**
初学大数据 day01
大数据
短时间内快速的产生海量的多种多样的有价值的数据
大数据技术:
分布式存储
分布式存储简单的来说,就是将数据分散存储到多个存储服务器上,并将这些分散的存储资源构成一个虚拟的存储设备。
分布式存储架构由三个部分组成:客户端、元数据服务器和数据服务器。客户端负责发送读写请求,缓存文件元数据和文件数据。元数据服务器负责管理元数据和处理客户端的请求,是整个系统的核心组件。数据服务器负责存放文件数据,保证数据的可用性和完整性。
分布式计算
元数据处理方式:
1.分布式批处理
攒一段时间的数据,然后在未来某一个时间来处理这些数据。
2.分布式流处理(实时处理)
数据不积攒,每产生一条数据,立即对这条数据进行处理。
HDFS工作原理
Client: 客户端提交文件到HDFS中保存,将大文件切割成一个个block
NameNode:管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;包含了block的位置信息;每一个DataNode的位置信息,DataNode的心跳信息;文件的属性、权限、上传时间。
SecondaryNameNode:是NameNode的跟班,分担namenode的工作量;模拟执行edits文件,合并fsimage和fsedits然后再发给namenode。
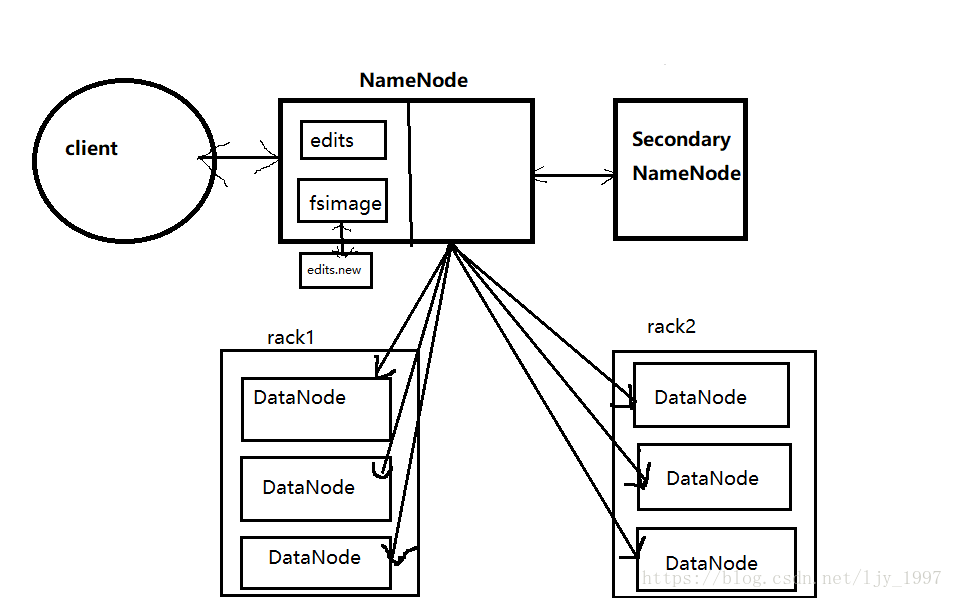
DataNode:负责存储client发来的数据块block;执行数据块的读写操作。
rack:机架
fsimage:文件系统的目录树
edits:针对文件系统做的修改操作记录
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。所以讲secondarynamenode,单独放置到一台机器上,可以增大冗余,但是有可能会丢失一小时内处理的数据。
工作流程:
1.如果要上传一个大文件,计算大文件的block数量,大文件地址/128m=block数
2.client会向namenode汇报:(1)当前大文件的block数 (2)当前大文件属于谁 权限 (3)上传时间
3.client切割出来一个block
4.请求block块的id号以及地址
5.因为nameNode能够掌控全局,管理所有的DataNode,会将负载不高的DataNode地址返回给client
6.client 拿到地址后,找到DataNode去上传数据
7.DataNode存储完毕后,会向NameNode回报当前的存储情况
client向DataNode写数据的流程
NodeName返回给Client一批地址后,这些DataName之间会形成一个Pipeline管道
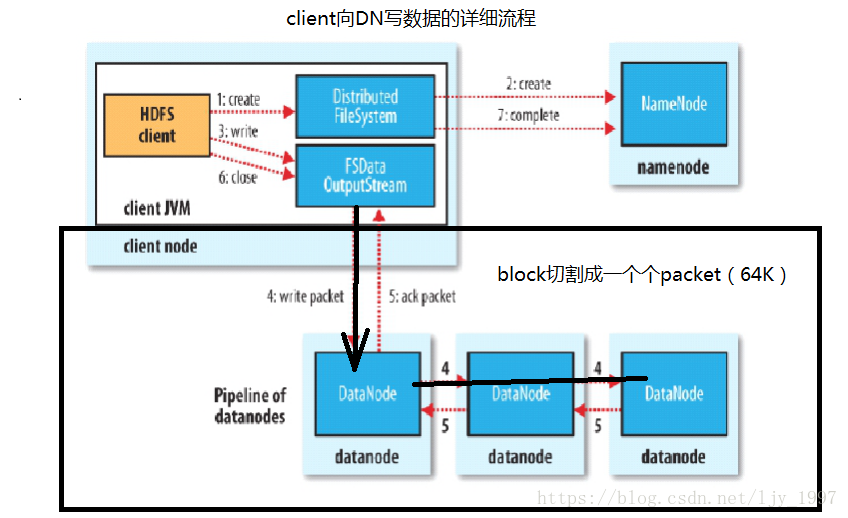
nameNode元数据,在内存中不稳定,可以将数据持久化到磁盘上。
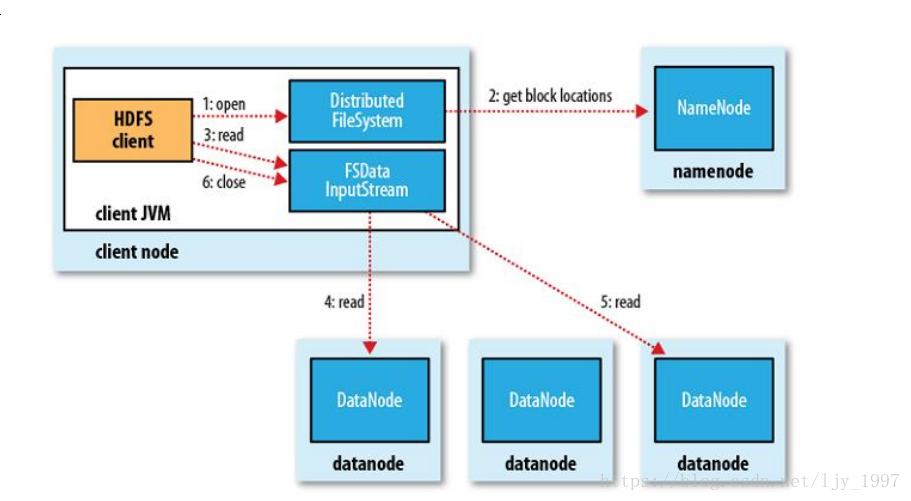
持久化的过程
并非所有的元数据都会持久化,除了Block位置信息,其他元素都会持久化。

备份机制
1.第一个block存储在负载不是很高的一个服务器上
2.第1个备份的block存储在与第一个block不同的机架随机一条服务器上
3.第2个备份在与第一个备份相同的机架随即一台服务器。