的文件如普通文件、设备文件和管道文件等。而标准I/O中用FILE(流)表示一个打开的文件,通常只用来访问普通文件。
文件描述符
在Linux系统中,一切都可以被看作是文件,这包括:普通文件、目录文件、链接文件和设备文件。要访问文件,必须使用文件描述符。文件描述符是一个非负的整数,它是系统中被打开文件的索引。当打开或者创建一个文件时,内核会返回一个文件描述符;当需要读写文件时,也需要将相应的文件描述符作为参数传给读写函数。程序启动时,默认有3个文件描述符:
| 文件描述符 |
宏 |
说明 |
| 0 |
STDIN_FILENO |
标准输入 |
| 1 |
STDOUT_FILENO |
标准输出 |
| 2 |
STDERR_FILENO |
标准错误输出 |
新进程执行时,shell会默认分配三个文件描述符,STDIN_FILENO/STDOUT_FILENO/STDERR_FILENO,一般为0/1/2,定义在<unistd.h>中。文件描述符的范围是0~OPEN_MAX。(<unistd.h>的全称为unix standard head,unix的标准调用。)
如果此时创建或打开一个文件,这个文件的文件描述符就是3。
可用的文件I\O函数很多,包括:打开文件,读文件,写文件等。大多数Linux文件I\O只需要用到5个函数:open,read,write,lseek以及close。
流和FILE对象
文件IO主要是针对文件描述符,而标准IO的操作主要是围绕流进行的,当用标准IO打开或创建一个文件时,就使得一个流与对应的文件相结合。
当打开一个流时,标准IO函数fopen返回一个指向FILE对象的指针。该对象通常是一个结构,它包含了标准IO库为管理该流所需要的所有信息,包括:用于实际IO的文件描述符、指向用于该流缓冲区的指针、缓冲区的长度、当前在缓冲区中的字符数以及出错标志等等。
缓冲机制
标准I/O提供了3种类型的缓冲区。文件缓冲可减少读写函数的调用次数。
- 全缓冲区
这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。第一次执行I/O操作时,ANSI标准的文件管理函数通过调用malloc函数获得需要使用的缓冲区,默认大小为8192。
- 行缓冲区
在这种情况下,当在输入和输出中遇到换行符’\n’时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。因为标准I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符’\n’,也会执行I/O系统调用操作,默认行缓冲区的大小为1024。
3、无缓冲区
标准 I / O库不对字符进行缓存。如果用标准 I / O函数写若干字符到不带缓存的流中,则相当于用 w r i t e系统调用函数将这些字符写至相关联的打开文件上。标准出错流stderr通常也是不带缓冲区的,这使得出错信息能够尽快地显示出来。
注意:
①标准输入和标准输出设备:当且仅当不涉及交互作用设备时,标准输入流和标准输出流才是全缓冲的。②标准错误输出设备:标准出错绝不会是全缓冲方式的。
对于任何一个给定的流,可以调用setbuf()和setvbuf()函数更改其缓冲区类型。
文件IO
文件的IO操作需要的头文件基本一样,都要用到那几个头文件,实际编程中我们可以从终端里通过man命令查找然后复制过来直接用。例如,在Ubuntu终端里输入man 2 read 后就可以查到关于read的用户手册,其中对read的详细介绍就包括头文件等等。其他函数用相同的方法都可查询到。
打开/创建文件open( )
函数open( ) 用于打开或者创建文件。其在打开或者创建文件时可以指定文件的属性及用户的权限等各种参数。要使用 open() 函数,需要包含 #include <sys/stat.h>、 #include <fcntl.h> 和 #include <sys/types.h> 头文件。
函数原型
int open(const char *path, int oflags);
int open(const char *path, int oflags,mode_t mode);
函数参数
const char *path: 文件路径,可以是绝对,也可以是相对路径
int oflag: 文件打开的方式
- O_RDONLY 只读打开
- O_WRONLY 只写打开
- O_RDWR 可读可写打开
以上3种必选一个,以下4种可以任意选择
- O_APPEND 追加打开,所写数据附加到文件末
- O_CREAT 若此文件不存在则创建它
- O_EXCL 若文件存在则报错返回
- O_TRUNC 如果文件已存在,并且以只写或可读可写方式
打开,则将其长度截断为0字节
mode_t mode: 文件权限,只有在创建文件时需要使用
函数返回值
文件描述符,非负整数是成功,-1是失败
在 open() 函数中,文件的打开方式不止上面的几种,这里只列举了常用的7种。
注意,新建文件的权限不是直接等于 mode 的值,而是等于 mode & ~uname 。
写文件 write()
当文件打开后,我们就可以向该文件写数据了。在Linux系统中,用 write() 向打开的文件写入数据,要使用这个函数,需要包含 #include <unistd.h> 。下面是函数的说明:
函数原型
ssize_t write(int fildes, const void *buf, size_t nbyte);
函数参数
int fildes: 写入文件的文件描述符
const void *buf: 写入数据在内存空间存储的地址
size_t nbyte: 期待写入数据的最大字节数
函数返回值
文件实际写入的字节数,非负整数是成功,-1是失败(常见原因是磁盘已满或者超出该文件的长度等)
注意函数的返回类型是 ssize_t 。 ssize_t 同 size_t 类似,只是 ssize_t 表示有符号数。ssize_t是系统头文件中用typedef定义的数据类型相当于signed int
读文件 read()
和写文件类似,要使用读文件函数 read() ,需要包含 #include <unistd.h> 。
函数原型
ssize_t read(int fildes, void *buf, size_t nbyte);
函数参数
int fildes : 读取文件的文件描述符
void *buf : 读取数据在内存空间存储的地址
size_t nbyte: 期待读取数据的最大字节数
函数返回值
文件实际读取的字节数,非负整数是成功,-1是失败
同 write() 一样,read() 函数的返回类型也是 ssize_t 。
关闭文件 close()
当文件不再被使用时,可以调用 close() 函数来关闭被打开的文件。
当一个进程终止的时候,它所有的打开文件都是由内核自动关闭。很多程序都使用这一功能而不显式地调close关闭一个已打开的文件。 但是,作为一名优秀的程序员,应该显式的调用close来关闭已不再使用的文件。
要使用该函数,需要包含 #include <unistd.h> 。
函数原型
int close(int fildes);
函数参数
int fildes: 要关闭文件的文件描述符
函数返回值
文件关闭状态,0是成功,-1是失败
文件偏移量 lseek()
每个打开的文件都有一个“当前文件偏移量”,是一个非负整数,用以度量从文件开始处计算的字节数。通常,读写操作都是从当前文件偏移量处开始,并使偏移量增加所读或写的字节数。默认情况下,你打开一个文件(open),除非指定O_APPEND参数,不然位移量被设为0。我们可以通过 lseek() 函数来调整文件的偏移量。同 write() 和 read() 函数类似,要使用这个函数,需要包含 #include <unistd.h> ,#include <sys/types.h>。
函数原型
off_t lseek(int fildes, off_t offset, int whence);
函数参数
int fildes : 修改文件的文件描述符
off_t offset: 文件偏移量移动的距离
int whence : 文件偏移量的基址
- SEEK_SET该文件的位移量设置为据文件开始处offset个字节
- SEEK_CUR该文件的位移量设置为当前值加offset。offset可为正或负
- SEEK_END该文件的位移量设置为文件长度加offset。offset可为正或负
函数返回值
当前文件指针的位置,非负整数是成功,-1是失败
off_t 同 ssize_t 类似,都是有符号数signed int。
fcntl()
待续..
获取文件属性 stat()
系统调用stat的作用是获取文件的各个属性。
需要包含的头文件: <sys/types.h>,<sys/stat.h>,<unistd.h>
函数原型
int stat(const char \* path, struct stat \* buf)
函数功能
查看文件或目录属性。将参数path所指的文件的属性,复制到参数buf所指的结构中。参数:
函数参数
path:要查看属性的文件或目录的全路径名称。
buf:指向用于存放属性的结构体。
函数返回值
成功返回0;失败返回-1
stat成功调用后,buf的各个字段将存放各个属性。struct stat是系统头文件中定义的结构体,定义如下:
struct stat {
dev_t st_dev;
ino_t st_ino;
mode_t st_mode;
nlink_t st_nlink;
uid_t st_uid;
gid_t st_gid;
dev_t st_rdev;
off_t st_size;
blksize_t st_blksize;
blkcnt_t st_blocks;
time_t st_atime;
time_t st_mtime;
time_t st_ctime;
};
结构体成员:
st_ino:节点号
st_mode:文件类型和文件访问权限被编码在该字段中
st_nlink:硬连接数
st_uid:属主的用户ID
st_gid:所属组的组ID
st_rdev:设备文件的主、次设备号编码在该字段中
st_size:文件的大小
st_mtime:文件最后被修改时间
其中 用来获取文件类型和文件访问权限 的st_mode的文件类型宏定义:

利用这个可以判断出文件类型
if (S_ISREG(buf.st_mode))
file_mode = "-";
else if (S_ISDIR(buf.st_mode))
file_mode = "d";
else if (S_ISCHR(buf.st_mode))
file_mode = "c";
else if(S_ISBLK(buf.st_mode))
file_mode = "b";
access()函数:确定文件或文件夹的访问权限
头文件:unistd.h
功 能: 确定文件或文件夹的访问权限。即,检查某个文件的存取方式,比如说是只读方式、只写方式等。如果指定的存取方式有效,则函数返回0,否则函数返回-1。
用 法: int access(const char *filenpath, int mode);
参数:
filenpath 文件或文件夹的路径,当前目录直接使用文件或文件夹名(使用绝对路径)
mode 要判断的模式
注意:当该参数为文件的时候,access函数能使用mode参数所有的值,当该参数为文件夹的时候,access函数值能判断文件夹是否存在。在头文件unistd.h中的预定义如下:
#define R_OK 4 /* Test for read permission. */
#define W_OK 2 /* Test for write permission. */
#define X_OK 1 /* Test for execute permission. */
#define F_OK 0 /* Test for existence. */
具体含义如下:
R_OK 只判断是否有读权限
W_OK 只判断是否有写权限
X_OK 判断是否有执行权限
F_OK 只判断是否存在
对于前三种情况,可以用“或”的方法将多种情况合在一起测试,比如R_OK | W_OK就代表测试进程对文件的读写权限.
标准IO
ANSI C库IO函数其实就是对Posix IO函数的封装,在其基础上加上了流的概念,并在用户空间申请了流资源(例如缓冲区),这样处理显然增加了程序的灵活性和可移植性。ANSI C库函数是在用户态实现,流的相关资源也存在于用户态,但无论如何实现,最终都需要通过内核实现对文件的读写控制。
当打开一个流时,标准IO函数fopen返回一个指向FILE对象的指针。该对象通常是一个结构,它包含了标准IO库为管理该流所需要的所有信息,包括:用于实际IO的文件描述符、指向用于该流缓冲区的指针、缓冲区的长度、当前在缓冲区中的字符数以及出错标志等等。
打开标准IO流 fopen()、fdopen()、freopen()
fopen()、fdopen()和freopen()三个函数用于打开一个标准IO流。
fopen函数功能:打开指定路径的文件,获取指向该文件的指针。
fdopen函数功能:取一个现存的文件描述符,并使一个标准的I / O流与该描述符相结合。此函数常用于由创建管道和网络通信通道函数获得的描述符。因为这些特殊类型的文件不能用标准I/O fopen函数打开,首先必须先调用设备专用函数以获得一个文件描述符,然后用fdopen使一个标准I/O流与该描述符相结合。
freopen函数功能:用于重定向输入输出流。该函数可以在不改变代码原貌的情况下改变输入输出环境,但使用时应当保证流是可靠的。
要使用这三个函数,需要包含头文件#include <stdio.h>
函数原型
FILE *fopen(const char *path, const char *mode);
FILE * fdopen(int fd,const char *mode)
FILE* freopen(const char* path, const char* mode, FILE* stream);
函数参数
const char *path 要打开的文件路径及文件名
const char *mode 用于定义打开文件的访问权限。例如,"r"表示“只读访问”、"w"表示“只写访问”、"a"表示“追加写入”。
int fd 要打开的文件描述符
const char *path 需要重定向到的文件名或文件路径。
FILE* stream 需要被重定向的文件流
mode有下列几种形态字符串:
"r"或"rb" 以只读方式打开文件,该文件必须存在。
"w"或"wb" 以写方式打开文件,并把文件长度截短为零。
"a"或"ab" 以写方式打开文件,新内容追加在文件尾。
"r+"或"rb+"或"r+b" 以更新方式打开(读和写)
"w+"或"wb+"或"w+b" 以更新方式打开,并把文件长度截短为零。
"a+"或"ab+"或"a+b" 以更新方式打开,新内容追加在文件尾。
字母b表示打开的文件为一个二进制文件,而不是纯文本文件。(linux下不区分二进制文件和文本文件)
函数返回值
三个函数,如果成功返回指向该流的文件指针,失败则返回NULL,并把错误代码存在 error 中。
二进制和文本模式的区别
1、在Windows系统中,文本模式下,文件以"\r\n"代表换行。若以文本模式打开文件,并用 fputs 等函数写入换行符"\n"时,函数会自动在"\n"前面加上"\r"。即实际写入文件的是"\r\n"。
2、在类 Unix/Linux 系统中文本模式下,文件以"\n"代表换行。所以 Linux 系统中在文本模式和二进制模式下并无区别。
打开方式总结:各种打开方式主要有三个方面的区别
1、打开是否为二进制文件,用“b”标识。
2、读写的方式,有以下几种:只读、只写、读写、追加只写、追加读写这几种方式。
3、对文件是否必 须存在、以及存在时是清空还是追加会有不同的响应。具体判断如下图。
在文件操作时,需要注意以下几点问题
1、在定义文件指针时,要将文件指针指向空;如 FILE *fp = NULL;
2、文件操作完成后,需要将文件关闭,一定要注意,否则会造成文件所占用内存泄漏和在下次访问文件时出现问题。
3、文件关闭后,需要将文件指针指向空,这样做会防止出现游离指针,而对整个工程造成不必要的麻烦;如:fp = NULL
关闭一个打开的标志IO流 fclose()
fclose()功能:
关闭一个打开的流。注意:使用fclose()函数就可以把缓冲区内最后剩余的数据输出到内核缓冲区(刷新缓冲区),并释放文件指针和有关的缓冲区。
函数原型
Int fclose(FILE *fp);
函数参数
FILE *fp 要被关闭的文件流
函数返回值
如果流成功关闭,fclose 返回 0,否则返回EOF(-1)。(如果流为NULL,而且程序可以继续执行,fclose设定error number给EINVAL,并返回EOF。)

fgetc()、getc()、getchar()
三个函数用于从标准流中一次性读取一个字符。
fgetc() 单字节读文件
getchar()等同于函数getc(stdin)
fputc()、putc()、putchar()
三个函数用于向标准流中一次性写入一个字符。
fputc() 单字节写文件
putchar(c)等同于putc(c, stdout)

fgets()、gets()
用于从打开流中一次性读取一行字符
fgets() 单行读文件
fputs()、puts()
用于向打开的流中一次性写入一个字符串。
fputs() 单行写文件

二进制文件
对于文本文件,通常以字符或行为单位进行文件读写;对于二进制文件操作,更倾向于一次性读写一个完整的结构。如果使用函数getc()或putc()读写一个结构,那么循环必须通过整个结构,循环每次只能处理一个字节,这样会很麻烦且效率低下。如果使用函数fputs(),可能实现不了完整读写结构的要求,因为函数fputs()在遇到NULL字节时就会停止,而在结构体中可能含有NULL字节。类似地,如果输入数据中包含有NULL字节或换行符,则函数fgets()也不能进行完整读写的操作。
因此提供了函数fread()和fwrite(),用于执行二进制文件的读写操作。使用方式大致有两种:一次性读写一个数组和一次性读写一个结构。
读二进制文件 fread()
fread()函数功能
从一个文件流中读数据,最多读取count个元素,每个元素size字节,如果调用成功返回实际读取到的元素个数,如果不成功或读到文件末尾返回 0。
函数原型
size_t fread ( void *buffer, size_t size, size_t count, FILE *stream) ;
函数参数
void *buffer 用于接收数据的内存地址
size_t size 要读写的字节数,单位是字节
size_t count 要进行读写多少个size字节的数据项,每个元素是size字节.
FILE *stream 输入流
函数返回值
实际读取的元素个数.如果返回值与count不相同,则可能文件结尾或发生错误,从ferror和feof获取错误信息或检测是否到达文件结尾.

写二进制文件fwrite()
fwrite()函数功能
向文件写入一个数据块
函数原型
size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream);
函数参数
buffer:是一个指针,对fwrite来说,是要获取数据的地址;
size:要写入内容的单字节数;
count:要进行写入size字节的数据项的个数;
stream:目标文件指针;
函数返回值
返回实际写入的数据块数目

例程:fwrite()函数的其他几种使用场景

标准I/O错误处理ferror()和feof()
在头文件<stdio.h>中常数EOF被要求为一个负值,通常是-1。
#define EOF (-1)
大多数是现在,FILE对象为每个流维护了两个标识符:出错标识、文件结束标识。
当标准I/O操作发生错误处理时,一般返回NULL指针或者EOF,我们可以通过errno变量得到错误码。
函数原型
int ferror(FILE *stream);
int feof(FILE *stream);
void clearerr(FILE *stream);
功能
ferror函数用于判断文件流是否发生错误,若返回非0值则表示发生了错误
feof函数用于判断对文件流的读写是否已经达尾部,若返回非0值则表示已经达尾部。
clearerr()可以清除这两个标识。

清除读写缓冲区 fflush()
函数功能
清除读写缓冲区,fflush()会强迫将缓冲区内的数据写回参数stream 指定的文件中。如果参数stream 为NULL,fflush()会将所有打开的文件数据更新。
头文件:stdio.h
函数原型
int fflush(FILE *stream)
函数参数
FILE *stream 要冲洗的流
函数返回值
成功刷新,fflush返回0。指定的流没有缓冲区或者只读打开时也返回0值。返回EOF指出一个错误。
注意:如果fflush返回EOF,数据可能由于写错误已经丢失。当置一个重要错误处理器时,最安全的是用setvbuf函数关闭缓冲或者使用低级I/0例程,如open、close和write来代替流I/O函数。
文件流定位ftell()和fseek()和rewind()函数
- ftell()函数
功能
用于得到文件位置指针当前位置相对于文件首的偏移字节数。在随机方式存取文件时,由于文件位置频繁的前后移动,程序不容易确定文件的当前位置。
函数原型
long ftell(FILE *stream);
函数参数
stream为文件指针
函数返回值
因为ftell返回long型,根据long型的取值范围-231~231-1(-2147483648~2147483647),故对大于2.1G的文件进行操作时出错。
调用示例

首先将文件的当前位置移到文件的末尾,然后调用函数ftell()获得当前位置相对于文件首的位移,该位移值等于文件所含字节数。
- fseek()函数
功能
重定位流(数据流/文件)上的文件内部位置指针
头文件:#include <stdio.h>
fseek函数和lseek函数类似,但lseek返回的是一个off_t数值,而fseek返回的是一个整型。
函数原型
int fseek(FILE *stream,long offset,int whence);
函数参数
stream为文件指针
offset为偏移量,正数表示正向偏移,负数表示负向偏移
whence:表示偏移量相对于文件开始位置 SEEK_SET 0
表示偏移量相对于文件当前位置 SEEK_CUR 1
表示偏移量相对于文件末尾位置 SEEK_END 2
函数返回值
成功,返回0,失败返回-1,并设置error的值,可以用perror()函数输出错误。
如果执行成功,stream将指向以whence为基准,偏移offset(指针偏移量)个字节的位置,函数返回0。如果执行失败(比如offset超过文件自身大小),则不改变stream指向的位置,函数返回一个非0值。
调用示例

首先将文件的当前位置移到文件的末尾,然后调用函数ftell()获得当前位置相对于文件首的位移,该位移值等于文件所含字节数。
- rewind函数
功 能: 将文件内部的位置指针重新指向一个流(数据流/文件)的开头
注意:不是文件指针而是文件内部的位置指针,随着对文件的读写文件的位置指针(指向当前读写字节)向后移动。而文件指针是指向整个文件,如果不重新赋值文件指针不会改变。
rewind函数作用等同于 (void)fseek(stream, 0L, SEEK_SET); [1]
用 法: void rewind(FILE *stream);
头文件: stdio.h
格式化输入/输出
- 格式化输入
scantf()函数。(经历使用其他函数完成输入功能,如fread()或fgets()函数)
- 格式化输出
printf()函数,用于将格式化数据写到标准输出中;
fprintf()函数,用于将格式化数据写到指定的流中;
dprintf()函数,用于将格式化数据写到指定的文件描述符中,该函数并不处理文件指针,因而不需要调用函数fopen()将文件描述符转化为文件指针;
sprintf()函数用于将格式化数据写到数组str中;
snprintf()函数,用于在数组str末尾自动追加一个NULL字节,但该字节不包括在返回值中。
目录文件
mkdir() 创建目录
rmdir() 删除目录
opendir() 打开目录
closedir() 关闭目录
readdir() 读取目录
chdir() 改变当前工作目录
getcwd() 获取当前目录
1. 打开目录
需要包含的头文件:<sys/types.h>,<dirent.h>
函数原型:DIR * opendir(const char * name)
功能:opendir()用来打开参数name指定的目录,并返回DIR *形态的目录流
返回值:成功返回目录流;失败返回NULL
2. 读取目录
函数原型:struct dirent * readdir(DIR * dir)
功能:readdir()返回参数dir目录流的下一个子条目(子目录或子文件)
返回值: 成功返回结构体指向的指针,错误或以读完目录,返回NULL
函数执行成功返回的结构体原型如下:
struct dirent {
ino_t d_ino;
off_t d_off;
unsigned short d_reclen;
unsigned char d_type;
char d_name[256];
};
其中 d_name字段,是存放子条目的名称
3. 关闭目录
函数原型:int closedir(DIR * dir)
功能:closedir()关闭dir所指的目录流
返回值:成功返回0;失败返回-1,错误原因在errno中
链接文件
硬连接和软连接,软连接也被称为符号链接。
临时文件
linux系统为临时文件的创建提供了两种实现方案:基于ISO C库的实现方式和基于Single UNIX Specification的实现方式
linux进程编程
进程环境和进程属性
程序和进程:程序是放在磁盘文件中的可执行文件。使用6个exec函数中的一个由内核将程序读入存储器,并使其执行。程序的执行实例被称为进程,进程的环境由当前系统状态及其父进程信息决定和组合。任何进程都有自己代码执行的系统环境和系统资源,任何进程都有自己专用的系统属性。
进程资源:进程是linux下用户层管理事务的基本单位,每个进程都有自己独立的运行空间。为了更好地管理linux所访问的资源,系统在内核文件include/linux/sched.h中定义了struct task_struct来管理每个进程的资源,该结构体主要包括线程基本信息、内存信息、tty终端信息,当前目录信息、打开的文件描述符信息以及信号信息。除此之外,进程还有其他进程属性。
进程属性:与进程本身有关的是PID(进程ID)、PPID(父进程ID)、PGID(进程组ID)。与进程用户有关的是UID(进程真实用户ID)、EUID(进程有效用户ID)、GID(进程真实用户组ID)和EGID(进程有效用户组ID)。
会话:会话是一个或多个进程组的集合。系统调用函数getsid()用来获取某个进程的会话号SID,调用函数setsid()来创建新会话。
#include <unistd.h>
pid_t getsid(pid_t pid);
pid_t setsid(void);
进程状态:用户级进程由5种状态:就绪/运行状态、等待状态(可被中断)、等待状态(不可被中断)、停止状态和僵死状态。系统内核进程状态有7种。
进程管理和控制
进程管理:常见的进程管理方式包括:创建进程、获取进程信息、设置进程属性、执行进行、退出进程和跟踪进程。用 f o r k可以创建新进程,用 e x e c可以执行新的程序。 e x i t函数和两个 w a i t函数处理终止和等待终止。
进程控制:有三个用于进程控制的主要函数: f o r k、 e x e c和 w a i t p i d( e x e c函数有六种变体,但经常把它们统称为 e x e c函数)。
进程标识:每个进程都有一个非负整型的唯一进程 I D。因为进程 I D标识符总是唯一的,常将其用做其他标识符的一部分以保证其唯一性。
获取进程各种标识 getpid()等相关函数
包含头文件:#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void); 返回:调用进程的进程 I D
pid_t getppid(void); 返回:调用进程的父进程 I D
uid_t getuid(void); 返回:调用进程的实际用户 I D
uid_t geteuid(void); 返回:调用进程的有效用户 I D
gid_t getgid(void); 返回:调用进程的实际组 I D
gid_t getegid(void); 返回:调用进程的有效组 I D
pid_t getpgid(pid_t pid); 返回:进程号pid的进程组ID
例程:获取进程各种标识

创建进程
在linux环境下,系统运行的第一个进程init(PID为1)由内核产生,然后所有的进程都由进程init(PID为1)直接或间接创建。所有的进程都是通过调用fork函数创建的。新进程是调用进程的复制品,故称调用进程为父进程,新创建的进程为子进程。 f o r k对父进程返回新子进程的非负进程 I D,对子进程则返回 0。因为f o r k创建一新进程,所以说它被调用一次 (由父进程),但返回两次(在父进程中和在子进程中 )。
fork函数调用成功后,其子进程会复制父进程的几乎所有信息(除PID等信息)。
子进程从创建后和父进程同时执行,竞争系统资源,子进程的执行位置为fork返回位置。所以,fork函数后的代码在子进程中也被执行。实际上,其他代码也在子进程的代码段中,只是子进程执行的位置为fork返回位置,其之前的代码无法执行罢了。
负责创建进程的函数的层次结构

fork函数
对打开文件的处理:fork创建子进程后,子进程将复制父进程的数据段、BSS段、代码段、堆空间、栈空间和文件描述符。而对于文件描述符的内核文件表项,则是采用共享的方式。即父子进程对于局部变量(即栈空间)执行复制操作,而对文件描述符的文件表项信息(如文件的读写位置)则是共享使用的。
包含头文件 #inlcude <unistd.h>
函数原型:
pid_t fork(void);
返回:在父进程中将返回子进程(新创建的进程)的PID,类型为pid_t,在子进程中将返回0,以区分父子进程。如果执行失败,则在父进程中返回-1,错误原因存储在errno中。
例程:fork函数

vfork函数
对打开文件的处理:vfork()函数创建新进程时无需完全复制父进程的地址空间。因为如果派生的进程只执行exec()函数,则使用fork()从父进程复制到子进程的数据空间将不载使用,这样效率非常低。所以,vfork()函数就显得非常有用了,根据父进程数据空间的大小,vfork()比fork()可以很大程度上提高性能。vfork()只在需要的时候复制,而一般采用与父进程共享所有资源的方式处理。注意:在子函数中调用vfork()函数创建子进程,会出现段错误。
包含头文件 #include <sys/types.h>
#include <unistd.h>
函数原型
pid_t vfork(void);
返回:在子进程环境中返回0,在父进程环境中返回子进程的进程号。
两个函数的区别:在执行过程中,fork()函数是拷贝一个父进程的副本,从而拥有自己独立的代码段、数据段以及堆栈空间,即成为一个独立的实体。而vfork()是共享父进程的代码以及数据段。
例程:vfork函数

在进程中运行新代码
用fork函数创建子进程后,如果希望在当前子进程中运行新程序,则可以调用exec系列函数。但进程调用exec系列函数中的任意一个时,该进程代码段、数据段内容完全由新程序替代,而新程序则从其 m a i n函数开始执行。因为调用exec并不创建新进程,所以前后的进程ID关信息并不发生变化。exec只是用新程序替换了当前进程的正文、数据、堆和栈段。
exec系列函数的区别
指示新程序的位置是使用路径名还是文件名,使用文件名则需要该程序名在$PATH路径名存在;在使用参数是使用参数列表还是使用argv[]数组。
excel()、execlp()、execle()、execv()、execvp()、execve()
使用参数表的函数带字母l
使用argv的函数带字母v
使用文件名的函数带字母p
使用环境变量数组,不使用进程原有的环境变量,设置新加载程序运行的环境变量的函数带e
包含头文件
#include <unistd.h>
函数原型
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *filename, char *const argv[], char *const envp[]);
注意:
- 这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回,如果调用出错则返回-1,所以exec函数只有出错的返回值而没有成功的返回值。所以不需要判断他的返回值,直接在后面调用perror即可。
- 事实上,只有execve是真正的系统调用,其它五个函数最终都调用execve,所以execve在man手册第2节,其它函数在man手册第3节。
exec系列函数之间的关系

执行新代码对打开文件的处理
在执行exec系列函数时,默认情况下,新代码可以使用在原来代码中打开的文件描述符,即执行exec系列函数时,并不关闭原来的文件描述符。但如果调用以下代码:
fcntl(fd, F_SETFD, FD_CLOEXEC);
即关闭项,则在执行execX系列函数后将关闭原来打开的文件描述符。
例程:调用exec函数在进程中运行新代码

system()函数
除以上函数外,system()以新进程方式运行一个程序,然后结束。system()函数用来创建新进程,并在此进程中运行新进程,直到新进程结束后,才继续运行父进程。子进程结束后,会返回退出状态(如wait函数一样)。
包含头文件
#include <stdlib.h>
函数原型
int system(const char *command);
等待进程结束
进程与进程间要进行信息或状态的传递与交互,必须使用进程间通信机制,linux使用函数wait()和waitpid()在父子进程间提供了简单的父子进程同步机制。
wait()函数
调用wait()函数的父进程将等待该进程的任意一个子进程结束后才继续执行(如果有多个子进程,只需要等待其中的一个进程。)
包含头文件
#include <sys/types.h>
#include <sys/wait.h>
函数原型
pid_t wait(int *status);
函数参数
参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何死掉的毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样想),我们就可以设定这个参数为NULL
返回
如果等待到任意一个子进程结束,将返回当前结束的子进程的PID,同时将子进程退出时的状态存储在“__stat_loc”变量中,如执行失败则返回-1,错误原因存储在errno中。
常用到的宏
1、WIFEXITED(status) 若此值为非0 表明进程正常结束。
若上宏为真,此时可通过WEXITSTATUS(status)获取进程退出状态(exit时参数)
示例:
if(WIFEXITED(status)){
printf("退出值为 %d\n", WEXITSTATUS(status));
}
WIFEXITED(status) 这个宏用来指出子进程是否为正常退出的,如果是,它会返回一个非零值(请注意,虽然名字一样,这里的参数status并不同于wait唯一的参数---指向整数的指针status,而是那个指针所指向的整数,切记不要搞混了)
WEXITSTATUS(status) 当WIFEXITED返回非零值时,我们可以用这个宏来提取子进程的返回值,如果子进程调用exit(5)退出,WEXITSTATUS(status) 就会返回5;如果子进程调用exit(7),WEXITSTATUS(status)就会返回7。请注意,如果进程不是正常退出的,也就是说, WIFEXITED返回0,这个值就毫无意义。
2、WIFSIGNALED(status)为非0 表明进程异常终止。
若上宏为真,此时可通过WTERMSIG(status)获取使得进程退出的信号编号
用法示例:
if(WIFSIGNALED(status)){
printf("使得进程终止的信号编号: %d\n",WTERMSIG(status));
}
例程:wait函数以及两个常用的宏使用

waitpid()函数
用户可以使用waitpid()函数来等待指定子进程(指定PID的子进程)结束。
包含头文件
#include <sys/types.h> //提供类型pid_t的定义
#include <sys/wait.h>
函数原型
pid_t waitpid(pid_t pid, int *status, int options);
函数参数
pid_t pid 进程PID值:
pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。(其实在内核中,wait函数就是经过包装的waitpid函数)
pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
int *status 调用它的函数中的某个变量地址,如果执行成功,
则用来存储结束进程的结束状态。
int options 等待选项。可以设置为0,也可以是WNOHANG和WUNTRACED,WNOHANG表示不阻塞等待,WUNTRACED表示报告状态信息。
返回
如果设置等待选项为WNOHANG,而此时没有子进程退出,将返回0。如果子进程结束,是返回子进程的PID,并获取子进程的状态于status中。
例程:waitpid函数

退出进程
有五种方式使进程终止:
- 正常终止:在
- 在main中执行return或隐含的离开main函数。
- 调用e x i t。
- 调用 _ e x i t。
(2) 异常终止:调用 a b o r t。 由一个信号终止。
abort()函数
功能:异常终止一个进程(abort()函数导致所有的流被关闭和冲洗。)
包含头文件: #include <stdlib.h>
函数原型
void abort(void);
atexit()函数
功能:注册一个函数在exit退出时调用。
包含头文件: #include <stdlib.h>
函数原型
int atexit(void (*function)(void));
on_exit()函数
功能:正常结束当前调用函数。用来设置一个程序正常结束前调用的函数,当程序通过调用exit()或者从main中返回时,参数func所指定的函数先会被调用,然后才真正由exit()结束程序,参数arg指针会传给func函数。
包含头文件 #include <stdlib.h>
函数原型
int on_exit(void (*function)(int , void *), void *arg);
返回:如果执行成功则返回0;否则返回-1,错误原因存储在errno中。
exit()函数
功能:用于退出进程。exit()用来正常结束当前进程的执行,并把参数status返回到父进程,而进程所以的缓冲区数据会自动写回并关闭文件。
包含头文件 #include <stdlib.h>
函数原型
void exit(int status);
返回:成功没有返回值,失败返回-1,失败原因存储在errno中。
exit与return的区别
- return退出当前函数主体,exit()函数退出当前进程,因此,在main函数里面return(0)和exit(0)完成一样的功能。
- return仅仅从子函数中返回,而子进程用exit()退出,调用exit()时要调用一段终止处理程序,然后关闭所有I/O流。
例程:exit与return的区别

_exit()函数
_exit不会调用任何注册函数退出进程。_exit()函数用来正常结束当前进程的执行,把参数status返回给父进程,并关闭文件。此函数调用后不会返回,而是传递SIGCHID信号给父进程,父进程可以通过wait函数取得获得子进程的结束状态,_exit()不会处理标准I/O缓冲区,如果要更新需要调用exit()。
函数原型
void _exit(int status);
例程:exit()和_exit()的区别

进程间通信
进程是一个独立的资源分配单元,不同进程之间资源是独立的,没有关联,不能在一个进程中直接访问另一个进程的资源(例如打开的文件描述符),但是,进程不是孤立的,不同进程之间需要进行信息的交互和状态的传递,因此需要进程间数据传递、同步及异步的机制。linux提供了大量进程间通信机制来实现同一主机两个进程间的通信。此外,还提供了网络主机间进程通信的机制。
1、同主机进程间数据交互机制:无名管道(PIPE)、有名管道(FIFO)、消息队列(Message Queue)和共享内存(Share Memory)。
2、同主机进程间同步机制:信号量(semaphore)。
3、同主机进程间异步机制:信号(Signal)。
4、网络主机间数据交互机制:套接口(Socket)。
linux操作系统支持的进程间通信机制

PIPE—无名管道
概念:无名管道通信是单工的。用来实现进程间通信的特殊文件。无名管道只能存在于进程通信期间,通信完成后将自动消失,且只能载具有亲缘关系的进程间实现通信,而且只能临时存放通信的信息,不能像普通文件一样存储大量常规信息。可以使用read/write等函数进行读写操作,但不能使用lseek函数来修订当前的读写位置,因为管道要满足FIFO的原则。一个管道不能同时被两个进程打开。
使用:一个进程在由pipe()创建管道后,一般再fork一个子进程,然后通过管道实现父子进程间的通信(因此也不难推出,只要两个进程中存在亲缘关系,这里的亲缘关系指的是具有共同的祖先,都可以采用管道方式来进行通信)。
特点:
1、管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道;
2、只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
3、单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
4、数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
局限性:
1、管道的主要局限性正体现在它的特点上:
2、只支持单向数据流;
3、只能用于具有亲缘关系的进程之间;
4、没有名字;
5、管道的缓冲区是有限的(管道制存在于内存中,在管道创建时,为缓冲区分配一个页面大小);
6、管道所传送的是无格式字节流,这就要求管道的读出方和写入方必须事先约定好数据的格式,比如多少字节算作一个消息(或命令、或记录)等等;
管道读写规则
管道两端可分别用描述字fd[0]以及fd[1]来描述,需要注意的是,管道的两端是固定了任务的。即一端只能用于读,由描述字fd[0]表示,称其为管道读端;另一端则只能用于写,由描述字fd[1]来表示,称其为管道写端。如果试图从管道写端读取数据,或者向管道读端写入数据都将导致错误发生。一般文件的I/O函数都可以用于管道,如close、read、write等等。
从管道中读取数据:
如果管道的写端不存在,则认为已经读到了数据的末尾,读函数返回的读出字节数为0;
当管道的写端存在时,如果请求的字节数目大于PIPE_BUF,则返回管道中现有的数据字节数,如果请求的字节数目不大于PIPE_BUF,则返回管道中现有数据字节数(此时,管道中数据量小于请求的数据量);或者返回请求的字节数(此时,管道中数据量不小于请求的数据量)。注:(PIPE_BUF在include/linux/limits.h中定义,不同的内核版本可能会有所不同。
向管道中写入数据:
向管道中写入数据时,linux将不保证写入的原子性,管道缓冲区一有空闲区域,写进程就会试图向管道写入数据。如果读进程不读走管道缓冲区中的数据,那么写操作将一直阻塞。
注意:只有在管道的读端存在时,向管道中写入数据才有意义。否则,向管道中写入数据的进程将收到内核传来的SIFPIPE信号,应用程序可以处理该信号,也可以忽略(默认动作则是应用程序终止)。
因此,在向管道写入数据时,至少应该存在某一个进程,其中管道读端没有被关闭,否则就会出现上述错误(管道断裂,进程收到了SIGPIPE信号,默认动作是进程终止)
创建无名管道
#include <unistd.h>
int pipe(int pipefd[2]);
参数:一个整型数组(下标为2)。
返回:如果执行成功,pipe将存储在两个整型文件描述符于pipefd[0](用来完成读操作)和pipefd[1](用来完成写操作)中,他们分别指向管道的两端。如果系统调用失败,返回-1。
读无名管道
功能:将从fd所指文件中读取n字节内容存储在buf所指的临时空间中。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count); //采用无缓冲I/O方式实现。
参数:
成功返回实际读取的字节数。
失败,返回-1;如果读取的字节数小于n,则返回读取的字节数。
如果读到末端,返回0.
读一个空管道,将会阻塞。
写无名管道
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
功能:从buf指向的缓冲区中向管道中写入nbytes字节,且每次写入的内容都附加在管道末端。
文件描述符重定向 dup()和dup2()函数
- shell重定向基本操作。
- 复制文件描述符
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);
流重定向popen函数和pclose函数
#include <stdio.h>
FILE *popen(const char *command, const char *type);
int pclose(FILE *stream);
例程:使用无名管道,该程序在子进程中写入数据,在父进程中读取数据

FIFO—有名管道
概念:FIFO不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存在于文件系统中。这样,即使与FIFO的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过FIFO相互通信(能够访问该路径的进程以及FIFO的创建进程之间),因此,通过FIFO不相关的进程也能交换数据。值得注意的是,FIFO严格遵循先进先出(first in first out),对管道及FIFO的读总是从开始处返回数据,对它们的写则把数据添加到末尾。它们不支持诸如lseek()等文件定位操作。
有名管道是一个存在的特殊文件,可以在不同进程间通信。可以通过read/write系统调用读写。用户可以通过shell来创建有名管道,也可以在linux下使用C函数创建。
特点:
FIFO的好处在于我们可以通过文件的路径来识别管道,从而让没有亲缘关系的进程之间建立连接
有名管道打开规则
有名管道比管道多了一个打开操作:open。
FIFO的打开规则:
如果当前打开操作是为读而打开FIFO时,若已经有相应进程为写而打开该FIFO,则当前打开操作将成功返回;否则,可能阻塞直到有相应进程为写而打开该FIFO(当前打开操作设置了阻塞标志);或者,成功返回(当前打开操作没有设置阻塞标志)。
如果当前打开操作是为写而打开FIFO时,如果已经有相应进程为读而打开该FIFO,则当前打开操作将成功返回;否则,可能阻塞直到有相应进程为读而打开该FIFO(当前打开操作设置了阻塞标志);或者,返回ENXIO错误(当前打开操作没有设置阻塞标志)。
有名管道读写规则
在使用名管道时,一定要使用两个进程分别打开其读端和写端。
从FIFO中读取数据:
约定:如果一个进程为了从FIFO中读取数据而阻塞打开FIFO,那么称该进程内的读操作为设置了阻塞标志的读操作。
如果有进程写打开FIFO,且当前FIFO内没有数据,则对于设置了阻塞标志的读操作来说,将一直阻塞。对于没有设置阻塞标志读操作来说则返回-1,当前errno值为EAGAIN,提醒以后再试。
对于设置了阻塞标志的读操作说,造成阻塞的原因有两种:当前FIFO内有数据,但有其它进程在读这些数据;另外就是FIFO内没有数据。解阻塞的原因则是FIFO中有新的数据写入,不论信写入数据量的大小,也不论读操作请求多少数据量。
读打开的阻塞标志只对本进程第一个读操作施加作用,如果本进程内有多个读操作序列,则在第一个读操作被唤醒并完成读操作后,其它将要执行的读操作将不再阻塞,即使在执行读操作时,FIFO中没有数据也一样(此时,读操作返回0)。
如果没有进程写打开FIFO,则设置了阻塞标志的读操作会阻塞。
注意:如果FIFO中有数据,则设置了阻塞标志的读操作不会因为FIFO中的字节数小于请求读的字节数而阻塞,此时,读操作会返回FIFO中现有的数据量。
向FIFO中写入数据:
约定:如果一个进程为了向FIFO中写入数据而阻塞打开FIFO,那么称该进程内的写操作为设置了阻塞标志的写操作。
对于设置了阻塞标志的写操作:
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。如果此时管道空闲缓冲区不足以容纳要写入的字节数,则进入睡眠,直到当缓冲区中能够容纳要写入的字节数时,才开始进行一次性写操作。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。FIFO缓冲区一有空闲区域,写进程就会试图向管道写入数据,写操作在写完所有请求写的数据后返回。
对于没有设置阻塞标志的写操作:
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。在写满所有FIFO空闲缓冲区后,写操作返回。
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。如果当前FIFO空闲缓冲区能够容纳请求写入的字节数,写完后成功返回;如果当前FIFO空闲缓冲区不能够容纳请求写入的字节数,则返回EAGAIN错误,提醒以后再写;
创建有名管道mkfifo函数
功能:创建有名管道
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
参数:成功返回0,否则返回-1,失败原因存储于errno中。
注意:
该函数的第一个参数是一个普通的路径名,也就是创建后FIFO的名字。第二个参数与打开普通文件的open()函数中的mode 参数相同。 如果mkfifo的第一个参数是一个已经存在的路径名时,会返回EEXIST错误,所以一般典型的调用代码首先会检查是否返回该错误,如果确实返回该错误,那么只要调用打开FIFO的函数就可以了。一般文件的I/O函数都可以用于FIFO,如close、read、write等等。
用户也可以在命令行使用 “mknod <管道名>”来创建有名管道。
读写有名管道
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
注意:在读写有名管道文件之前,需要使用open()函数打开该有名管道。打开有名管道与打开一般文件操作有区别:如果要打开管道写端,则需要另一进程打开管道读端,整个程序才能正常进行。如果只打开有名管道的一端,则系统将暂时阻塞打开进程,直到有另一个进程打开该管道的另一端,当前进程才会继续执行。因此,在使用有名管道时,一定要使用两个进程分别打开其读端和写端。
例程:非亲缘关系的两个进程使用有名管道通信
写进程 fifo_write.c

读进程 fifo_read.c

两个程序编译后,先运行写程序

可以看出,因为此时还没有进程打开读端,所以在程序会阻塞在open函数,接着我们用另一个终端来执行读程序。

同时,我们可以看到之前阻塞的写程序继续执行了(下图中的后面三行就是执行读端后,写程序继续执行之后打印的信息)

信号
linux提供的信号机制是一种进程间异步的通信机制,在实现上是一种软中断。
产生一个信号的方式有多种,来源也有多种。
信号是与一定的进程相联系的。也就是说,一个进程可以决定在进程中对哪些信号进行什么样的处理。例如,一个进程可以忽略某些信号而只处理其他一些信号;另外,一个进程还可以选择如何处理信号。总之,这些总与特定的进程相联系的。因此,首先要建立其信号和进程的对应关系,这就是信号的安装登记。
Linux主要有两个函数实现信号的安装登记:signal和sigaction。其中signal在系统调用的基础上实现,是库函数。它只有两个参数,不支持信号传递信息,主要是用于前32个非实时信号的安装;而sigaction是较新的函数(由两个系统调用实现:sys_signal以及sys_rt_sigaction),有三个参数,支持信号传递信息,主要用来与sigqueue系统调用配合使用。当然,sigaction同样支持非实时信号的安装,sigaction优于signal主要体现在支持信号带有参数。
信号处理流程:对于应用程序自行处理的信号来说,信号的生命周期要经过信号的安装登记、信号集操作、信号的发送和信号的处理四个阶段。信号的安装登记指的是在应用程序中,安装对此信号的处理方法。信号集操作的作用是用于对指定的一个或多个信号进行信号屏蔽,此阶段对有些应用程序来说并不需要。信号的发送指的是发送信号,可以通过硬件(如在终端上按下Ctrl-C)发送的信号和软件(如通过kill函数)发送的信号。信号的处理指的是操作系统对接收信号进程的处理,处理方法是先检查信号集操作函数是否对此信号进行屏蔽,如果没有屏蔽,操作系统将按信号安装函数中登记注册的处理函数完成对此进程的处理。
传递一个信号给指定的进程应使用kill()函数,传递一个信号给当前进程则使用raise()函数,唤醒一个进程和设置定时使用alarm()函数。
信号事件的发生有两个来源:
硬件来源(比如我们按下了键盘或者其它硬件故障),例如在键盘按下Ctrl +c 产生SIGINT信号,按下ctrl+\ 产生SIGQUIT信号,按下Ctrl-Z产生SIGTSTP信号(可使前台进程停止),其他硬件故障比如当前进程执行了除以0的指令,CPU的运算单元会产生异常,内核将这个异常解释为SIGFPE信号发送给进程,再比如当前进程访问了非法内存地址,MMU会产生异常,内核将这个异常解释为SIGSEGV信号发送给进程;
软件来源,最常用发送信号的系统函数是kill, raise, alarm和setitimer以及sigqueue函数,软件来源还包括一些非法运算等操作。
信号的种类:可以从两个不同的分类角度对信号进行分类:(1)可靠性方面:可靠信号与不可靠信号;(2)与时间的关系上:实时信号与非实时信号。
非实时信号都不支持排队,都是不可靠信号;实时信号都支持排队,都是可靠信号。
进程对信号的响应:
进程可以通过三种方式来响应一个信号:
(1)忽略信号,即对信号不做任何处理,其中,有两个信号不能忽略:SIGKILL及SIGSTOP;(2)捕捉信号。定义信号处理函数,当信号发生时,执行相应的处理函数;
(3)执行缺省操作,Linux对每种信号都规定了默认操作。注意,进程对实时信号的缺省反应是进程终止。
Linux究竟采用上述三种方式的哪一个来响应信号,取决于传递给相应API函数的参数。
信号的优先级:
信号实质上是软中断,中断有优先级,信号也有优先级。如果一个进程有多个未决信号,则对于同一个未决的实时信号,内核将按照发送的顺序来递送信号。如果存在多个未决信号,则值(或者说编号)越小的越先被递送。如果即存在不可靠信号,又存在可靠信号(实时信号),虽然POSIX对这一情况没有明确规定,但Linux系统和大多数遵循POSIX标准的操作系统一样,将优先递送不可靠信号。
发送信号的主要函数有:kill()、raise()、 sigqueue()、alarm()、setitimer()以及abort()。
发送信号kill()函数
功能:传递一个信号给指定的进程。
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);
参数:
p i d > 0 将信号发送给进程 I D为p i d的进程。
p i d = 0 将信号发送给和当前进程在同一进程组的所有进程。
pid < 0 将信号发送给其进程组号PGID为p i d绝对值的所有进程。
pid == - 1 将信号发送给系统内的所有进程。
返回:成功返回0,;否则返回0,并设置errno以指示错误。
shell的kill命令
标准的kill命令通常都能达到目的。终止有问题的进程,并把进程的资源释放给系统。然而,如果进程启动了子进程,只杀死父进程,子进程仍在运行,因此仍消耗资源。为了防止这些所谓的“僵尸进程”,应确保在杀死父进程之前,先杀死其所有的子进程。
用法
kill [信号或选项] PID(s)
默认信号(当没有指定的时候)是SIGTERM。当它不起作用时,你可以使用下面的命令来强制kill掉一个进程:
kill SIGKILL PID
或者
kill -9 PID
这里"-9"代表着SIGKILL信号。
kill –l可以查看信号的列表。

也可以通过kill –l 信号名,获得指定信号的数值。
注意:
init进程是不可以杀掉的。
通过命令ps -aux可以得到pid 。
可以同一时间kill多个进程。
发送信号 raise()函数
功能:用来向当前进程发送一个信号,即唤醒一个进程。
#include <signal.h>
int raise(int sig);
返回:成功返回0,;否则返回-1,并设置errno以指示错误。
定时发送信号alarm()函数
功能:用来向当前进程发送一个信号,即唤醒一个进程。
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
返回:
每个进程只能有一个闹钟时间。如果在调用 a l a r m时,以前已为该进程设置过闹钟时间,而且它还没有超时,则该闹钟时间的余留值作为本次 a l a r m函数调用的值返回。以前登记的闹钟时间则被新值代换。
如果有以前登记的尚未超过的闹钟时间,而且 s e c o n d s值是0,则取消以前的闹钟时间,其余留值仍作为函数的返回值。
虽然S I G A L R M的默认动作是终止进程,但是大多数使用闹钟的进程捕捉此信号。如果此时进程要终止,则在终止之前它可以执行所需的清除操作。
定时发送信号ualarm()函数
功能:使当前进程在指定时间内(第一个参数)产生SIGALRM信号,然后每隔指定时间(第二个参数)重复产生SIGALRM信号。
#include <unistd.h>
useconds_t ualarm(useconds_t usecs, useconds_t interval);
参数:两个参数,都以us为单位。
返回:成功返回0。
发送终止信号 abort()函数
功能:abort()函数首先解除进程对SIGABRT信号的阻止,然后向调用进程发送该信号,默认情况下进程会异常退出,当然可定义自己的信号处理函数。即使SIGABORT被进程设置为阻塞信号,调用abort()后,SIGABORT仍然能被进程接收。该函数无返回值。
#include <stdlib.h>
void abort(void);
发送信号sigqueue()函数
#include <sys/types.h>
#include <signal.h>
int sigqueue(pid_t pid, int sig, const union sigval val)
函数返回
调用成功返回 0;否则,返回 -1。
sigqueue()是比较新的发送信号系统调用,主要是针对实时信号提出的(当然也支持前32种),支持信号带有参数,与函数sigaction()配合使用。
函数参数
sigqueue的第一个参数是指定接收信号的进程ID,第二个参数确定即将发送的信号,第三个参数是一个联合数据结构union sigval,指定了信号传递的参数,即通常所说的4字节值。
typedef union sigval {
int sival_int;
void *sival_ptr;
}sigval_t;
sigqueue()比kill()传递了更多的附加信息,但sigqueue()只能向一个进程发送信号,而不能发送信号给一个进程组。如果signo=0,将会执行错误检查,但实际上不发送任何信号,0值信号可用于检查pid的有效性以及当前进程是否有权限向目标进程发送信号。
在调用sigqueue时,sigval_t指定的信息会拷贝到3参数信号处理函数(3参数信号处理函数指的是信号处理函数由sigaction安装,并设定了sa_sigaction指针)的siginfo_t结构中,这样信号处理函数就可以处理这些信息了。由于sigqueue系统调用支持发送带参数信号,所以比kill()系统调用的功能要灵活和强大得多。
注意:sigqueue()发送非实时信号时,第三个参数包含的信息仍然能够传递给信号处理函数; sigqueue()发送非实时信号时,仍然不支持排队,即在信号处理函数执行过程中到来的所有相同信号,都被合并为一个信号。
定时发送信号setitimer()函数
函数功能:实现延时和定时
#include <sys/time.h>
int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue));
setitimer()比alarm功能强大,支持3种类型的定时器:
ITIMER_REAL:设定绝对时间;经过指定的时间后,内核将发送SIGALRM信号给本进程;
ITIMER_VIRTUAL:设定程序执行时间;经过指定的时间后,内核将发送SIGVTALRM信号给本进程;
ITIMER_PROF:设定进程执行以及内核因本进程而消耗的时间和,经过指定的时间后,内核将发送ITIMER_VIRTUAL信号给本进程;
函数参数:
Setitimer()第一个参数which指定定时器类型(上面三种之一);第二个参数是结构itimerval的一个实例,结构itimerval形式参考下文。第三个参数可不做处理。
函数返回:
Setitimer()调用成功返回0,否则返回-1。
结构itimerval:
struct itimerval {
struct timeval it_interval; /* next value */
struct timeval it_value; /* current value */
};
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
等待信号pause()函数
功能:pause函数用来等待除当前进程阻塞信号外任意信号。
使调用进程挂起直至捕捉到一个信号,才重新恢复执行。
#include <unistd.h>
int pause(void);
返回:只有执行了一个信号处理程序并从其返回时, p a u s e才返回。p a u s e始终返回- 1 ,e r r n o设置为E I N T R。
等待信号sigsuspend()函数
功能:sigsuspend函数用来等待除指定信号外(由其参数指定)的任意信号。
将调用进程 阻塞的信号集 替换为其参数值,然后挂起该线程,知道传递一个非指定集合中信号为止。
#include <signal.h>
int sigsuspend(const sigset_t *mask);
返回:只有执行了一个信号处理程序并从其返回时, p a u s e才返回。p a u s e始终返回- 1 ,e r r n o设置为E I N T R。
sigsuspend的整个原子操作过程为:
(1) 设置新的mask阻塞当前进程;
(2) 收到信号,恢复原先mask;
(3) 调用该进程设置的信号处理函数;
(4) 待信号处理函数返回后,sigsuspend返回。
安装信号signal()函数
| signal(设置信号处理方式) |
||
| 所需头文件 |
#include <signal.h> |
|
| 函数说明 |
设置信号处理方式。signal()会依参数signum指定的信号编号来设置该信号的处理函数。当指定的信号到达时就会跳转到参数handler指定的函数执行 |
|
| 函数原型 |
void (*signal(int signum,void(* handler)(int)))(int) |
|
| 函数传入值
|
signum |
指定信号编号 |
| handle |
SIG_IGN:忽略参数signum指定的信号 |
|
| SIG_DFL:将参数signum指定的信号重设为核心预设的信号处理方式,即采用系统默认方式处理信号 |
||
| 自定义信号函数处理指针 |
||
| 函数返回值 |
成功 |
返回先前的信号处理函数指针 |
| 出错 |
SIG_ERR(-1) |
|
| 附加说明 |
在Unix环境中,在信号发生跳转到自定的handler处理函数执行后,系统会自动将此处理函数换回原来系统预设的处理方式,如果要改变此情形请改用sigaction函数。在Linux环境中不存在此问题 |
|
signal函数原型比较复杂,如果使用下面的typedef,则可使其简化。
typedef void sign(int);
sign *signal(int, handler *);
可见,该函数原型首先整体指向一个无返回值带一个整型参数的函数指针,也就是信号的原始配置函数。接着该原型又带有两个参数,其中的第二个参数可以是用户自定义的信号处理函数的函数指针。对这个函数格式可以不理解,但需要学会模仿使用。

安装信号 sigaction()函数
sigaction函数用来查询和设置信号处理方式,它是用来替换早期的signal函数。
| 所需头文件 |
#include <signal.h> |
|
| 函数说明 |
sigaction()会依参数signum指定的信号编号来设置该信号的处理函数 |
|
| 函数原型 |
int sigaction(int signum,const struct sigaction *act ,struct sigaction *oldact) |
|
| 函数传入值
|
signum |
可以指定SIGKILL和SIGSTOP以外的所有信号 |
| act |
参数结构sigaction定义如下 struct sigaction { void (*sa_handler) (int); void (*sa_sigaction)(int, siginfo_t *, void *); sigset_t sa_mask; int sa_flags; void (*sa_restorer) (void); } ① sa_handler:此参数和signal()的参数handler相同,此参数主要用来对信号旧的安装函数signal()处理形式的支持 ② sa_sigaction:新的信号安装机制,处理函数被调用的时候,不但可以得到信号编号,而且可以获悉被调用的原因以及产生问题的上下文的相关信息。 ③ sa_mask:用来设置在处理该信号时暂时将sa_mask指定的信号搁置 ④ sa_restorer: 此参数没有使用 ⑤ sa_flags:用来设置信号处理的其他相关操作,下列的数值可用。可用OR 运算(|)组合 A_NOCLDSTOP:如果参数signum为SIGCHLD,则当子进程暂停时并不会通知父进程 SA_ONESHOT/SA_RESETHAND:当调用新的信号处理函数前,将此信号处理方式改为系统预设的方式 SA_RESTART:被信号中断的系统调用会自行重启 SA_NOMASK/SA_NODEFER:在处理此信号未结束前不理会此信号的再次到来 SA_SIGINFO:信号处理函数是带有三个参数的sa_sigaction |
|
| oldact |
如果参数oldact不是NULL指针,则原来的信号处理方式会由此结构sigaction返回 |
|
| 函数返回值 |
成功:0 |
|
| 出错:-1,错误原因存于error中 |
||
| 附加说明 |
信号处理安装的新旧两种机制: ① 使用旧的处理机制:struct sigaction act; act.sa_handler=handler_old; ② 使用新的处理机制:struct sigaction act; act.sa_sigaction=handler_new; 并设置sa_flags的SA_SIGINFO位 |
|
| 错误代码 |
EINVAL:参数signum不合法,或是企图拦截SIGKILL/SIGSTOP信号 EFAULT:参数act,oldact指针地址无法存取 EINTR:此调用被中断 |
|
例程1:信号发生及处理

例程2:信号传递附加信息

该例程是发生信号给本进程,如果想实现不同进程间发送信号传递参数,就需要相应进程的pid作为sigqueue函数的参数。
signal()和sigaction()函数的区别
它们都不能把SIGRTMIN以前的信号变成可靠信号(都不支持排队,仍有可能丢失,仍然是不可靠信号) ,而且对SIGRTMIN以后的信号都支持排队。这两个函数的最大区别在于,经过sigaction安装的信号都能传递信息给信号处理函数,而经过signal安装的信号不能向信号处理函数传递信息。对于信号发送函数来说也是一样的。
信号集
信号忽略:系统仍然传递该信号,只是相应进程对该信号不作任何处理而已。
信号阻塞:系统不传递该信号,显示该进程无法接收到该信号,知道进程的信号集发生改变。
注意:阻塞和忽略是不同的,只要信号被阻塞就不会递达,而忽略是在递达之后可选的一种处理动作。
linux使用信号集的概念来管理阻塞信号,可以设置某个进程阻塞某个集合中的信号。
一个进程的信号屏蔽字规定了当前阻塞而不能递送给该进程的信号集。
信号集操作函数
由于有时需要把多个信号当作一个集合进行处理,这样信号集就产生了,信号集用来描述一类信号的集合,Linux所支持的信号可以全部或部分的出现在信号集中。信号集操作函数最常用的地方就是用于信号屏蔽。比如有时候希望某个进程正确执行,而不想进程受到一些信号的影响,此时就需要用到信号集操作函数完成对这些信号的屏蔽。
信号集操作函数按照功能和使用顺序分为三类,分别为创建信号集函数,设置信号屏蔽位函数和查询被搁置(未决)的信号函数。创建信号集函数只是创建一个信号的集合,设置信号屏蔽位函数对指定信号集中的信号进行屏蔽,查询被搁置的信号函数是用来查询当前“未决”的信号集。信号集函数组并不能完成信号的安装登记工作,信号的安装登记需要通过sigaction函数或signal函数来完成。
查询被搁置的信号是信号处理的后续步骤,但不是必需的。由于有时进程在某时间段内要求阻塞一些信号,程序完成特定工作后解除对该信号阻塞,这个时间段内被阻塞的信号称为“未决”信号。这些信号已经产生,但没有被处理,sigpending函数用来检测进程的这些“未决”信号,并进一步决定对它们做何种处理(包括不处理)。
创建信号集函数(5个)
① sigemptyset:初始化信号集合为空。
② sigfillset:把所有信号加入到集合中,信号集中将包含Linux支持的64种信号。
③ sigaddset:将指定信号加入到信号集合中去。
④ sigdelset:将指定信号从信号集中删去。
⑤ sigismember:查询指定信号是否在信号集合之中。
| 创建信号集合函数原型 |
|
| 所需头文件 |
#include <signal.h> |
| 函数原型 |
int sigemptyset(sigset_t *set) |
| int sigfillset(sigset_t *set) |
|
| int sigaddset(sigset_t *set,int signum) |
|
| int sigdelset(sigset_t *set,int signum) |
|
| int sigismember(sigset_t *set,int signum) |
|
| 函数传入值 |
set:信号集 |
| signum:指定信号值 |
|
| 函数返回值 |
成功:0(sigismember函数例外,成功返回1,失败返回 0) |
| 出错:-1,错误原因存于error中 |
|
设置或检测信号屏蔽位 sigprocmask()函数
一个进程的信号屏蔽字规定了当前阻塞而不能递送给该进程的信号集。sigprocmask()可以用来检测或改变目前的信号屏蔽字,其操作依参数how来决定,如果参数oldset不是NULL指针,那么目前的信号屏蔽字会由此指针返回。如果set是一个非空指针,则参数how指示如何修改当前信号屏蔽字。每个进程都有一个用来描述哪些信号递送到进程时将被阻塞的信号集,该信号集中的所有信号在递送到进程后都将被阻塞。
注意:sigprocmask()函数只为单线程的进程定义的,在多线程中要使用pthread_sigmask变量,在使用之前需要声明和初始化。
函数原型及说明如下:
sigprocmask(设置或检测信号屏蔽位)
| 所需头文件 |
#include <signal.h> |
|
| 函数原型 |
int sigprocmask(int how,const sigset_t *set,sigset_t *oset) |
|
| 函数传入值 |
how(决定函数的操作方式) |
SIG_BLOCK:增加一个信号集合到当前进程的阻塞集合之中 |
| SIG_UNBLOCK:从当前的阻塞集合之中删除一个信号集合 |
||
| SIG_SETMASK:将当前的信号集合设置为信号阻塞集合 |
||
| set:指定信号集 |
||
| oset:信号屏蔽字 |
||
| 函数返回值 |
成功:0 |
|
| 出错:-1,错误原因存于error中 错误原因: EFAULT:参数set,oldset指针地址无法存取 EINTR: 此调用被中断 |
||
查询被搁置(未决)信号 sigpending函数
信号产生到信号被处理这段时间间隔,称信号是未决的(pending)。
sigpending函数用来查询“未决”信号。获得当前已递送到进程,却被阻塞的所有信号,在set指向的信号集中返回结果。
其函数原型及说明如下:
sigpending(查询未决信号)
| 所需头文件 |
#include <signal.h> |
| 函数说明 |
被搁置的信号集由参数set指针返回 |
| 函数原型 |
int sigpending(sigset_t *set) |
| 函数传入值 |
set:要检测信号集 |
| 函数返回值 |
成功:0 |
| 出错:-1,错误原因存于error中 |
|
| 错误代码 |
EFAULT:参数set指针地址无法存取 EINTR:此调用被中断 |
对信号集操作函数的使用方法和步骤
对信号集操作函数的使用方法和顺序如下:
① 使用signal或sigaction函数安装和登记信号的处理。
② 使用sigemptyset等定义信号集函数完成对信号集的定义。
③ 使用sigprocmask函数设置信号屏蔽位。
④ 使用sigpending函数检测未决信号,非必需步骤。
其他信号集操作函数
int sigisemptyset(sigset_t *set); //检测信号集是否为空
int sigorset(sigset_t *dest, sigset_t *left, sigset_t *right); //按逻辑或方式将两个信号集并。
int sigandset(sigset_t *dest, sigset_t *left, sigset_t *right);//按逻辑与方式将两个信号集并。
例程
首先使用sigaction函数对SIGINT信号进行安装登记,安装登记使用了新旧两种机制,其中#if 0进行注释掉的部分为信号安装的新机制。接着程序把SIGQUIT、SIGINT两个信号加入信号集,并把该信号集设为阻塞状态。程序开始睡眠10秒,此时用户按下Ctrl+C,程序将测试到此未决信号(SIGINT);随后程序再睡眠10秒后对SIGINT信号解除阻塞,此时将处理SIGINT登记的信号函数my_func。最后可以用SIGQUIT(Ctrl+\)信号结束进程执行。

消息队列
消息队列就是一个消息的链表。可以把消息看作一个记录,具有特定的格式以及特定的优先级。对消息队列有写权限的进程可以向中按照一定的规则添加新消息;对消息队列有读权限的进程则可以从消息队列中读走消息。消息队列是随内核持续的,随内核持续的是指IPC一直持续到内核重新自举或者显示删除该对象为止。如消息队列、信号量以及共享内存等;
ID值概念:linux系统为每一个IPC机制都分配了唯一的ID,所以针对该IPC机制的操作都使用对应的ID。
key值概念:IPC在实现时约定使用key值作为参数创建,如果在创建时使用相同的key值将得到同一个IPC对象的ID(即一方创建,另一方获取的是ID)。
对消息队列的操作
1、 打开或创建消息队列
消息队列的内核持续性要求每个消息队列都在系统范围内对应唯一的键值,所以,要获得一个消息队列的标识符,只需提供该消息队列的键值即可;
注:消息队列标识符是由在系统范围内唯一的键值生成的,而键值可以看作对应系统内的一条路经。
2、 读写操作
消息读写操作非常简单,对开发人员来说,每个消息都类似如下的数据结构:
/* message buffer for msgsnd and msgrcv calls */
struct msgbuf {
__kernel_long_t mtype; /* type of message消息类型,必须大于0 */
char mtext[1]; /* message text 消息内容,mtext虽然定义为char类型,并不代表消息只能是一个字符,消息内容可以为任意类型,在使用时自己重新定义此结构。*/
};
mtype成员代表消息类型,从消息队列中读取消息的一个重要依据就是消息的类型;mtext是消息内容,当然长度不一定为1。因此,对于发送消息来说,首先预置一个msgbuf缓冲区并写入消息类型和内容,调用相应的发送函数即可;对读取消息来说,首先分配这样一个msgbuf缓冲区,然后把消息读入该缓冲区即可。
3、 获得或设置消息队列属性
消息队列的信息基本上都保存在消息队列头中,因此,可以分配一个类似于消息队列头的结构struct msqid_ds,来返回消息队列的属性;同样可以设置该数据结构。
消息队列属性
这三个宏定义分别表示最大消息队列个数、消息最大值、默认消息队列大小。
#define MSGMNI 32000 /* <= IPCMNI */ /* max # of msg queue identifiers */
#define MSGMAX 8192 /* <= INT_MAX */ /* max size of message (bytes) */
#define MSGMNB 16384 /* <= INT_MAX */ /* default max size of a message queue */
结构mag_msg是整个消息队列的主体,一个消息队列有若干个消息,每个消息数据结构的基本属性包括消息类型、消息大小、消息内容指针和下一个消息数据结构位置。
(注意:该结构体是内核保存消息队列的格式)
/* one msg_msg structure for each message */
struct msg_msg {
struct list_head m_list;
long m_type; //消息类型
size_t m_ts; /* message text size消息大小 */
struct msg_msgseg *next; //下一个消息位置
void *security; //真正的消息位置
/* the actual message follows immediately */
};
结构msg_queue用来描述消息队列头,存在于系统空间:
/* one msq_queue structure for each present queue on the system */
struct msg_queue {
struct kern_ipc_perm q_perm;
time64_t q_stime; /* last msgsnd time */
time64_t q_rtime; /* last msgrcv time */
time64_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
} __randomize_layout;
linux内核中,每个消息队列都维护一个结构体msqid_ds ,此结构体保存着消息队列当前的状态信息。主要包括整个消息队列的权限,包括拥有者和操作权限等信息,另外还包括两个重要的指针分别指向消息队列的第一个消息和最后一个消息。(用来设置或返回消息队列的信息,存在于用户空间)
/* Obsolete, used only for backwards compatibility and libc5 compiles */
struct msqid_ds {
struct ipc_perm msg_perm;
struct msg *msg_first; /* first message on queue,unused */
struct msg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */
unsigned long msg_lqbytes; /* ditto */
unsigned short msg_cbytes; /* current number of bytes on queue */
unsigned short msg_qnum; /* number of messages in queue */
unsigned short msg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
结构体ipc_perm保存着消息队列的一些重要的信息,比如消息队列关联的键值,消息队列的用户ID,组ID等。(在ipc.h中)
struct ipc_perm
{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
内核与消息队列的联系

创建key值 ftok()函数
函数功能:创建key值,使用相同的文件路径及整数(第二个参数),得到的key值是唯一的,唯一的key值创建某类IPC机制时将得到同一个IPC机制。
头文件
#include <sys/types.h>
#include <sys/ipc.h>
函数原型
key_t ftok(const char *pathname, int proj_id);
函数参数
const char *pathname 文件路径名,可以是特殊文件(例如目录文件),也可以是当前目录“.”,通常设置此参数为当前目录,因为当前目录一般都存在,且不会被立即删除
int proj_id 一个int型变量
函数返回
成功返回key值
创建消息队列 msgget()函数
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
函数原型
int msgget(key_t key, int msgflg);
函数参数
key_t key key值,由ftok()获得
int msgflg 标志位,可以是:
IPC_CREAT 如果key不存在,则创建,存在,返回ID
IPC_EXCL 如果key存在,返回失败
IPC_NOWAIT 如果需要等待,直接返回错误
或三者的或结果。
函数返回:成功返回消息队列标识符,否则返回-1。
发送信息到消息队列msgsnd()函数
函数功能:向msgid代表的消息队列发送一个消息,即将发送的消息存储在msgp指向的msgbuf结构中,消息的大小由msgze指定。
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
函数原型
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
函数参数
int msqid 指定的消息队列标识符(由msgget函数生成的),将消息添加到哪个消息队列中
const void *msgp 指定的用户定义缓冲区:
/* message buffer for msgsnd and msgrcv calls */
struct msgbuf {
__kernel_long_t mtype; //消息类型,必须大于0
char mtext[1]; //消息内容,在使用时自己重新定义此结构*/
};
size_t msgsz 接收信息的大小,即mtext的长度(以字节为单位),
其大小为0到系统对消息队列的限制值
int msgflg 用来指定在达到系统为消息队列所定的界限时应采取的操作。
如果设置为IPC_NOWAIT,如果需要等待,则不发送消息并且调用进程立即返回错误信息EAGAIN。
函数返回
成功返回0,否则返回-1。同时对消息队列msqid数据结构的成员执行以下操作:
msg_qnum以1的增量增加
msg_lspid设置为调用进程的进程ID
msg_stime设置为当前时间
从消息队列接收信息msgrcv()函数
函数功能:该系统调用从msgid代表的消息队列中读取一个消息,并把消息存储在msgp指向的msgbuf结构中。
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
函数原型
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
函数参数
int msqid 消息队列标识符;
void *msgp 消息返回后存储在msgp指向的地址,
size_t msgsz msgsz指定msgbuf的mtext成员的长度(即消息内容的长度),
long msgtyp 请求读取的消息类型:
等于0 则返回队列的最早的一个消息。
大于0,则返回其类型为mtype的第一个消息。
小于0,则返回其类型小于或等于mtype参数的绝对值的最小的一个消息。
int msgflg 读消息标志msgflg可以为以下几个常值的或:
IPC_NOWAIT 如果没有满足条件的消息,调用立即返回,此时,errno=ENOMSG
IPC_EXCEPT 与msgtyp>0配合使用,返回队列中第一个类型不为msgtyp的消息
IPC_NOERROR 如果队列中满足条件的消息内容大于所请求的msgsz字节,则把该消息截断,截断部分将丢失。
函数返回:成功返回读出消息的实际字节数,否则返回-1。同时对消息队列msqid数据结构的成员执行以下操作:
msg_qnum以1的减量递减
msg_lspid设置为调用进程的进程ID
msg_stime设置为当前时间
消息队列属性控制 msgctl()函数
函数功能:该系统调用对由msqid标识的消息队列执行cmd操作
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
函数原型
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
函数参数
int msqid 消息队列标识符(由msgget函数生成的)
int cmd 执行的控制命令,即要执行的操作,如下:
IPC_STAT:该命令用来获取消息队列信息,返回的信息存贮在buf指向的msqid结构中;
IPC_SET:该命令用来设置消息队列的属性,要设置的属性存储在buf指向的msqid结构中;可设置属性包括:msg_perm.uid、msg_perm.gid、msg_perm.mode以及msg_qbytes,同时,也影响msg_ctime成员。
IPC_RMID:删除msqid标识的消息队列;
struct msqid_ds *buf 用来存储读取的消息队列属性或者需要修改的消息队列属性。
函数返回
成功返回0,否则返回-1。
例程

信号量
信号量IPC原理
信号量与其他进程间通信方式不大相同,它主要提供对进程间共享资源访问控制机制。相当于内存中的标志,进程可以根据它判定是否能够访问某些共享资源,同时,进程也可以修改该标志。除了用于访问控制外,还可用于进程同步。信号量有以下两种类型:
二值信号量:最简单的信号量形式,信号量的值只能取0或1,类似于互斥锁。
注:二值信号量能够实现互斥锁的功能,但两者的关注内容不同。信号量强调共享资源,只要共享资源可用,其他进程同样可以修改信号量的值;互斥锁更强调进程,占用资源的进程使用完资源后,必须由进程本身来解锁。
计数信号量:信号量的值可以取任意非负值(当然受内核本身的约束)
内核与信号量的联系
系统V信号量是随内核持续的,只有在内核重起或者显示删除一个信号量集时,该信号量集才会真正被删除。因此系统中记录信号量的数据结构(struct ipc_ids sem_ids)位于内核中,系统中的所有信号量都可以在结构sem_ids中找到访问入口。
struct ipc_ids sem_ids是内核中记录信号量的全局数据结构;描述一个具体的信号量及其相关信息。

全局数据结构struct ipc_ids sem_ids可以访问到struct kern_ipc_perm的第一个成员:struct kern_ipc_perm;而每个struct kern_ipc_perm能够与具体的信号量对应起来是因为在该结构中,有一个key_t类型成员key,而key则唯一确定一个信号量集;同时,结构struct kern_ipc_perm的最后一个成员sem_nsems确定了该信号量在信号量集中的顺序,这样内核就能够记录每个信号量的信息了。
内核为每个信号量设置了一个 s e m i d _ d s结构。信号量集合数据结构:
/* Obsolete, used only for backwards compatibility and libc5 compiles */
struct semid_ds {
struct ipc_perm sem_perm; /* permissions .. see ipc.h */
__kernel_time_t sem_otime; /* last semop time */
__kernel_time_t sem_ctime; /* create/last semctl() time */
struct sem *sem_base; /* ptr to first semaphore in array */
struct sem_queue *sem_pending; /* pending operations to be processed */
struct sem_queue **sem_pending_last; /* last pending operation */
struct sem_undo *undo; /* undo requests on this array */
unsigned short sem_nsems; /* no. of semaphores in array */
};
每一个信号量结构
struct sem {
int semval; // current value
int sempid // pid of last operation
…….
}
/*
* SEMMNI, SEMMSL and SEMMNS are default values which can be
* modified by sysctl.
* The values has been chosen to be larger than necessary for any
* known configuration.
*
* SEMOPM should not be increased beyond 1000, otherwise there is the
* risk that semop()/semtimedop() fails due to kernel memory fragmentation when
* allocating the sop array.
*/
#define SEMMNI 32000 /* <= IPCMNI 系统中信号量集的最大数 */
//超过将返回ENOSPC错误。
#define SEMMSL 32000 /* <= INT_MAX每个信号量集中的最大信号量数*/
#define SEMMNS (SEMMNI*SEMMSL) /* <= INT_MAX 系统中信号量的最大数 */
//超过将返回ENOSPC错误。
#define SEMOPM 500 /* <= 1 000 每个semop调用所包含的最大操作数 */
//semop中的参数nsops如果超过了这个数目,将返回E2BIG错误。
#define SEMVMX 32767 /* <= 32767 任一信号量的最大值 */
//当设置信号量值超过这个限制时,会返回ERANGE错误。
#define SEMAEM SEMVMX /* 任一信号量的最大终止时调整值 */
SEMOPM以及SEMVMX是使用semop调用时应该注意的;SEMMNI以及SEMMNS是调用semget时应该注意的。SEMVMX同时也是semctl调用应该注意的。
/* unused */
#define SEMUME SEMOPM /* 每个u n d o结构中的最大 u n d o项数 */
#define SEMMNU SEMMNS /* 系统中 u n d o结构的最大数 */
#define SEMMAP SEMMNS /* # of entries in semaphore map */
#define SEMUSZ 20 /* sizeof struct sem_undo */
对信号量的操作
1、打开或创建信号量
与消息队列的创建及打开基本相同,不再详述。
2、信号量值操作
linux可以增加或减小信号量的值,相应于对共享资源的释放和占有。具体参见后面的semop系统调用。
3、获得或设置信号量属性
系统中的每一个信号量集都对应一个struct sem_array结构,该结构记录了信号量集的各种信息,存在于系统空间。为了设置、获得该信号量集的各种信息及属性,在用户空间有一个重要的联合结构与之对应,即union semun。

系统中的每个信号量集对应一个sem_array 结构
/* One sem_array data structure for each set of semaphores in the system. */
struct sem_array {
struct kern_ipc_perm sem_perm; /* permissions .. see ipc.h */
time64_t sem_ctime; /* create/last semctl() time */
struct list_head pending_alter; /* pending operations */
/* that alter the array */
struct list_head pending_const; /* pending complex operations */
/* that do not alter semvals */
struct list_head list_id; /* undo requests on this array */
int sem_nsems; /* no. of semaphores in array */
int complex_count; /* pending complex operations */
unsigned int use_global_lock; /* >0: global lock required */
struct sem sems[];
} __randomize_layout;
union semun是系统调用semctl中的重要参数
/* arg for semctl system calls. */
union semun {
int val; /* value for SETVAL */
struct semid_ds __user *buf; /* buffer for IPC_STAT & IPC_SET */
unsigned short __user *array; /* array for GETALL & SETALL */
struct seminfo __user *__buf; /* buffer for IPC_INFO */
void __user *__pad;
};
struct seminfo {
int semmap;
int semmni;
int semmns;
int semmnu;
int semmsl;
int semopm;
int semume;
int semusz;
int semvmx;
int semaem;
};
创建key值 ftok()函数
函数功能:创建key值,使用相同的文件路径及整数(第二个参数),得到的key值是唯一的,唯一的key值创建某类IPC机制时将得到同一个IPC机制。
头文件
#include <sys/types.h>
#include <sys/ipc.h>
函数原型
key_t ftok(const char *pathname, int proj_id);
函数参数
const char *pathname 文件路径名,可以是特殊文件(例如目录文件),也可以是当前目录“.”,通常设置此参数为当前目录,因为当前目录一般都存在,且不会被立即删除
int proj_id 一个int型变量
函数返回
成功返回key值
创建信号量semget()函数
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
函数原型
int semget(key_t key, int nsems, int semflg);
函数参数
key_t key key值,由ftok()获得
int nsems 指定打开或者新创建的信号量集中将包含信号量的数目
int semflg 标志位,可以是:
IPC_CREAT 如果key不存在,则创建,存在,返回ID
IPC_EXCL 如果key存在,返回失 败
IPC_NOWAIT 如果需要等待,直接返回错误
或三者的或结果。
函数返回:若成功则返回信号量集合I D,若出错则为 - 1
注意:如果key所代表的信号量已经存在,且semget指定了IPC_CREAT|IPC_EXCL标志,那么即使参数nsems与原来信号量的数目不等,返回的也是EEXIST错误;如果semget只指定了IPC_CREAT标志,那么参数nsems必须与原来的值一致
控制信号量集合、信号量 semctl()函数
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
函数原型
int semctl(int semid, int semnum, int cmd, union semun arg);//第四个参数不一定有
函数参数
int semid 信号量集合标识符(一般由semget()函数返回)
int semnum 为信号量集合中信号量的编号。第一个信号的编号是0。
semnum值在0和nsems- 1 之间(包括0和nsems-1 )。
注意,第三个参数cmd为SETALL时,此参数无效。
int cmd c m d参数指定下列十种命令中的一种,使其在 s e m i d指定的
信号量集合上执行此命令。其中有五条命令是针对一个特定的
信号量值的,它们用 s e m n u m指定该集合中的一个成员。
s e m n u m值在0和n s e m s- 1 之间(包括0和n s e m s- 1 )。
• IPC_STAT 对此集合取s e m i d _ d s结构,并存放在由 a rg . b u f指向的结构中。
• IPC_SET 按由 a rg . b u f指向的结构中的值设置与此集合相关结构中的下列三个字段值: s e m _ p e r m . u i d , s e m _ p e r m . g i d和s e m _ p e r m . m o d e。此命令只能由下列两种进程执行:一种是其有效用户 I D等于s e m _ p e r m . c u i d或s e m _ p e r m . u i d的进程;另一种是具有超级用户特权的进程。
• IPC_RMID 从系统中删除该信号量集合。这种删除是立即的。仍在使用此信号量的其他进程在它们下次意图对此信号量进行操作时,将出错返回 E I D R M。此命令只能由下列两种进程执行:一种是具有效用户 I D等于s e m _ p e r m . c u i d或s e m _ p e r m . u i d的进程;另一种是具有超级用户特权的进程。
• GETVAL 返回成员 s e m n u m的s e m v a l值。
• SETVAL 设置成员 s e m n u m的s e m v a l值。该值由 a rg . v a l指定。
• GETPID 返回成员 s e m n u m的s e m p i d值。
• GETNCNT 返回成员 s e m n u m的s e m n c n t值。
• GETZCNT 返回成员 s e m n u m的s e m z c n t值。
• GETALL 取该集合中所有信号量的值,并将它们存放在由 a rg . a rr a y指向的数组中。
• SETALL 按a rg . a rr a y指向的数组中的值设置该集合中所有信号量的值。注意,但三个参数为SETALL时,第二个参数semnum无效。
union semun arg 注意,参数是个联合( u n i o n),而非指向一个联合的指针。
/* arg for semctl system calls. */
union semun {
int val; /* value for SETVAL */
struct semid_ds __user *buf; /* buffer for IPC_STAT & IPC_SET */
unsigned short __user *array; /* array for GETALL & SETALL */
struct seminfo __user *__buf; /* buffer for IPC_INFO */
void __user *__pad;
};
函数返回
对于除 G E TA L L以外的所有 G E T命令, s e m c t l函数都返回相应值。其他命令的返回值为 0。
errno=EACCES(权限不够)
EFAULT(arg指向的地址无效)
EIDRM(信号量集已经删除)
EINVAL(信号量集不存在,或者semid无效)
EPERM(EUID没有cmd的权利)
ERANGE(信号量值超出范围)
信号量操作semop()函数
函数功能
函数s e m o p自动执行信号量集合上的操作数组。函数s e m o p自动执行信号量集合上的操作数组。
头文件
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
函数原型
int semop(int semid, struct sembuf *sops, unsigned nsops);
函数参数
int semid 信号量集合标识符
struct sembuf *sops 是一个指针,它指向一个信号量操作数组:
/* semop system calls takes an array of these. */
//操作信号量时使用的结构体
struct sembuf {
unsigned short sem_num; /* semaphore index in array */
short sem_op; /* semaphore operation */
short sem_flg; /* operation flags */
};
1、对集合中每个成员的操作由相应的sem_op规定。此值可以是负值、 0或正值,对应了三种操作。信号量的当前值记录相应资源目前可用数目;sem_op>0对应相应进程要释放sem_op数目的共享资源;sem_op=0可以用于对共享资源是否已用完的测试,表示希望等待到该信号量值变成 0。;sem_op<0相当于进程要申请-sem_op个共享资源。再联想操作的原子性,更不难理解该系统调用何时正常返回,何时睡眠等待。
2、sem_num对应信号集中的信号量,0对应第一个信号量。
3、sem_flg可取IPC_NOWAIT以及SEM_UNDO两个标志。如果设置了SEM_UNDO标志,那么在进程结束时,相应的操作将被取消,这是比较重要的一个标志位。如果设置了该标志位,那么在进程没有释放共享资源就退出时,内核将代为释放。如果为一个信号量设置了该标志,内核都要分配一个sem_undo结构来记录它,为的是确保以后资源能够安全释放。事实上,如果进程退出了,那么它所占用就释放了,但信号量值却没有改变,此时,信号量值反映的已经不是资源占有的实际情况,在这种情况下,问题的解决就靠内核来完成。这有点像僵尸进程,进程虽然退出了,资源也都释放了,但内核进程表中仍然有它的记录,此时就需要父进程调用waitpid来解决问题了。
unsigned nsops 指出将要进行操作的信号的个数
函数返回:若成功则为 0 ,若出错则为 – 1
注意:
这里需要强调的是semop同时操作多个信号量,在实际应用中,对应多种资源的申请或释放。semop保证操作的原子性,这一点尤为重要。尤其对于多种资源的申请来说,要么一次性获得所有资源,要么放弃申请,要么在不占有任何资源情况下继续等待,这样,一方面避免了资源的浪费;另一方面,避免了进程之间由于申请共享资源造成死锁。
例程:生产者—消费者
生产者端为productor.c

消费者端为customer.c

先执行productor.c,再执行customer.c
共享内存
共享内存IPC原理
共享存储允许两个或多个进程共享一给定的存储区。因为数据不需要在客户机和服务器之
间复制,所以这是最快的一种 I P C(只需要复制两次,而管道需要复制四次)。使用共享存储的唯一窍门是多个进程之间对一给定存储区
的同步存取。若服务器将数据放入共享存储区,则在服务器做完这一操作之前,客户机不应当
去取这些数据。通常,信号量被用来实现对共享存储存取的同步。(记录锁也可用于这种场合)
进程间需要共享的数据被放在一个叫做IPC共享内存区域的地方,所有需要访问该共享区域的进程都要把该共享区域映射到本进程的地址空间中去。系统V共享内存通过shmget获得或创建一个IPC共享内存区域,并返回相应的标识符。内核在保证shmget获得或创建一个共享内存区,初始化该共享内存区相应的shmid_kernel结构体同时,还将在特殊文件系统shm中,创建并打开一个同名文件,并在内存中建立起该文件的相应dentry及inode结构,新打开的文件不属于任何一个进程(任何进程都可以访问该共享内存区)。所有这一切都是系统调用shmget完成的。
注意:当一个进程分支出父进程和子进程时,父进程先前创建的所有共享内存区段都会被子进程继承。
由于共享内存需要占用大量的内存空间,系统对共享内存做了以下限制:
/*
* SHMMNI, SHMMAX and SHMALL are default upper limits which can be
* modified by sysctl. The SHMMAX and SHMALL values have been chosen to
* be as large possible without facilitating scenarios where userspace
* causes overflows when adjusting the limits via operations of the form
* "retrieve current limit; add X; update limit". It is therefore not
* advised to make SHMMAX and SHMALL any larger. These limits are
* suitable for both 32 and 64-bit systems.
*/
#define SHMMIN 1 /* min shared seg size (bytes)最小共享段大小 */
#define SHMMNI 4096 /* max num of segs system wide 系统中共享存储段的最大段数*/
#define SHMMAX (ULONG_MAX - (1UL << 24)) /* max shared seg size (bytes)最大共享段大小 */
#define SHMALL (ULONG_MAX - (1UL << 24)) /* max shm system wide (pages) */
#define SHMSEG SHMMNI /* max shared segs per process每个进程,共享存储段的最大段数 */
对于每一个共享内存,内核会为其定义一个shmid_ds结构体类型。
/* Obsolete, used only for backwards compatibility and libc5 compiles */
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
每一个共享内存区都有一个控制结构struct shmid_kernel,shmid_kernel是共享内存区域中非常重要的一个数据结构,它是存储管理和文件系统结合起来的桥梁
每个共享内存区对象都对应特殊文件系统shm中的一个文件,一般情况下,特殊文件系统shm中的文件是不能用read()、write()等方法访问的,当采取共享内存的方式把其中的文件映射到进程地址空间后,可直接采用访问内存的方式对其访问。
struct shmid_kernel /* private to the kernel */
{
struct kern_ipc_perm shm_perm;
struct file *shm_file; //存储了将被映射文件的地址。
unsigned long shm_nattch;
unsigned long shm_segsz;
time64_t shm_atim;
time64_t shm_dtim;
time64_t shm_ctim;
pid_t shm_cprid;
pid_t shm_lprid;
struct user_struct *mlock_user;
/* The task created the shm object. NULL if the task is dead. */
struct task_struct *shm_creator;
struct list_head shm_clist; /* list by creator */
} __randomize_layout;
共享内存相关数据结构的联系

和消息队列和信号量一样,共享内存是随内核持续的。内核通过数据结构struct ipc_ids shm_ids维护系统中的所有共享内存区域。上图中的shm_ids.entries变量指向一个ipc_id结构数组,而每个ipc_id结构数组中有个指向kern_ipc_perm结构的指针。对于系统V共享内存区来说,kern_ipc_perm的宿主是shmid_kernel结构,shmid_kernel是用来描述一个共享内存区域的,这样内核就能够控制系统中所有的共享区域。同时,在shmid_kernel结构的file类型指针shm_file指向文件系统shm中相应的文件,这样,共享内存区域就与shm文件系统中的文件对应起来。
在创建了一个共享内存区域后,还要将它映射到进程地址空间,系统调用shmat()完成此项功能。由于在调用shmget()时,已经创建了文件系统shm中的一个同名文件与共享内存区域相对应,因此,调用shmat()的过程相当于映射文件系统shm中的同名文件过程
注意,共享存储段紧靠在栈之下。实际上,在共享存储段和栈之间有大约 8 M字节的未用地址空间。

创建共享内存shmget()函数
函数功能
获得一个共享存储标识符,如果不存在指定的共享区域就创建相应的区域。创建一个新段时,初始化shmid_ds结构的某些成员。
头文件
#include <sys/ipc.h>
#include <sys/shm.h>
函数原型
int shmget(key_t key, size_t size, int shmflg);
函数参数
key_t key key值,由ftok()获得
size_t size 参数size以字节为单位制定共享内存区域的长度。
int shmflg 用来设置shmget函数的操作类型,也可以用来设置共享内存
的访问权限。两者可以通过逻辑或(“|”)来连接。
函数返回
若成功则为共享内存 I D,若出错则为 – 1
映射共享内存对象shmat()函数
函数功能
shmat()把共享内存区域映射到调用进程的地址空间中去,这样,进程就可以方便地对共享区域进行访问操作。
头文件
#include <sys/types.h>
#include <sys/shm.h>
函数原型
void *shmat(int shmid, const void *shmaddr, int shmflg);
函数参数
int shmid 共享内存标识符
const void *shmaddr 共享存储段连接到调用进程的哪个地址上与addr参数
以及在flag中是否指定SHM_RND位有关。
(1) 如果a d d r为0,则此段连接到由内核选择的第一个可用地址上。
(2) 如果a d d r非0,并且没有指定 S H M _ R N D,则此段连接到 a d d r所指定的地址上。
(3) 如果a d d r非0,并且指定了 S H M _ R N D,则此段连接到( a d d r- (a d d r mod SHMLBA))所表示的地址上。 S H M _ R N D命令的意思是:取整。 S H M L B A的意思是:低边界地址倍数,它总是2的乘方。该算式是将地址向下取最近 1个S H M L B A的倍数。
除非只计划在一种硬件上运行应用程序(这在当今是不大可能的),否则不用指定共享段所连接到的地址。所以一般应指定 a d d r为0,以便由内核选择地址。
int shmflg 如果在f l a g中指定了S H M _ R D O N LY位,
则以只读方式连接此段。否则以读写方式连接此段。
函数返回
若成功则为指向共享存储段的指针,若出错则为 – 1
共享内存控制shmctl()函数
函数功能
shmctl实现对共享内存区域的控制操作。
头文件
#include <sys/ipc.h>
#include <sys/shm.h>
函数原型
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
函数参数
int shmid 共享内存标识符
int cmd cmd参数指定下列 5种命令中一种,使其在shmid指定的段上执行。
• IPC_STAT 对此段取s h m i d _ d s结构,并存放在由 b u f指向的结构中。
• IPC_SET 按 b u f指向的结构中的值设置与此段相关结构中的下列三个字段: s h m _ p e r m . u i d、 s h m _ p e r m . g i d以及s h m _ p e r m . m o d e。此命令只能由下列两种进程执行:一种是其有效用户 I D等于s h m _ p e r m . c u i d或s h m _ p e r m . u i d的进程;另一种是具有超级用户特权的进程。
• IPC_RMID 从系统中删除该共享存储段。因为每个共享存储段有一个连接计数( s h m _ n a t t c h在s h m i d _ d s结构中) ,所以除非使用该段的最后一个进程终止或与该段脱接,否则不会实际上删除该存储段。不管此段是否仍在使用,该段标识符立即被删除 , 所以不能再用s h m a t与该段连接。此命令只能由下列两种进程执行 :一种是其有效用户 I D等于s h m _ p e r m . c u i d或s h m _ p e r m . u i d的进程;另一种是具有超级用户特权的进程。
• SHM_LOCK 锁住共享存储段。此命令只能由超级用户执行。
• SHM_UNLOCK 解锁共享存储段。此命令只能由超级用户执行。
struct shmid_ds *buf 用来存储读取的共享内存属性或者需要修改的共享内存属性。
函数返回
若成功则为 0 ,若出错则为 - 1
分离共享内存对象shmdt()函数
函数功能
shmdt()调用用来解除进程对共享内存区域的映射。当对共享存储段的操作已经结束时,则调用 s h m d t脱接该段。注意:这并不从系统中删除其标识符以及其数据结构(只是将指定的共享内存区域与调用进程的地址空间分离)。该标识符仍然存在,直至某个进程(一般是服务器)调用 s h m c t l(带命令I P C _ R M I D)特地删除它。
头文件
#include <sys/types.h>
#include <sys/shm.h>
函数原型
int shmdt(const void *shmaddr);
函数参数
const void *shmaddr a d d r参数是以前调用 s h m a t时的返回值。
函数返回
若成功则为 0 ,若出错则为 – 1
例程

linux线程
线程基本概念
线程概念:在现代操作系统中,进程支持多线程。进程是资源管理的最小单元;线程是程序执行的最小单元。即线程作为调度和分配的基本单位,进程作为资源分配的基本单位一个进程的组成实体可以分为两大部分:线程集和资源集。进程中的线程是动态的对象;代表了进程指令的执行。资源,包括地址空间、打开的文件、用户信息等等,由进程内的线程共享。
线程ID:就像每个进程有一个进程ID一样,每个线程也有一个线程ID。进程ID在整个系统的唯一的,但线程ID不同,线程ID只在它所属的进程环境中有效
多线程的优缺点:支持多线程的程序(进程)可以取得真正的并行(parallelism),且由于共享进程的代码和全局数据,故线程间的通信是方便的。它的缺点也是由于线程共享进程的地址空间,因此可能会导致竞争,因此对某一块有多个线程要访问的数据需要一些同步技术。
在操作系统设计上,从进程演化出线程,最主要的目的就是更好的支持SMP以及减小(进程/线程)上下文切换开销
线程模型–核心级线程和用户级线程
针对线程模型的两大意义,分别开发出了核心级线程和用户级线程两种线程模型,分类的标准主要是线程的调度者在核内还是在核外。前者更利于并发使用多处理器的资源,而后者则更多考虑的是上下文切换开销。
注意:因为pthread并非Linux系统的默认库,而是POSIX线程库。在Linux中将其作为一个库来使用,因此加上 -lpthread(或-pthread)以显式链接该库。
线程基本操作
创建线程 pthread_create()
函数功能
创建一个新的线程,如果线程创建成功,它将拥有自己的线程属性和执行栈,并从调用程序那里继承信号掩码和调试优先级。
线程创建时并不能保证哪个线程会先运行:是新创建的线程还是调用线程。新创建的线程可以访问调用进程的地址空间,但是该线程的未决信号集被清除。
头文件
#include <pthread.h>
函数原型
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
函数参数
pthread_t *thread thread指向的内存被设置为新创建线程的线程ID,
设置为NULL,则不会返回生成的线程的标识符。
类型pthread_t定义为unsigned long int,
打印ID时需要使用%u
const pthread_attr_t *attr 用于设置各种不同的线程属性,
为NULL时表示新的线程将使用系统默认的属性。
void *(*start_routine) (void *) 新创建的线程从start_routine函数的地址
开始运行,该函数只有一个无类型指针的参数arg
void *arg 如果需要向start_routine函数传入的参数不止
一个,可以把参数放入到一个结构中,然后把这个结构的地址作为arg的参数传入。
函数返回
成功返回0,失败返回错误号。
线程终止 pthread_exit()
函数功能
线程终止,线程在结束时最好调用该函数,以确保安全、干净的退出。
新创建的线程从执行用户定义的函数处开始执行,直到出现以下情况时退出:
- 调用pthread_exit函数退出
- 调用pthread_cancel函数取消该线程
- 创建的进程退出或者整个函数结束
- 其中的一个线程执行了exec类函数执行新的进程
头文件
#include <pthread.h>
函数原型
void pthread_exit(void *retval);
函数参数
void *retval 用来保存线程退出状态
函数返回
无返回值
等待线程 pthread_join()
函数功能
阻塞当前的线程,直到另外一个线程运行结束。函数pthread_join用来等待一个线程的结束,线程间同步的操作。该函数会以阻塞的方式等待thread指定的线程结束。当函数返回时,被等待线程的资源被收回。如果线程已经结束,那么该函数会立即返回。并且thread指定的线程必须是joinable的。(类似进程的wait()函数)
pthread_join的应用:代码中如果没有pthread_join主线程会很快结束从而使整个进程结束,从而使创建的线程没有机会开始执行就结束了。加入pthread_join后,主线程会一直等待直到等待的线程结束自己才结束,使创建的线程有机会执行。
需要说明的是,一个线程不能被多个线程等待,也就是说对一个线程只能调用一次pthread_join,否则只有一个能正确返回,其他的将返回ESRCH 错误。
头文件
#include <pthread.h>
函数原型
int pthread_join(pthread_t thread, void **retval);
函数参数
pthread_t thread 线程标识符,此线程必须同调用它的进程相联系,
即创建该线程时不能指明此线程为独立的线程,
默认情况下为关联线程。
void **retval 用户定义的指针,指向用来存储被等待线程的返回值
的一个静态区域。
函数返回
成功返回0,出错返回错误代码
取消线程 pthread_cancel()
函数功能
线程可以通过调用pthread_cancel函数来请求同一进程内的另一个线程取消,发送终止信号给thread线程,发送成功并不意味着thread会终止。thread线程可以选择忽略或控制它如何被取消。(由可取消状态和取消类型决定)
若是在整个程序退出时,要终止各个线程,应该在成功发送 CANCEL 指令后,使用 pthread_join 函数,等待指定的线程已经完全退出以后,再继续执行;否则,很容易产生 “段错误”。
注意pthread_cancel并不等待线程结束,它只是提出请求。
头文件
#include <pthread.h>
函数原型
int pthread_cancel(pthread_t thread);
函数参数
pthread_t thread 线程标识符
函数返回
成功返回0,否则为非0值。
示例
//取消子线程
printf("cancelling thread.\n");
ret = pthread_cancel(thread_id);
if (ret != 0) {
printf("thread cancel failed.\n");
exit(EXIT_FAILURE);
}
例程

设置可取消状态 pthread_setcancelstate()
函数功能
设置可取消状态
头文件
#include <pthread.h>
函数原型
int pthread_setcancelstate(int state, int *oldstate);
函数参数
int state 是调用线程的可取消状态所要设置的值:
PTHREAD_CANCEL_DISABLE
PTHREAD_CANCEL_ENABLE(创建线程时默认)
int *oldstate 是存储调用线程原来的可取消状态的内存地址,
如果不为 NULL则存入原来的Cancel状态以便恢复。
函数返回
成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
设置取消类型 pthread_setcanceltype()
函数功能
pthread_setcanceltype()函数用来设置取消类型,即允许取消的线程在接收到取消操作后是立即中止还是在取消点中止。
执行取消操作时,将调用线程的取消清理处理程序(pthread_cleanup_push())。
头文件
#include <pthread.h>
函数原型
int pthread_setcanceltype(int type, int *oldtype);
函数参数
int type 是调用线程的可取消性类型所要设置的值:
PTHREAD_CANCEL_ASYNCHRONOUS
PTHREAD_CANCEL_DEFERRED(创建线程时默认)
int *oldtype 是存储调用线程原来的可取消性类型的地址
函数返回
成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
设置某个线程为独立线程 pthread_detach()
如果设置某个线程为独立线程,则可以调用pthread_detach()函数,此函数如果执行成功,将使该线程与当前进程分离,使其成为一个独立的线程,并返回0,当该线程终止时,系统将自动回收它的资源;如果执行失败,将返回非零值。
某线程退出时仅回收该线程私有的信息,在该线程中申请的堆空间并不是该线程的私有空间,在同一进程中的其它线程中可以访问。
头文件
#include <pthread.h>
函数原型
int pthread_detach(pthread_t thread);
函数参数
pthread_t thread 线程标识符
比较两个线程ID pthread_equal()
函数功能
比较两个线程标识符。
因为在不同的系统下,pthread_t的类型是不同的,所以不能直接使用==判读,而应该使用pthread_equal来判断。
头文件
#include <pthread.h>
函数原型
int pthread_equal(pthread_t t1, pthread_t t2);
函数参数
两个线程标识符
函数返回
如果相等,返回非零值,如果不相等,返回0。
示例
//比较两个线程ID
if (0 != pthread_equal(thread_id, pthread_self()))
printf("Equal!\n");
else
printf("Not equal!\n");
获取线程ID pthread_self()
函数功能
获取当前调用线程的 thread identifier(标识号).
头文件
#include <pthread.h>
函数原型
pthread_t pthread_self(void);
函数参数
无
函数返回
获得线程自身的ID。pthread_t的类型为unsigned long int,所以在打印的时候要使用%lu方式,否则显示结果出问题。
示例
//返回调用线程的线程ID
thread_id = pthread_self();
printf("Thread ID = %lu \n",thread_id);
线程属性控制
待续…
线程调度策略
待续…
线程间同步机制
互斥锁
概念:以排他的方式,防止共享资源被并发访问;
互斥锁为二元变量, 状态为0-开锁、1-上锁;
开锁必须由上锁的线程执行,不受其它线程干扰。
互斥锁的操作流程如下:
1)在访问共享资源后临界区域前,对互斥锁进行加锁。
2)在访问完成后释放互斥锁导上的锁。
3)对互斥锁进行加锁后,任何其他试图再次对互斥锁加锁的线程将会被阻塞,直到锁被释放。
在使用互斥锁前,需要定义该互斥锁(全局变量):pthread_mutex_t lock;
初始化互斥锁 pthread_mutex_init()
函数原型
int pthread_mutex_init(pthread_mutex_t *mutex,
const pthread_mutexattr_t *attr)
函数参数
pthread_mutex_t *mutex 指向要初始化的互斥锁
const pthread_mutexattr_t *attr 属性,如果为NULL,则使用默认的属性。
函数返回
成功返回0,否则为非0错误值以指明错误
代码示例:
pthread_mutex_t mp;
pthread_mutexattr_t mattr;
int ret;
ret = pthread_mutex_init(&mp, NULL); //使用默认属性
或:ret = pthread_mutex_init(&mp, &mattr); //使用自定义属性
此外,还可以使用宏PTHREAD_MUTEX_INITIALIZER初始化静态分配的互斥锁。对于静态初始化的互斥锁,不需要调用函数pthread_mutex_init()。
代码示例:pthread_mutex_t mp = PTHREAD_MUTEX_INITIALIZER
销毁互斥锁pthread_mutex_destroy()
函数原型:int pthread_mutex_destroy(pthread_mutex_t *mutex)
函数返回:成功返回0,否则为非0错误值以指明错误
释放互斥锁pthread_mutex_unlock()
函数原型:int pthread_mutex_unlock(pthread_mutex_t *mutex)
函数返回:成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
注意:释放操作只能有占有该互斥锁的线程完成。
阻塞 和 非阻塞申请互斥锁
pthread_mutex_lock() 和 pthread_mutex_trylock()
函数原型: int pthread_mutex_lock(pthread_mutex_t *mutex) //阻塞
int pthread_mutex_trylock(pthread_mutex_t *mutex) //非阻塞
函数返回:成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
例程

条件变量
在使用条件变量前,需要定义该条件变量(全局变量):pthread_cond_t condtion;
注意:条件变量不能单独使用,必须配合互斥锁一起实现对资源的互斥访问。
初始化、销毁条件变量
pthread_cond_init() 和pthread_cond_destroy()
函数原型: int pthread_cond_init(pthread_cond_t *cond,
const pthread_condattr_t *attr) //初始化
int pthread_cond_destroy(pthread_cond_t *cond) //销毁
函数参数
pthread_cond_t *cond 条件变量
const pthread_condattr_t *attr 属性,如果为NULL,则使用默认属性
来初始化条件变量
函数返回:成功返回0,否则为非0错误值以指明错误
代码示例:
pthread_cond_t cv;
pthread_condattr_t cattr;
int ret;
ret = pthread_cond_init(&cv, NULL); //使用默认属性
或:ret = pthread_cond_init(&cv, &dattr); //使用自定义属性
等待条件变量(两种)
pthread_cond_wait()和pthread_cond_timewait()
函数功能:用来阻塞等待某个条件变量。
函数原型:int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex)
函数参数
pthread_cond_t *cond 要等待的条件变量
pthread_mutex_t *mutex 指向与条件变量cond关联的互斥锁
函数功能:用来在指定的时间范围内等待条件变量。
函数原型:int pthread_cond_timewait(pthread_cond_t *cond,
pthread_mutex_t *mutex,
const struct timespec *time)
函数参数
pthread_cond_t *cond 要等待的条件变量
pthread_mutex_t *mutex 指向与条件变量cond关联的互斥锁
const struct timespec *time 等待过期时的绝对时间,从1970-1-1:0:0:0起,
如果在此时间范围内求取到该条件变量函数将返回。
数据结构为:
struct timespec {
long ts_sec;
long ts_nsec
}
函数返回:成功返回0,否则为非0错误值以指明错误
注意:以上两个函数都包含一个互斥锁,如果某线程因等待条件变量进入等待状态时,将隐含释放其申请的互斥锁。同样,在返回时,首先要申请到该互斥锁对象。
通知等待条件变量的线程(两种)
pthread_cond_signal()和pthread_cond_broadcast()
函数功能
pthread_cond_signal()用来通知等待条件变量的第一个线程。pthread_cond_broadcast()用来通知等待条件变量的所有线程。
函数原型
int pthread_cond_signal(pthread_cond_t *cond) //单一通知
int pthread_cond_broadcast(pthread_cond_t *cond) //广播通知
函数参数
pthread_cond_t *cond 条件变量
函数返回:成功返回0,否则为非0错误值以指明错误
读写锁
当有一个线程已经持有互斥锁时,互斥锁将所有试图进入临界区的线程都阻塞住。但是考虑一种情形,当前持有互斥锁的线程只是要读访问共享资源,而同时有其它几个线程也想读取这个共享资源,但是由于互斥锁的排它性,所有其它线程都无法获取锁,也就无法读访问共享资源了,但是实际上多个线程同时读访问共享资源并不会导致问题。
在对数据的读写操作中,更多的是读操作,写操作较少,例如对数据库数据的读写应用。为了满足当前能够允许多个读出,但只允许一个写入的需求,线程提供了读写锁来实现。
读写锁的特点如下:
1、如果有其它线程读数据,则允许其它线程执行读操作,但不允许写操作。
2、如果有其它线程写数据,则其它线程都不允许读、写操作。
读写锁分为读锁和写锁,规则如下:
1、如果某线程申请了读锁,其它线程可以再申请读锁,但不能申请写锁。
2、如果某线程申请了写锁,其它线程不能申请读锁,也不能申请写锁。
定义读写锁对象:pthread_rwlock_t rwlock;
初始化、销毁读写锁
pthread_rwlock_init() 和pthread_ rwlock_destroy()
函数原型: int pthread_rwlock_init(pthread_rwlock_t *rwlock,
const pthread_rwlockattr_t *attr) //初始化
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock) //销毁
函数参数
pthread_rwlock_t *rwlock 读写锁
const pthread_rwlockattr_t *attr 属性,如果为NULL,则使用默认属性
来初始化读写锁
函数返回:成功返回0,否则为非0错误值以指明错误
申请读锁(两种)
pthread_rwlock_rdlock ()和pthread_rwlock_tryrdlock ()
函数功能:分别以阻塞和非阻塞的方式来申请读锁
函数原型: int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock) //阻塞
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock) //非阻塞
函数参数
pthread_rwlock_t *rwlock 读写锁
函数返回:成功返回0,否则为非0错误值以指明错误
申请写锁(两种)
pthread_rwlock_wrlock ()和pthread_rwlock_trywrlock ()
函数功能
分别以阻塞和非阻塞的方式来申请写锁
函数原型
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock) //阻塞
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock) //非阻塞
函数参数
pthread_rwlock_t *rwlock 读写锁
函数返回:成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
释放读写锁(无论是读锁还是写锁)pthread_rwlock_unlock ()
函数原型:int pthread_rwlock_unlock(pthread_rwlock_t *rwlock)
函数返回:成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
注意:
- 如果调用此函数来释放读写锁rwlock上的读锁,但当前在此读写锁上还保持着其他读锁,则读写锁将保持线程读锁状态,只不过当前线程已不再是其所有者之一。
- 如果此函数释放读写锁的最后一个读锁,则对象将处于没有所有者的解锁状态。
- 如果此函数释放读写锁的最后一个写锁,则对象将处于没有所有者的解锁状态。
例程

信号量
信号量概述
信号量广泛用于进程或线程间的同步和互斥,信号量本质上是一个非负的整数计数器,它被用来控制对公共资源的访问。
编程时可根据操作信号量值的结果判断是否对公共资源具有访问的权限,当信号量值大于 0 时,则可以访问,否则将阻塞。PV 原语是对信号量的操作,一次 P 操作使信号量减1,一次 V 操作使信号量加1。
信号量主要用于进程或线程间的同步和互斥这两种典型情况。
信号量用于互斥:
信号量用于同步:
在 POSIX 标准中,信号量分两种,一种是无名信号量,一种是有名信号量。无名信号量一般用于线程间同步或互斥,而有名信号量一般用于进程间同步或互斥。它们的区别和管道及命名管道的区别类似,无名信号量则直接保存在内存中,而有名信号量要求创建一个文件。
信号量与互斥锁的区别在于:
互斥锁:只有一个bool类型的值,只允许2个线程进行排队;
信号量:允许多个线程共同等待一个共享资源
头文件:#include <semaphore.h>
初始化信号量
函数原型:int sem_init(sem_t *sem, int pshared, unsigned int value);
功能:创建一个信号量并初始化它的值。一个无名信号量在被使用前必须先初始化。
参数:
sem:信号量的地址。
pshared:等于 0,信号量在线程间共享(常用);不等于0,信号量在进程间共享。
value:信号量的初始值。
返回值:成功:0,失败:-1
信号量 P 操作(减 1)
函数原型:int sem_wait(sem_t *sem);
功能:将信号量的值减 1。操作前,先检查信号量(sem)的值是否为 0,若信号量为 0,此函数会阻塞,直到信号量大于 0 时才进行减 1 操作。
参数:
sem:信号量的地址。
返回值:成功:0,失败:-1
函数原型:int sem_trywait(sem_t *sem);
功能:以非阻塞的方式来对信号量进行减 1 操作。若操作前,信号量的值等于 0,则对信号量的操作失败,函数立即返回。
信号量 V 操作(加 1)
函数原型:int sem_post(sem_t *sem);
功能:将信号量的值加 1 并发出信号唤醒等待线程(sem_wait())。
参数:
sem:信号量的地址。
返回值:成功:0,失败:-1
获取信号量的值
函数原型:int sem_getvalue(sem_t *sem, int *sval);
功能:获取 sem 标识的信号量的值,保存在 sval 中。
参数:
sem:信号量地址。
sval:保存信号量值的地址。
返回值:成功:0,失败:-1
销毁信号量
函数原型:int sem_destroy(sem_t *sem);
功能:删除 sem 标识的信号量。
参数:
sem:信号量地址。
返回值:成功:0,失败:-1
例程
信号量用于互斥:

信号量用于同步:

线程间异步机制
信号
线程拥有与信号相关的私有数据——线程信号掩码,这就决定了线程在信号操作时具有以下特性:
- 每个线程可以向别的线程发送信号。pthread_kill()函数用来完成这一操作。
- 每个线程可以设置自己的信号阻塞集合。pthread_sigmask()函数用来完成这一操作,其类似于进程的sigpromask()函数。
- 每个线程可以设置针对某信号的处理方式,但同一进程中对某信号的处理方式只能有一个有效,即最后一次设置的处理方式。
- 如果别的进程向当前进程中发送一个信号,那么由哪个线程处理则是未知的。
发送信号 pthread_kill()
函数功能
用来在线程间发送信号
头文件
#include <signal.h>
函数原型
int pthread_kill(pthread_t thread, int sig);
函数参数
pthread_t thread 要向其发送信号的线程
int sig 信号
函数返回:成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
调用线程的信号掩码 pthread_sigmask()
函数功能
用来检查(或更改)调用线程的信号掩码。
头文件
#include <signal.h>
函数原型
int pthread_sigmask(int how, const sigset_t *set, sigset_t *oldset);
函数参数
int how 用来定义如何更改调用线程的信号掩码。包括:
SIG_BLOCK:增加一个信号集合到当前进程的阻塞集合之中。
SIG_UNBLOCK:从当前的阻塞集合之中删除一个信号集合。
SIG_SETMASK:将当前的信号集合设置为信号阻塞集合。
const sigset_t *set 如果是空指针,则参数how的值没有意义,
且不会更改线程的阻塞信号集,因此该调用
可用于查询当前受阻塞的信号。
sigset_t *oldset 原信号屏蔽集
函数返回:成功返回0,否则为非0错误值以指明错误(不设置errno变量)。
注意:不可能阻塞SIGKILL或SIGSTOP信号,这是系统强制执行的,而不会导致错误。
linux网络编程
TCP/IP协议簇基础
为了减少协议设计的复杂性,大多数网络模型均采用分层的方式来组织。每一层都有自己的功能,就像建筑物一样,每一层都靠下一层支持。每一层利用下一层提供的服务来为上一层提供服务,本层服务的实现细节对上层屏蔽。
模型
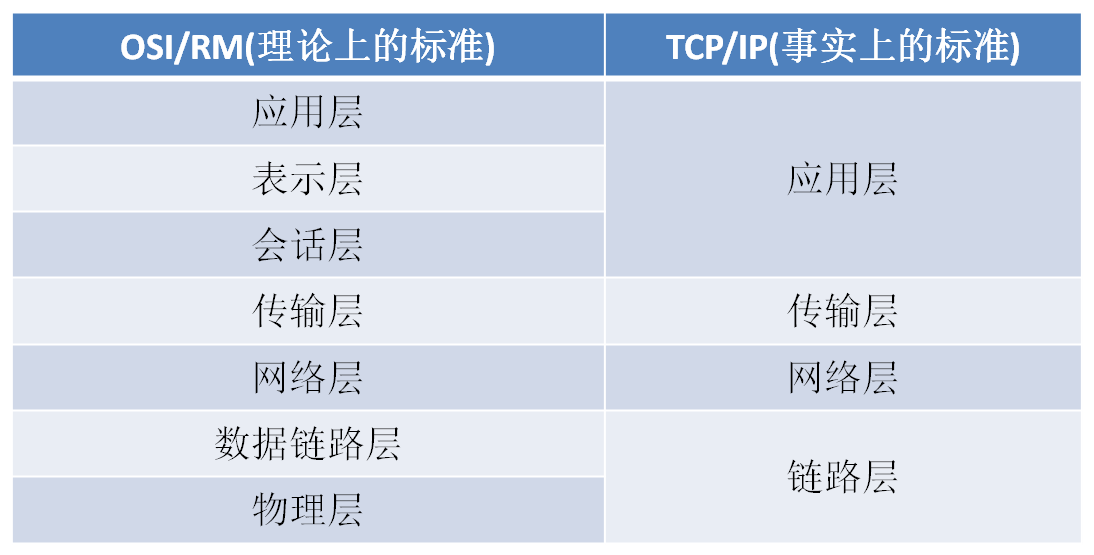
层与协议
每一层都是为了完成一种功能。为了实现这些功能,就需要大家都遵守共同的规则。大家都遵守这规则,就叫做“协议”(protocol)。
网络的每一层,都定义了很多协议。这些协议的总称,叫“TCP/IP协议”。它是Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。这里需要注意,TCP/IP协议是一个大家族,不仅仅只有TCP和IP协议,它还包括其它的协议
TCP/IP协议族的每一层的作用
·网络接口层(链路层):负责将二进制流转换为数据帧,并进行数据帧的发送和接收。要注意的是数据帧是独立的网络信息传输单元。
·网络层:负责将数据帧封装成IP数据报,并运行必要的路由算法。有四种互联协议:
IP:(网际互联协议)负责在主机和网络之间寻址和路由数据包。
ARP:(地址转换协议)用于获得同一物理网络中的硬件主机地址。
ICMP:(网络控制消息协议)用于发送报告有关数据包的传送错误的协议。
IGMP:(网络组管理协议)被IP主机用来向本地多路广播路由器报告主机组成员的协议。
·传输层:负责端对端之间的通信会话连接和建立。传输协议的选择根据数据传输方式而定。主要有以下两种传输协议:
TCP:(传输控制协议)为应用程序提供可靠的通信连接。适合于一次传输大批数据的情况。并适用于要求得到相应的应用程序。
UDP:(用户数据包协议)提供了无连接通信,且不对传送包进行可靠的保证。适合于一次传输少量数据,可靠性则由应用层来确定。
·应用层:负责应用程序的网络访问,这里通过端口号来识别各个不同的进程。
TELNET:提供远程登录(终端仿真)服务。
FTP:提供应用级的文件传输服务。
SMTP:电子邮件协议
DNS:域名解析服务,也就是将域名映像成IP地址的协议,使用传输层UDP。
HTTP:超文本传输协议,访问Web所采用的协议。

注意:
在网络接口层,最重要的信息之一是主机的MAC地址,为48bit,在物理上唯一的标识某台主机; IP层的IP地址在逻辑上唯一的标识某台主机;在主机内部,传输层的端口对应唯一的应用服务。
数据包封包流程

数据包接收拆包分类流程

网络接口层
以太网协议
以太网规定,一组电信号构成一个数据包,叫做“帧”(Frame)。每一帧分成两个部分:包头(Head)和数据(Data)。

“包头”包含数据包的一些说明项,比如发送者、接受者、数据类型等等;"数据"则是数据包的具体内容。
“包头”的长度,固定为 18 字节。"数据"的长度,最短为 46 字节,最长为 1500 字节。因此,整个"帧"最短为 64 字节,最长为 1518 字节。如果数据很长,就必须分割成多个帧进行发送。
MAC地址
以太网数据包的“包头”,包含了发送者和接受者的信息。那么,发送者和接受者是如何标识呢?
以太网规定,连入网络的所有设备,都必须具有“网卡”接口。数据包必须是从一块网卡,传送到另一块网卡。通过网卡能够使不同的计算机之间连接,从而完成数据通信等功能。网卡的地址,就是数据包的发送地址和接收地址,这叫做 MAC 地址。
MAC地址,用于标识网络设备,类似于身份证号。每块网卡出厂的时候,都有一个全世界独一无二的 MAC 地址(理论上全球唯一),长度是 48 个二进制位,通常用 12 个十六进制数表示。
有了 MAC 地址,就可以定位网卡和数据包的路径了。
广播
首先是定义地址,那一块网卡怎么会知道另一块网卡的 MAC 地址?有一种 ARP 协议,可以解决这个问题。需要注意的是:以太网数据包必须知道接收方的 MAC 地址,然后才能发送。
其次,就算有了 MAC 地址,系统怎样才能把数据包准确送到接收方?以太网采用了一种很“原始”的方式,它不是把数据包准确送到接收方,而是向本网络内所有计算机发送,让每台计算机自己判断,是否为接收方。

上图中,1号计算机向 2 号计算机发送一个数据包,同一个子网络的 3 号、4号、5号计算机都会收到这个包。它们读取这个包的“包头”,找到接收方的 MAC 地址,然后与自身的 MAC 地址相比较,如果两者相同,就接受这个包,做进一步处理,否则就丢弃这个包。这种发送方式就叫做“广播”(broadcasting)。
有了数据包的定义、网卡的 MAC 地址、广播的发送方式,“链接层”就可以在多台计算机之间传送数据
网络层
网络层的由来
以太网协议,依靠 MAC 地址发送数据。理论上,单单依靠 MAC 地址,北京的网卡就可以找到深圳的网卡了,技术上是可以实现的。
但是,这样做有一个重大的缺点。以太网采用广播方式发送数据包,所有成员人手一“包”,不仅效率低,而且局限在发送者所在的子网络。也就是说,如果两台计算机不在同一个子网络,广播是传不过去的。否则互联网上每一台计算机都会收到所有包,那会引起灾难(广播风暴)。
互联网是无数子网络共同组成的一个巨型网络。因此,必须找到一种方法,能够区分哪些 MAC 地址属于同一个子网络,哪些不是。如果是同一个子网络,就采用广播方式发送,否则就采用“路由”方式发送。(“路由”就相当于现象生活中的路标,规定这些数据包的走向,就是指如何向不同的子网络分发数据包。)遗憾的是,MAC 地址本身无法做到这一点。它只与厂商有关,与所处网络无关。
这就导致了“网络层”的诞生。它的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做“网络地址”,简称“网址”。
于是,“网络层”出现以后,每台计算机有了两种地址,一种是 MAC 地址,另一种是网络地址。两种地址之间没有任何联系,MAC 地址是绑定在网卡上的,网络地址则是管理员分配的,它们只是随机组合在一起。
网络地址帮助我们确定计算机所在的子网络,MAC 地址则将数据包送到该子网络中的目标网卡。因此,从逻辑上可以推断,必定是先处理网络地址,然后再处理 MAC 地址。
IP 协议
规定网络地址的协议,叫做 IP 协议。它所定义的地址,就被称为 IP 地址。
目前,广泛采用的是 IP 协议第四版(IPV4),简称 IPv4。这个版本规定,网络地址由 32 个二进制位组成。
习惯上,我们用分成四段的十进制数表示 IP 地址,从0.0.0.0一直到 255.255.255.255。
互联网上的每一台计算机,都会分配到一个 IP 地址。这个地址分成两个部分,前一部分代表网络,后一部分代表主机。
实际上,为了适应不同大小的 网络,Internet定义了5中IP地址类型,分为A、B、C、D、E。
比如,一个C类IP 地址 172.16.254.1,这是一个 32 位的地址,假定它的网络部分是前 24 位(172.16.254),那么主机部分就是后 8 位(最后的那个1)。处于同一个子网络的电脑,它们 IP 地址的网络部分必定是相同的,也就是说 172.16.254.2 应该与 172.16.254.1 处在同一个子网络。
但是,问题在于单单从 IP 地址,我们无法判断网络部分。还是以 172.16.254.1 为例,它的网络部分,到底是前 24 位,还是前 16 位,甚至前 28 位,从 IP 地址上是看不出来的。
那么,怎样才能从 IP 地址,判断两台计算机是否属于同一个子网络呢?这就要用到另一个参数“子网掩码”(subnet mask)。
所谓“子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于 IP 地址,也是一个 32 位二进制数字,它的网络部分全部为1,主机部分全部为0,并且1和0分别连续。
比如,IP 地址 172.16.254.1,如果已知网络部分是前 24 位,主机部分是后 8 位,那么子网络掩码就是 11111111.11111111.11111111.00000000,写成十进制就是 255.255.255.0。
我们可以通过“子网掩码”来区分哪部分是子网 ID,哪部分为主机 ID。IP 地址和子网掩码中 1 相与“&”即可得到子网 ID,IP 地址和子网掩码中 0 相或 “|”,即可得到主机 ID。
所以,知道“子网掩码”,我们就能判断,任意两个 IP 地址是否处在同一个子网络。方法是将两个 IP 地址与子网掩码分别进行 AND 运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知 IP 地址 172.16.254.1 和 172.16.254.233 的子网掩码都是 255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行 AND 运算,结果都是 172.16.254.0,因此它们在同一个子网络。
总结一下,IP 协议的作用主要有两个,一个是为每一台计算机分配 IP 地址,另一个是确定哪些地址在同一个子网络。
IP 数据包
根据 IP 协议发送的数据,就叫做 IP 数据包。不难想象,其中必定包括 IP 地址信息。
但是前面说过,以太网数据包只包含 MAC 地址,并没有 IP 地址的栏位。那么是否需要修改数据定义,再添加一个栏位呢?不需要,我们可以把 IP 数据包直接放进以太网数据包的“数据”部分,因此完全不用修改以太网的规格。这就是互联网分层结构的好处:上层的变动完全不涉及下层的结构。
具体来说,IP 数据包也分为“包头”和“数据”两个部分。

“包头”部分主要包括版本、长度、IP 地址等信息,“数据”部分则是 IP 数据包的具体内容。它放进以太网数据包后,以太网数据包就变成了下面这样。

IP 数据包的“包头”部分的长度为 20 到 60 字节,整个数据包的总长度最大为 65,535字节。因此,理论上,一个 IP 数据包的“数据”部分,最长为 65,515字节。前面说过,以太网数据包的“数据”部分,最长只有 1500 字节。因此,如果 IP 数据包超过了 1500 字节,它就需要分割成几个以太网数据包,分开发送了。
ARP 协议
因为 IP 数据包是放在以太网数据包里发送的,所以我们必须同时知道两个地址,一个是对方的 MAC 地址,另一个是对方的 IP 地址。通常情况下,对方的 IP 地址是已知的(后文会解释),但是我们不知道它的 MAC 地址。
所以,我们需要一种机制,能够从 IP 地址得到 MAC 地址。
这里又可以分成两种情况:
第一种情况,如果两台主机不在同一个子网络,那么事实上没有办法得到对方的 MAC 地址,只能把数据包传送到两个子网络连接处的“网关”(gateway),让网关去处理。
第二种情况,如果两台主机在同一个子网络,那么我们可以用 ARP 协议,得到对方的 MAC 地址。ARP 协议也是发出一个数据包(包含在以太网数据包中),其中包含它所要查询主机的 IP 地址,在对方的 MAC 地址这一栏,填的是 FF:FF:FF:FF:FF:FF,表示这是一个“广播”地址。它所在子网络的每一台主机,都会收到这个数据包,从中取出 IP 地址,与自身的 IP 地址进行比较。如果两者相同,都做出回复,向对方报告自己的 MAC 地址,否则就丢弃这个包。
总之,有了 ARP 协议之后,我们就可以得到同一个子网络内的主机 MAC 地址,可以把数据包发送到任意一台主机之上
传输层
传输层的由来
有了 MAC 地址和 IP 地址,我们已经可以在互联网上任意两台主机上建立通信。
但问题是,同一台主机上有许多程序都需要用到网络,比如,你一边浏览网页,一边与朋友在线聊天。当一个数据包从互联网上发来的时候,你怎么知道,它是表示网页的内容,还是表示在线聊天的内容?
也就是说,我们还需要一个参数,表示这个数据包到底供哪个程序(进程)使用。这个参数就叫做“端口”(port),它其实是每一个使用网卡的程序的编号。每个数据包都发到主机的特定端口,所以不同的程序就能取到自己所需要的数据。
“端口”是 0 到 65535 之间的一个整数,正好 16 个二进制位。0到 1023 的端口被系统占用,用户只能选用大于 1023 的端口。不管是浏览网页还是在线聊天,应用程序会随机选用一个端口,然后与服务器的相应端口联系。
“传输层”的功能,就是建立“端口到端口”的通信。相比之下,“网络层”的功能是建立“主机到主机”的通信。只要确定主机和端口,我们就能实现程序之间的交流。因此,Unix 系统就把主机+端口,叫做“套接字”(socket)。有了它,就可以进行网络应用程序开发了。
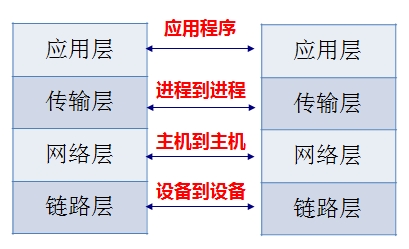
UDP 协议
现在,我们必须在数据包中加入端口信息,这就需要新的协议。最简单的实现叫做 UDP 协议,它的格式几乎就是在数据前面,加上端口号。
UDP 数据包,也是由“包头”和“数据”两部分组成。

“包头”部分主要定义了发出端口和接收端口,“数据”部分就是具体的内容。然后,把整个 UDP 数据包放入 IP 数据包的“数据”部分,而前面说过,IP 数据包又是放在以太网数据包之中的,所以整个以太网数据包现在变成了下面这样:

UDP 数据包非常简单,“包头”部分一共只有 8 个字节,总长度不超过 65,535字节,正好放进一个 IP 数据包。
TCP 协议
UDP 协议的优点是比较简单,容易实现,但是缺点是可靠性较差,一旦数据包发出,无法知道对方是否收到。
为了解决这个问题,提高网络可靠性,TCP 协议就诞生了。这个协议非常复杂,但可以近似认为,它就是有确认机制的 UDP 协议,每发出一个数据包都要求确认。如果有一个数据包遗失,就收不到确认,发出方就知道有必要重发这个数据包了。
因此,TCP 协议能够确保数据不会遗失。它的缺点是过程复杂、实现困难、消耗较多的资源。
TCP 数据包和 UDP 数据包一样,都是内嵌在 IP 数据包的“数据”部分。TCP 数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常 TCP 数据包的长度不会超过 IP 数据包的长度,以确保单个 TCP 数据包不必再分割。
应用层
应用程序收到“传输层”的数据,接下来就要进行解读。由于互联网是开放架构,数据来源五花八门,必须事先规定好格式,否则根本无法解读。
“应用层”的作用,就是规定应用程序的数据格式。
举例来说,TCP 协议可以为各种各样的程序传递数据,比如 Email、WWW、FTP 等等。那么,必须有不同协议规定电子邮件、网页、FTP 数据的格式,这些应用程序协议就构成了“应用层”。
这是最高的一层,直接面对用户。它的数据就放在 TCP 数据包的“数据”部分。因此,现在的以太网的数据包就变成下面这样。
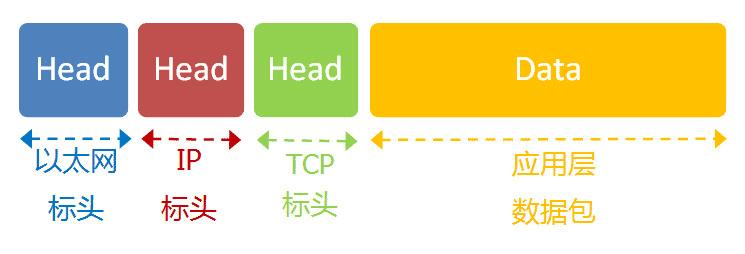
Socket网络通信编程
Socket是一种实现网络不同主机进程间通信的一种机制。根据是否面向连接,可以将socket通信分为面向连接的数据流通信和面向无连接的数据报通信。两者在实现上有类似的地方,即都需要创建相应的socket对象。但是两者的区别在于,面向连接的TCP通信需要双方建立可行的数据连接后才能通信,而面向无连接的UDP通信则只是简单的将数据发送到对应的目的主机即可。
套接字
源IP地址和目的IP地址以及源端口号和目的端口号的组合称为套接字。其用于标识客户端请求的服务器和服务。
它是网络通信过程中端点的抽象表示,包含进行网络通信必需的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
或者说,套接字,是支持TCP/IP的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
非常非常简单的举例说明下:Socket=Ip address+ TCP/UDP + port。(域(domain),类型(type),和协议(protocol))
区分不同应用程序进程间的网络通信和连接,主要有3个参数:通信的目的IP地址、使用的传输层协议(TCP或UDP)和使用的端口号。Socket原意是 “插座”。通过将这3个参数结合起来,与一个“插座”Socket绑定,应用层就可以和传输层通过套接字接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
Socket可以看成在两个程序进行通讯连接中的一个端点,是连接应用程序和网络驱动程序的桥梁,Socket在应用程序中创建,通过绑定与网络驱动建立关系。此后,应用程序送给Socket的数据,由Socket交给网络驱动程序向网络上发送出去。计算机从网络上收到与该Socket绑定IP地址和端口号相关的数据后,由网络驱动程序交给Socket,应用程序便可从该Socket中提取接收到的数据,网络应用程序就是这样通过Socket进行数据的发送与接收的。
套接字的分类
常用的TCP/IP协议的3种套接字类型如下所示。
流套接字(SOCK_STREAM):
流套接字用于提供面向连接、可靠的数据传输服务。该服务将保证数据能够实现无差错、无重复发送,并按顺序接收。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP(The Transmission Control Protocol)协议。
数据报套接字(SOCK_DGRAM):
数据报套接字提供了一种无连接的服务。该服务并不能保证数据传输的可靠性,数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据报套接字使用UDP(User Datagram Protocol)协议进行数据的传输。由于数据报套接字不能保证数据传输的可靠性,对于有可能出现的数据丢失情况,需要在程序中做相应的处理。
原始套接字(SOCK_RAW):
原始套接字(SOCKET_RAW)允许对较低层次的协议直接访问,比如IP、 ICMP协议,它常用于检验新的协议实现,或者访问现有服务中配置的新设备,因为RAW SOCKET可以自如地控制Windows下的多种协议,能够对网络底层的传输机制进行控制,所以可以应用原始套接字来操纵网络层和传输层应用。比如,我们可以通过RAW SOCKET来接收发向本机的ICMP、IGMP协议包,或者接收TCP/IP栈不能够处理的IP包,也可以用来发送一些自定包头或自定协议的IP包。网络监听技术很大程度上依赖于SOCKET_RAW。
原始套接字与标准套接字(标准套接字指的是前面介绍的流套接字和数据包套接字)的区别在于:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送数据必须使用原始套接字。
ip地址
IP地址是一个32位的无符号整数,由于没有转变成二进制,因此通常以小数点分隔,如:198.163.227.6,正如所见IP地址均由四个部分组成,每个部分的范围都是0-255,以表示8位地址。IP地址都是32位地址,这是IP协议版本4(简称Ipv4)规定的,目前由于IPv4地址已近耗尽,所以IPv6地址正逐渐代替Ipv4地址,Ipv6地址则是128位无符号整数。
端口
端口号是一个16位无符号整数,范围是0-65535
Socket网络层次
套接字位于网络中的层次,它位于传输层以上、应用层以下。Socket编程正是通过一系列系统调用(Socket API)来完成应用层协议(如ftp、http)。
套接字是对网络中应用层进程之间的通信进行了抽象,提供了应用层进程利用网络协议栈交换数据的机制。

或者

TCP通信编程流程
首先,服务器端需要做以下准备工作:
- 调用socket()函数。建立socket对象,指定通信协议。
- 调用bind()函数。将创建的socket对象与当前主机的某一IP地址和端口绑定。
- 调用listen()函数。使socket对象处于监听状态,并设置监听队列大小。
客户端需要做以下准备工作:
- 调用socket()函数。建立socket()对象,指定相同通信协议。
- 应用程序可以显式的调用bind()函数为其绑定IP地址和端口,当然,也可以将这工作交给TCP/IP。
接着建立通信连接。
- 客户端调用connet()函数。向服务端发出连接请求。
- 服务端监听到该请求,调用accept()函数接收请求,从而建立连接,并返回一个新的socket文件描述符专门处理该连接。
然后通信双方发送/接收数据。
- 服务端调用write()或send()函数发送数据,客户端调用read()或者recv()函数接收数据。反之客户端发送数据,服务端接收数据。
- 通信完成后,通信双方都需要调用close()或者shutdown()函数关闭socket对象。
UDP通信编程流程
首先,服务器端需要做以下准备工作:
1、调用socket()函数。建立socket对象,指定通信协议。
2、调用bind()函数。将创建的socket对象与某一个UDP端口绑定。
客户端需要做以下准备工作:
- 调用socket()函数。建立socket()对象,指定相同通信协议。
- 调用bind()函数,将创建的socket对象与某一个UDP端口绑定。
然后通信双方发送/接收数据。
- 服务端调用sendto()或sendmsg()函数发送数据,而客户端调用recvfrom()或者recvmsg()函数接收数据。反之客户端发送数据,服务端接收数据。如果不做特殊处理,是不能直接使用read/write来接收/发送数据的,这是因为socket无法知晓发送者IP和端口,而需要在sendto或sendmsg中指定。
- 通信完成后,通信双方都需要调用close()或者shutdown()函数关闭socket对象。
注意:在使用UDP通信时使用了connect和accept,这仅仅是获取对端IP地址等信息,从而可以在后面调用read/write来读写数据,但并不真正的建立连接。
主机字节序和网络字节序
通常,主机字节序(Host Order)就是遵循Little-Endian规则。
网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
采用 Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。(存放的地址是从低到高)
所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序 (Little-Endian)和网络序(Big-Endian)的转换。
多字节数据传送必须要关注数据顺序。对于单字节的数据,比如char型的,没有问题。
在存储主机信息时,IP地址与端口号需要存储为网络的大端模式,因此在为网络地址赋值时需要进行转换,代码如下:
struct sockaddr_in s_addr;
a_addr.sin_port = htons(7838); //端口信息赋值
网络编程中常用的结构体
网络中的地址包含3个方面的属性:
1、地址类型: ipv4还是ipv6
2、ip地址
3、端口
sockaddr和sockaddr_in这两个结构体一样大,都是16个字节,而且都有family属性,不同的是:
sockaddr用14个字节来表示sa_data,而sockaddr_in把14个字节拆分成sin_port, sin_addr和sin_zero分别表示端口、ip地址。sin_zero用来填充字节使sockaddr_in和sockaddr保持一样大小。
sockaddr和sockaddr_in包含的数据都是一样的,但他们在使用上有区别:
程序员不应操作sockaddr,sockaddr是给操作系统用的。
程序员应使用sockaddr_in来表示地址,sockaddr_in区分了地址和端口,使用更方便。
struct sockaddr {
unsigned short sa_family; /* 地址族, AF_xxx */
char sa_data[14]; /* 14字节的协议地址*/
};
上面是通用的socket地址,具体到Internet socket,用下面的结构,二者可以进行类型转换
struct sockaddr_in {
short int sin_family; /* 地址族 */
unsigned short int sin_port; /* 端口号 */
struct in_addr sin_addr; /* Internet地址 */
unsigned char sin_zero[8]; /*可以填充为8个字节0,用来将sockaddr_in结构填充到与struct sockaddr一样的长度 */
};
struct in_addr就是32位IP地址。
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
注意:inet_addr()是将一个点分制的IP地址(如192.168.0.1)转换为上述结构中需要的32位IP地址(0xC0A80001)。
通常的用法是:
int sockfd;
struct sockaddr_in my_addr;
sockfd = socket(AF_INET, SOCK_STREAM, 0);
/* 给socket()加上加上错误检查*/
bzero(&my_addr, sizeof(my_addr)); // 清空,保证最后8字节为0
my_addr.sin_family = AF_INET;
my_addr.sin_port = htons(MYPORT); /* short, 网络字节序 */
my_addr.sin_addr.s_addr = inet_addr(“192.168.0.1″);
上一行可以改为:inet_pton(AF_INET, "192.168.0.1", & my_addr.sin_addr);
bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr)); /* 将my_addr强制转换为struct sockaddr */
/* 给bind()加上错误检查*/
Socket网络编程API
网络通信建立步骤
网络程序是由两个部分组成的--客户端和服务器端。它们的建立步骤一般是:
服务器端
socket-->bind-->listen-->accept
客户端
socket-->connect
创建socket对象 socket()
函数功能
在linux操作系统中,要实现socket通信,通信双方都需要建立各种的socket对象,在应用层,socket对象是一种特殊的文件描述符,可以使用I/O系统调用(read/write)来读写。
头文件
#include <sys/socket.h>
函数原型
int socket(int domain, int type, int protocol);
函数参数
int domain 此socket对象所使用的地址簇或协议簇,即此对象所使用的
通信协议类型。在socket.h中有定义:
AF_UNIX, AF_LOCAL Local communication unix(7)
AF_INET IPv4 Internet protocols ip(7)
AF_INET6 IPv6 Internet protocols ipv6(7)
AF_IPX IPX - Novell protocols
AF_NETLINK Kernel user interface device netlink(7)
AF_X25 ITU-T X.25 / ISO-8208 protocol x25(7)
AF_AX25 Amateur radio AX.25 protocol
AF_ATMPVC Access to raw ATM PVCs
AF_APPLETALK Appletalk ddp(7)
AF_PACKET Low level packet interface packet(7)
最常见的套接字域是 AF_UNIX 和 AF_INET,前者用于通过 Unix 和
Linux 文件系统实现的本地套接字,后者用于 Unix 网络套接字。AF_INET 套接字可以用于通过包括因特网在内的 TCP/IP 网络进行通信的程序。
int type socket的类型。以下是可选用类型:
enum sock_type {
SOCK_DGRAM = 1, //不可靠的,面向无连接的
//数据报spcket,即UDP
SOCK_STREAM = 2, //可靠的,面向连接的流socket,即TCP
SOCK_RAW = 3, //原始套接口
SOCK_RDM = 4,
SOCK_SEQPACKET = 5,
SOCK_DCCP = 6,
SOCK_PACKET = 10,
};
int protocol 因为指定了type,所以一般将这个参数设置为0,表示使用默认协议。
函数返回
如果成功则返回一个打开的socket文件描述符,此时,该socket对象没有绑定任何IP信息,还不能进行通信,如果失败,返回-1并设置errno。
绑定IP地址与端口 bind()
函数功能
使用socket()创建的socket没有任何约束,它没有与具体的端口号相关联,在服务器端,需要使用bind函数绑定该套接字。此函数将指定的socket与对应网络地址(含有IP和端口信息)(“sockaddr结构”)绑定。
头文件
#include <sys/socket.h>
函数原型
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
函数参数
int sockfd 由socket函数返回的文件描述符。
const struct sockaddr *addr 指向一个sockaddr结构的指针。
sockaddr数据结构:
struct sockaddr {
unsigned short sa_family; /* 地址族, AF_xxx */
char sa_data[14]; /* 14字节的协议地址*/
};
注意:struct sockaddr只是提供地址类型规范,根据不同的应用,sockaddr需要选用不同的类型,而不是上面那个。
如果选择本机通信(AF_UNIX或AF_LOCAL),其通信需要依靠本地socket类型的文件,所以选用以下结构体:
struct sockaddr_un {
__kernel_sa_family_t sun_family; //协议AF_UNIX
char sun_path[UNIX_PATH_MAX]; //文件路径名,使用前该文件不能存在。
};
如果选择IPV4网络通信,socket需要与具体的主机端口绑定,所以选用以下结构体:
struct sockaddr_in {
short int sin_family; /* 地址族 */
unsigned short int sin_port; /* 端口号 */
struct in_addr sin_addr; /* Internet地址 */
unsigned char sin_zero[8]; /*可以填充为8个字节0,用来将sockaddr_in结构填充到与struct sockaddr一样的长度 */
};
struct in_addr就是32位IP地址。
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
注意:端口对任何一个socket都是唯一的,唯一的端口号可以区分
本地唯一的应用程序,所以socket所绑定的端口不能与其他应用程序重复,linux操作系统中,小于1024的端口号为系统保留,用户应用程序不能随便使用。
socklen_t addrlen 绑定的地址长度,一般用sizeof求得。
函数返回
如果执行成功返回0,失败返回-1并设置errno。
示例
int sockfd;
struct sockaddr_in my_addr;
sockfd = socket(AF_INET, SOCK_STREAM, 0);
/* 给socket()加上加上错误检查*/
bzero(&my_addr, sizeof(my_addr)); // 清空,保证最后8字节为0
my_addr.sin_family = AF_INET;
my_addr.sin_port = htons(MYPORT); /* short, 网络字节序 */
my_addr.sin_addr.s_addr = inet_addr(“192.168.0.1″);
上一行可以改为:inet_pton(AF_INET, "192.168.0.1", & my_addr.sin_addr);
bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr)); /* 将my_addr强制转换为struct sockaddr */
/* 给bind()加上错误检查*/
监听网络 listen()
函数功能
绑定了IP及端口信息的socket对象还不能进行TCP方式的通信,因为当前还没有能力监听网络请求,因此,对于面向连接的应用来说,服务器端需要调用listen()函数使该socket对象监听网络,创建一个请求队列。
listen函数将绑定的socket文件描述符变为监听套接字,此时,服务器已经准备接收员接收客户端连接请求了。
头文件
#include <sys/socket.h>
函数原型
int listen(int sockfd, int backlog);
函数参数
int sockfd bind后(绑定了IP和端口信息)的socket文件描述符
int backlog 请求排队的最大长度。当有多个客户端程序和服务端相连时,此值表示可以使用的处于等待的队列长度。
函数返回
如果执行成功返回0,失败返回-1并设置errno。
客户端发起连接 connect()
函数功能
如果服务器已经监听网络,且客户端创建了socket对象,则客户端可以使用connect函数与服务器端建立连接了。
头文件
#include <sys/socket.h>
函数原型
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
函数参数
int sockfd socket返回的文件描述符
const struct sockaddr *addr 存储了服务器端的地址(包括服务器的IP地址
和端口信息)
socklen_t addrlen 该地址的长度
函数返回
如果执行成功返回0,失败返回-1并设置errno。
服务端接收连接 accept()
函数功能
如果服务器端监听到客户端的连接请求,则需要调用accept函数接收请求,如果没有监听到客户端的连接请求,此函数将处于阻塞状态,直到有一个客户程序发起了连接。
如果执行成功,返回一个新的文件描述符以标识该连接,这个时候服务器端可以向该描述符写信息了
头文件
#include <sys/socket.h>
函数原型
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
函数参数
int sockfd listen后(监听网络后)的socket文件描述符。
struct sockaddr *addr 为struct sockaddr类型的地址空间首地址,用来存储
客户端的IP地址和端口信息,以便为客户端返回数据。
addr和addrlen这两个参数是用来给客户端的程序
填写的,服务器端只要传递指针就可以了。
socklen_t *addrlen 该段地址空间长度。
函数返回
如果执行成功,返回一个新的文件描述符以标识该连接,从而使原来的文件描述符可以继续等待新的连接,这样便可以实现多客户端,如果执行失败。返回-1并设置errno。
读/写socket对象 write()和read()
函数功能
socket对象是一类特殊的文件,可以使用linux系统I/O系统调用read函数来读socket对象数据,write函数向socket对象写入数据。这两个函数对socket的读写操作默认以阻塞的方式进行。
头文件
#include <unistd.h>
函数原型
ssize_t write(int fildes, const void *buf, size_t nbyte);
ssize_t read(int fildes, void *buf, size_t nbyte);
参考文件操作内容。
TCP发送接收数据 send()和recv()
函数功能
除了read和write函数,linux还提供了send()和recv()函数来专门实现面向连接的socket对象进行读写操作。
send()函数:将buf中的len字节数据发送到sockfd所指的socket对象。
recv()函数:将从sockfd所指的socket中读取len字节数据到buf中。
头文件
#include <sys/types.h>
#include <sys/socket.h>
函数原型
ssize_t send(int sockfd, const void *buf, size_t len, int flags); //发送数据
ssize_t recv(int sockfd, void *buf, size_t len, int flags); //接收数据
函数参数
int sockfd 发送/接收的目标socket对象
const void *buf 发送/接收的数据位置
size_t len 数据大小
int flags 操作flags,可设置为0(设置为0的话,相当于套接字
调用write函数)或以下值:
/* Flags we can use with send/ and recv.
Added those for 1003.1g not all are supported yet
*/
#define MSG_OOB 1 //带外数据
#define MSG_PEEK 2 //查看外来消息。系统不丢弃查看到的数据。
#define MSG_DONTROUTE 4 //本地不路由
#define MSG_TRYHARD 4 /* Synonym for MSG_DONTROUTE for DECnet */
#define MSG_CTRUNC 8
#define MSG_PROBE 0x10 /* Do not send. Only probe path f.e. for MTU */
#define MSG_TRUNC 0x20
#define MSG_DONTWAIT 0x40 /* 不阻塞Nonblocking io */
#define MSG_EOR 0x80 /* End of record */
#define MSG_WAITALL 0x100 /* 等待所有数据Wait for a full request */
#define MSG_FIN 0x200
#define MSG_SYN 0x400
#define MSG_CONFIRM 0x800 /* Confirm path validity */
#define MSG_RST 0x1000
#define MSG_ERRQUEUE 0x2000 /* Fetch message from error queue */
#define MSG_NOSIGNAL 0x4000 /* 不产生SIGPIPE信息Do not generate SIGPIPE */
#define MSG_MORE 0x8000 /* Sender will send more */
#define MSG_WAITFORONE 0x10000 /* recvmmsg(): block until 1+ packets avail */
#define MSG_SENDPAGE_NOTLAST 0x20000 /* sendpage() internal : not the last page */
#define MSG_BATCH 0x40000 /* sendmmsg(): more messages coming */
#define MSG_EOF MSG_FIN
函数返回
如果执行成功,返回发送/接收数据的大小,如果失败,返回-1并设置errno。
UDP发送接收数据 sendto()和 recvfrom()
函数功能
对于UDP方式,发送数据时需要显示指定数据包的目的地址,因此,一般情况下不使用read/write/send/recv函数,而使用sendto()函数实现UDP方式向某一主机发送字节序列。与之对应的接收字节序列函数为recvfrom函数。
头文件
#include <sys/types.h>
#include <sys/socket.h>
函数原型
发送:
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
接收:
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
函数参数
sendto()函数:
int sockfd 发送的目标socket对象
const void *buf 发送的数据信息
size_t len 数据大小
int flags 操作flags,如send函数一样
const struct sockaddr *dest_addr 要发送数据的目的地址(结构体前面有)。
socklen_t addrlen 结构体大小
recvfrom()函数:
int sockfd 接收的目标socket对象
void *buf 接收的数据信息
size_t len 数据大小
int flags 操作flags,如send函数一样
struct sockaddr *src_addr 用来存储数据的源地址信息(协议类型、IP和端口)
socklen_t *addrlen 存储源地址所占空间大小。
函数返回
如果执行成功,返回发送/接收数据的大小,如果失败,返回-1并设置errno。
关闭socket对象 close()和 shutdown()
函数功能
在通信结束后,需要关闭socket对象,一种是直接调用close函数,一种是调用shutdow函数,其有更大的灵活性,shutdown函数可以关闭全部或socket的一端。
头文件
#include <unistd.h> //close函数
#include <sys/socket.h> //shutdown函数
函数原型
int close(int fd);
int shutdown(int sockfd, int how);
函数参数
int sockfd 要关闭的socket对象
int how TCP连接是双向的(是可读写的),当使用close时,会把读写通道都
关闭,有时侯希望只关闭一个方向,这个时候就需要使用shutdown。
系统提供了以下三种关闭方式:
howto=0这个时候系统会关闭读通道,但是可以继续往socket描述符中写。
howto=1关闭写通道,和上面相反此时只可以读。
howto=2关闭读写通道,和close一样 在多进程程序里,当几个子进程共享一个套接字时,如果使用shutdown,那么所有的子进程都将不能操作,这时只能使用close函数来关闭子进程的套接字描述符.
函数返回
如果执行成功返回0,失败返回-1并设置errno。
获取socket本地信息 getsockname()
函数功能
使用getsockname()函数将获得一个套接字(这个套接字至少完成了绑定本地IP地址)的本地地址。
头文件
#include <sys/socket.h>
函数原型
int getsockname(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
函数参数
int sockfd 要读取信息的socket文件描述符。
struct sockaddr *addr 存储地址的内存空间
socklen_t *addrlen 空间大小
函数返回
如果执行成功返回0,失败返回-1并设置errno。
应用示例
struct sockaddr_ test;
getsockname(new_fd, (struct sockaddr *)&test, &size);
printf(“ip = %s, port = %d\n”, inet_ntoa(test.sin_addr), ntohs(test.sin_port));
获取socket对端信息 getpeername()
函数功能
使用getpeername()函数将获得一个已经连接上的套接字的远程信息,比如IP地址和端口。
头文件
#include <sys/socket.h>
函数原型
int getpeername(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
函数参数
int sockfd 要读取信息的socket文件描述符。
struct sockaddr *addr 存储地址的内存空间
socklen_t *addrlen 空间大小
函数返回
如果执行成功返回0,失败返回-1并设置errno。
字节顺序处理函数htonl、htons、ntohl、ntohs
函数功能
大小端的转换,比如对端口的设置进行字节顺序转换。这是因为在处理主机地址时,IP地址和端口信息都需要以大端方式存储在主机上。以下四个函数将实现网络字节序与主机字节序的转换。
头文件
#include <arpa/inet.h>
函数原型
uint32_t htonl(uint32_t hostlong); //主机字节序——》TCP/IP网络字节序
uint16_t htons(uint16_t hostshort); //主机字节序——》TCP/IP网络字节序 uint32_t ntohl(uint32_t netlong); // TCP/IP网络字节序——》主机字节序
uint16_t ntohs(uint16_t netshort); // TCP/IP网络字节序——》主机字节序
函数参数
uint32_t hostlong
uint16_t hostshort
uint32_t netlong
uint16_t netshort
函数返回
如果执行成功返回0,失败返回-1并设置errno。
点分十进制IP地址(字符串)转换为二进制IP地址(32位)
函数功能
目前,网络主机存储的IP地址值为32位的二进制代码,而一般用户熟悉的是点分十进制的字符串方式。因此,在应用时需要在两者间进行转换。
该函数将点分十进制的字符串转换成32位的网络字节序的IP信息。
头文件
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
函数原型
in_addr_t inet_addr(const char *cp);
函数参数
const char *cp 点分十进制的字符串方式的IP信息。
函数返回
如果执行成功,将返回32位的网络字节序的IP地址。
二进制IP地址(32位)转换为点分十进制IP地址(字符串) inet_ntoa()
函数功能
目前,网络主机存储的IP地址值为32位的二进制代码,而一般用户熟悉的是点分十进制的字符串方式。因此,在应用时需要在两者间进行转换。
该函数将32位的网络字节序的IP信息转换成点分十进制的字符串方式。
头文件
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
函数原型
char *inet_ntoa(struct in_addr in);
函数参数
struct in_addr in 为网络存储顺序的IP地址
例程:使用TCP实现简单网络通信
服务器端:

客户端:

TCP三次握手和四次挥手
tcp协议格式
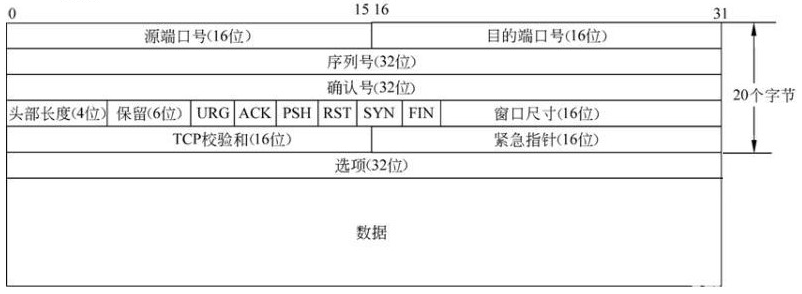
三次握手
在 TCP/IP 协议中,TCP 协议提供可靠的连接服务,采用三次握手建立一个连接。
第一次握手:建立连接时,客户端发送 syn 包(tcp协议中syn位置1,序号为J)到服务器,并进入 SYN_SEND 状态,等待服务器确认;
第二次握手:服务器收到 syn 包,必须确认客户的 SYN,同时自己也发送一个 SYN 包,即 SYN+ACK包(tcp协议中syn位置1,ack位置1,序号K,确定序号为J+1),此时服务器进入 SYN_RECV 状态;
第三次握手:客户端收到服务器的 SYN+ACK 包,向服务器发送确认包 ACK(tcp协议中ack位置1,确认序号K+1),此包发送完毕,客户端和服务器进入 ESTABLISHED 状态,完成三次握手。
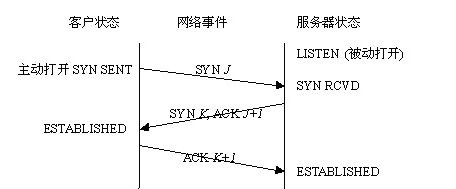
通过这样的三次握手,客户端与服务端建立起可靠的双工的连接,开始传送数据。 三次握手的最主要目的是保证连接是双工的,可靠更多的是通过重传机制来保证的。
对于TCP为什么需要进行三次握手我们可以一样的理解:
为了保证服务端能收接受到客户端的信息并能做出正确的应答而进行前两次(第一次和第二次)握手,为了保证客户端能够接收到服务端的信息并能做出正确的应答而进行后两次(第二次和第三次)握手。
四次挥手
由于 TCP 连接是全双工的,因此每个方向都必须单独进行关闭。这好比,我们打电话(全双工),正常的情况下(出于礼貌),通话的双方都要说再见后才能挂电话,保证通信双方都把话说完了才挂电话。
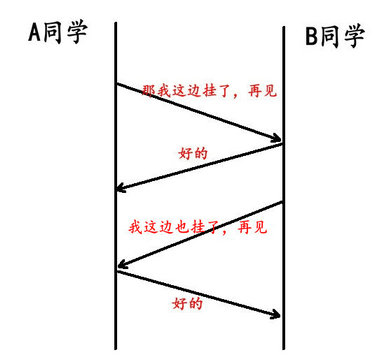
那TCP 的四次握手,是为了保证通信双方都关闭了连接,具体过程如下:
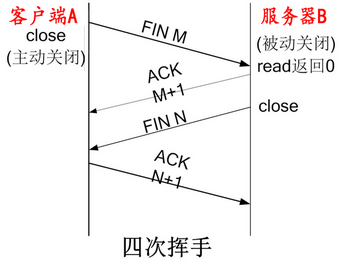
四次挥手过程
1、客户端 A 在应用层调用close时会激发底层发送一个 FIN(tcp协议中FIN位置1、、序号为M,结合上图分析)请求,用来关闭客户 A 到服务器 B 的数据传送,客户端A此时处于半关闭状态(应用层无法接收数据但底层还可以接收数据);
2、服务器 B 底层收到客户端A的FIN时会做两件事:
第1件事:收到客户端A的FIN时底层会主动回发一个ACK(tcp协议中ACK位置1,确认序号M+1)
第2件事:收到客户端A的FIN时,导致服务器B的应用层read()返回0(告诉服务器B应用层:客户端A关闭了)
3、服务器B应用层调用close()激发底层给客户端 A 发送一个 FIN(tcp协议中FIN位置1、序号为N),这是服务器B已处于半关闭状态;
4、客户端 A 底层回发 ACK(tcp协议中ACK位置1,确认序号N+1) 给服务器B,这是客户端A、服务器B都处于完全关闭状态,回收相应的资源。
为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
这是因为服务端的 LISTEN 状态下的 SOCKET 当收到 SYN 报文的建连请求后,它可以把 ACK 和 SYN(ACK 起应答作用,而 SYN 起同步作用)放在一个报文里来发送。但关闭连接时,当收到FIN 报文通知时,如果能将ACK、FIN放在一个报文里那么就有了三次挥手,但是这是不可能,因为ACK是服务器B一收到FIN报文底层就回发的,而服务器B的FIN是应用层调用close()激发的,所以它这里的 ACK 报文和 FIN 报文在发送的时间上都是分开的,不可能同时发送。
为什么 TIME_WAIT 状态还需要等 2MS L后才能返回到 CLOSED 状态?
这是因为虽然双方都同意关闭连接了,而且握手的 4 个报文也都协调和发送完毕,按理可以直接回到 CLOSED 状态(就好比从 SYN_SEND 状态到 ESTABLISH 状态那样);但是因为我们必须要假想网络是不可靠的,你无法保证你最后发送的 ACK 报文会一定被对方收到,因此对方处于 LAST_ACK 状态下的 SOCKET 可能会因为超时未收到 ACK 报文,而重发 FIN 报文,所以这个 TIME_WAIT 状态的作用就是用来重发可能丢失的 ACK 报文。