前言:之前学习链表的时候总会遇到一些问题
也看了好多人的文章感觉有些不是太实用
然后后来也是自己摸索才大概写出来的.
在真正的开发中会把链表的增删改查写到函数里
但是删除有点麻烦 找了很多都是删除第几个 而不是删除某个值对应的节点 让我很难受
所以想写一些链表的操作分享一些 我也不会用长一点的名字去命名 这样阅读性会好一些
不过在实际开发中建议使用较长的名字去命名好了 话不多说
一.链表的创建
一般分为头插法和尾插法
1.我在写项目的时候喜欢使用头插法
因为我希望在创建结点的时候按照某种方法去排序
如果用尾插法创建的话快 但是 如果在创建好后再排序就有些麻烦
话不多说贴代码.
第一步 让我们写出这个结点的声明`
typedef struct node {
int data;
struct node* next;
} Node;
然后先让我们看看主函数中该怎么写
#include <stdio.h>
#include <stdlib.h>
int main() {
Node *head;
head = NULL;
int n;//这里的n代表创建多少个结点
scanf("%d",&n);
for (int i = 0; i < n; ++i) {
int a;//这里的a代表传给结点的值
scanf("%d",&a);
insert(&head, a);//insert 增加链表结点函数
}
Node *temp = head;
while(temp != NULL) { //输出这个链表
printf("%d ",temp->data);
temp = temp->next;
}
return 0;
}接下来就是inser()函数的写法了.
首先我们需要在这个函数里面创建一个结点
void insert(Node **head ,int value) {//这个参数是取头结点的地址.
Node *temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
}然后怎么利用头结点的头插法把这个链表连起来呢?
我们首先得判断 这个头结点是不是为NULL 因为在定义的时候定义了NULL
if((*head) == NULL) {//这里*head 因为head是二级指针 加个*就降了一级.
(*head) = temp; //建议全部带括号*这个运算符的结合律防止出错都带括号把
}其实这个判断也就是判断是不是第一次创建 头结点有没有东西
头结点要是有了东西呢?
else {
Node *t = (*head); //让临时指针的从头开始遍历.
while(t->next != NULL) { // 这里一定是t->next 如果让t连的话 就连接不起来
t = t->next;
}
t->next=temp; //指针域的作用就是连接.
}好了 这就是头插法的创建
但是我们明显发现效率不高 尾插法创建一个就接到链表里面
创建一个就接进去.
但是头插法不行. 必须是创建一个 再从头开始.
但是!
看接下来的一个妙用 我要创建链表并且排序.
这里我们做一个约定 从小到大排列.让我们看看怎么做
还是像刚才创建一样 如果头是空怎么怎么样 否则怎么怎么样对吗?
想一想要改这里吗?
if((*head) == NULL) {
(*head) = temp;
} else {答案肯定是不用改因为没数据肯定就把第一个放进去.
那么肯定就是改下一处了
按照我们刚在的想法是不是可以这样写
while(t != NULL) {
if(t->next->data > temp->data) { // 如果t的下一个的数据大于了新结点
temp->next = t->next; //让新结点的指针指向了t的下一个
t->next = temp; //再让t指向新结点
return; //返回就好
}
t = t->next;
}但是这里其实是有两处问题的 先说第一处:
因为是从小到大比较的 我们上面的写法是从头开始
找到比他大的地方就让他插进去.但是如果新的结点就是最大的呢
也就是跑到完都没进到 if 语句中去
所以应该加一个
while(t != NULL) {
if(t->next == NULL) {//这一次我们判断下一个是不是空
t->next = temp; //如果是空了连接一下
return; //返回就行
} else if(t->next->data > temp->data) {
temp->next = t->next;
t->next = temp;
return;
}
t = t->next;
}上述不要忘记了返回
还有一个问题就是如果新的结点比头结点小了怎么办
看看我们上面的写法他永远比较的是当前结点的下一个 也就是头结点根本没有比较
所以我们让他在开始的时候比较一下就好了
if(temp->data < (*head)->data) {
temp->next = (*head);//新结点的下一个指向头结点
(*head) = temp; //头结点变成了新结点
return; //返回
}好了 这里就写完了 开发的时候具体按照你的方式去创建链表 要比较什么 你自己定
完整代码
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
} Node;
void insert(Node **head ,int value) {//这个参数是取头结点的地址 因为在主函数中定义了这个头结点 Node* head;所以要传地址过来.
Node *temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
Node *t = (*head);
if(temp->data < (*head)->data) {
temp->next = (*head);
(*head) = temp;
return;
}
while(t != NULL) {
if(t->next == NULL) {
t->next = temp;
return;
} else if(t->next->data > temp->data) {
temp->next = t->next;
t->next = temp;
return;
}
t = t->next;
}
}
}
int main() {
Node *head;
head = NULL;
int n;//这里的n代表创建多少个结点
scanf("%d",&n);
for (int i = 0; i < n; ++i) {
int a;//这里的a代表传给结点的值
scanf("%d",&a);
insert(&head, a);//insert 增加链表结点函数
}
Node *temp = head;
while(temp != NULL) { //输出这个链表
printf("%d ",temp->data);
temp = temp->next;
}
return 0;
}头插法讲完了 让我们讲一下尾插法
先看一下 一般的创建方式
首先尾插法的核心代码
for(int i = 0; i < n; i++) {
temp = (Node*)malloc(sizeof(Node));
temp->next = NULL; //这里很重要
scanf("%d",&temp->data);
if(head == NULL) {
head = temp;
} else {
q->next = temp; //连接起来
}
q = temp; //尾插法的核心
}解读 : 创建n个结点 一开始也一样 判断head 是不是空
是的话就让head是第一个结点.
同时我们有个尾巴这个时候因为是第一个结点所以 尾巴也指向了temp
也就是 创建完第一个 我们的 head 和 q 这个指针都指向的第一个结点
然后第二个来了就用(尾结点)q->next的指针指向了第二个结点
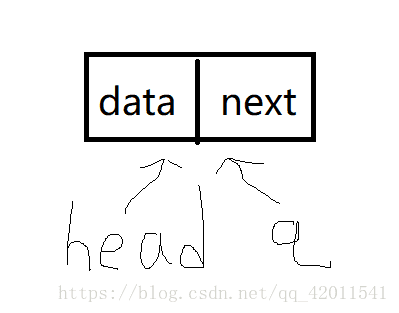
像这样子 第一个结点 head 和 q都指向第一个
来了一个结点
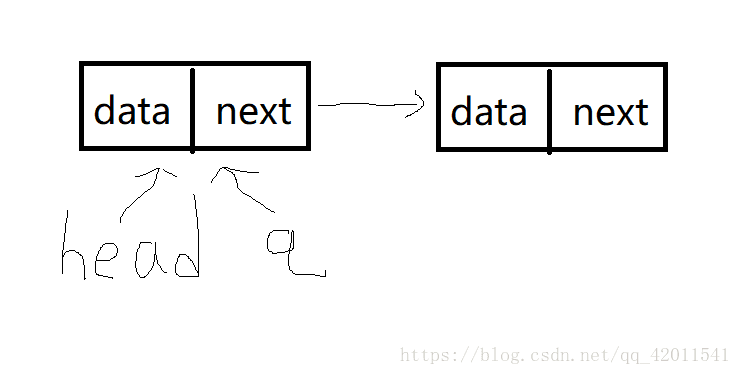
q->next就把第二个连上了
然后q又成了新结点 像这个样子
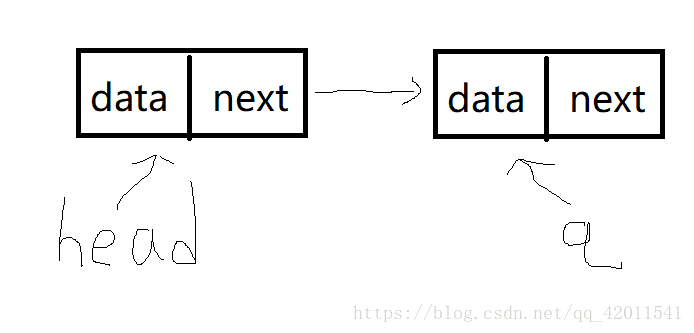
我们发现什么 创建一个结点q->next连接后
q又指向了新结点
q像不像一个尾巴?
好了 把他放函数里面吧
但是! 我们发现一个问题 怎么保留这个尾巴呢?
想一想你调用函数 在函数里面保留尾巴
函数结束就释放掉了
所以我们有三个方法
第一个就是把尾巴定义在主函数里 然后每次把这个尾巴的地址传过去 在里面改变尾巴
像这样子
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
} Node;
void insert(Node **head, Node **q, int value) {// 第一个头的地址 第二个尾的地址
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
}
int main() {
Node *head, *temp, *q;
head = NULL;
int n;
scanf("%d",&n);
for(int i = 0; i < n; i++) {
int a;
scanf("%d",&a);
insert(&head, &q, a);
}
Node *t = head;
while(t != NULL) {
printf("%d ",t->data);
t = t->next;
}
return 0;
}然后 判断方面和一开始的头插不太一样 和尾插的是一样 来看看
void insert(Node **head, Node **q, int value) {// 第一个头的地址 第二个尾的地址
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
(*q)->next = temp;
}
(*q) = temp;
return;
}怎么样? 很简单吧?
说一下第二种方式 就是多了一个返回值 返回一个Node*
然后传尾结点的形参就行了
Node* insert(Node **head, Node *q, int value) 函数声明变成了这样
for(int i = 0; i < n; i++) {
int a;
scanf("%d",&a);
q = insert(&head, q, a);
}然后主函数里 这样调用函数
Node* insert(Node **head, Node *q, int value) {
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
q->next = temp;
}
q = temp; //在这里改变了尾结点
return q;// 返回新的尾结点
}函数体
然后就是第三种方法用到了 static关键字
不知道可以百度下 就是在函数里面用static关键字修饰了尾结点
你就可以每次调用这个函数这个结点就一直保留上次的值
方法就是这样 也不用传一个尾结点过来
void insert(Node **head, int value) {// 第一个头的地址 第二个尾的地址
static Node* q;
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
q->next = temp;
}
q = temp;
return ;
}好了链表的增加到此结束
二.链表的删除
这个是比较难的.我们这里的删除用的是输入一个值去删除一个结点 或者全部删除
比如开发学生管理系统 你要按照学号去删除人
或者开发票务管理系统按照电影票去删除 你并不知道他是第几个对不对
好了,开始吧.
让我们给出这个函数的声明
void remove(Node **head, int key);两个参数 一个是链表的头.从头开始删除
一个是要删除对应的数据
比如 3 5 4 8 5 4 5
删除5
就变成了 5 5 5
好了 开始写函数吧 首先得有个东西从头开始遍历
void remove(Node **head, int key) {
Node *t = (*head);
}这样写OK把?
我们从头开始遍历 我们可以定义 如果当前的结点的下一个结点和key相等
就让一个临时结点保存下一个结点并且当前结点指向下一个结点的下一个结点
就比如当前结点是1号结点
有1->2->3->NULL
然后传过来的key就是2
那么我让一个临时结点保存2号结点 让1->3->NULL
然后free(2)就可以
if(t->next->data == key) { // 如果相等就释放相应的结点
Node* temp = t->next;
t->next = t->next->next;
free(temp);
} else {//否则才让t = t->next 想一想为什么
t = t->next;
}上述想一想.
因为 如果不把t = t->next放在else里看一下下面的情况
key = 3
你的结点是2 3 3 3 2
我们现在删除第二号结点 也就是第一个3
删完后变成了
2->3->3->2->NULL
然后这个时候t是什么?
t就是第二个结点 然后过来判断 t的下一个是不是3 是3删除了
然后2->3->2->NULL
然后跑完了 发现并没有删除完全.所以删除结点就别让这个跑了
好了然后看一下这个删除的完整代码
while(t->next != NULL) {
if(t->next->data == key) {
Node* temp = t->next;
t->next = t->next->next;
free(temp);
} else {
t = t->next;
}
}但是上述还有一个问题 如果删的那个刚好是头呢?
我们是从第二个开始删的因为我并没有用一个东西去保留上一个结点 所以我判断当前的下一个 这样好删些
所以头结点是无法删除的
怎么解决这个问题呢? 单独判断下就好了
想一想是在while循环开始 还是 结束之后?
肯定是结束之后啊.
要是在开始 发现前两个都是你要删的 你是不是又漏删一个.
所以一个while循环跑完 该删的都删完了 就剩头了 头要么是 要么不是
判断一下 是就删了 不是就不管
.
if((*head)->data == key) {
Node* temp = (*head);
(*head) = (*head)->next;
free(temp);
}好了 看一下 删除的完整代码
void remove(Node **head, int key) {
Node *t = (*head);
while(t->next != NULL) {
if(t->next->data == key) {
Node* temp = t->next;
if(t->next->next == NULL) {
t->next = NULL;
free(temp);
break;
} else {
t->next = t->next->next;
free(temp);
}
} else {
t = t->next;
}
}
if((*head)->data == key) {
Node* temp = (*head);
(*head) = (*head)->next;
free(temp);
}
}好了 其实 删除有很多种方式 你可以知道原理后自己写 注意有一些细节
那么相对来说难一些的删除都搞定了改 查两个超简单的还难嘛?
三.链表的改
说一下 链表的改一般来说是改单个链表 链表的改其实可以和链表的查联合起来
链表查到了一个结点返回给链表修改功能链表一改岂不是美滋滋
我这里 单独写一个功能
哈哈哈 后面就好写了 写完链表的查 再写另外一版本
来改链表函数声明
void change(Node **head, int key);//由于是要更改所以传地址第一个参数是链表的头 第二个是要修改的那个序号
其实我们这里面重复用到了链表的查找
写完链表的查 再写一版修改
还是老模版 从头开始 只不过这次不像删除那么麻烦 好了 话不多说
直接上完整代码
void change(Node **head, int key) {
Node *t = (*head);
while (t != NULL) {
if (t->data == key) {
//这里写修改
break; //全改就不要break; 改一个就break;
}
t = t->next;
}
}链表的改写完了, 是不是很简单?
四.链表的查
我这里链表的查分为两种
1.带返回值
带返回值我们返回一个结点
函数声明
Node* find(Node **head, int key);后面的话不多话 找到了这个 就返回这个结点
直接完整代码:
Node* find(Node *head, int key) { //这里head一维指针不用修改操作
Node *t = (*head);
while(t != NULL) {
if(t->data == key) {
return t;
}
t = t->next;
}
}2.不带返回值
完整代码
void find(Node *head, int key) {//这里head一维指针不用修改操作
Node *t = (*head);
while(t != NULL) {
if(t->data == key) {
printf("");
//....省略一大堆代码
}
t = t->next;
}
}第二个找到全部的输出 比如符合的电影票 火车票OK
我们上次说的可以用查和改写一个代码
先写两个声明
Node* find(Node *head, int key);
void change(Node **head, int key);Node* find(Node *head, int key) {
Node *t = head;
while(t != NULL) {
if(t->data == key) {
return t;
}
t = t->next;
}
}
void change(Node **head, int key) {
Node *t = find((*head), key);
//这里修改t这个结点的代码
}好了 就到这里
如果我写链表到这你能完全跟的上 不妨看看我另外一篇存储数据的结构
二叉树 其实真的和链表很像
https://blog.csdn.net/qq_42011541/article/details/80547098