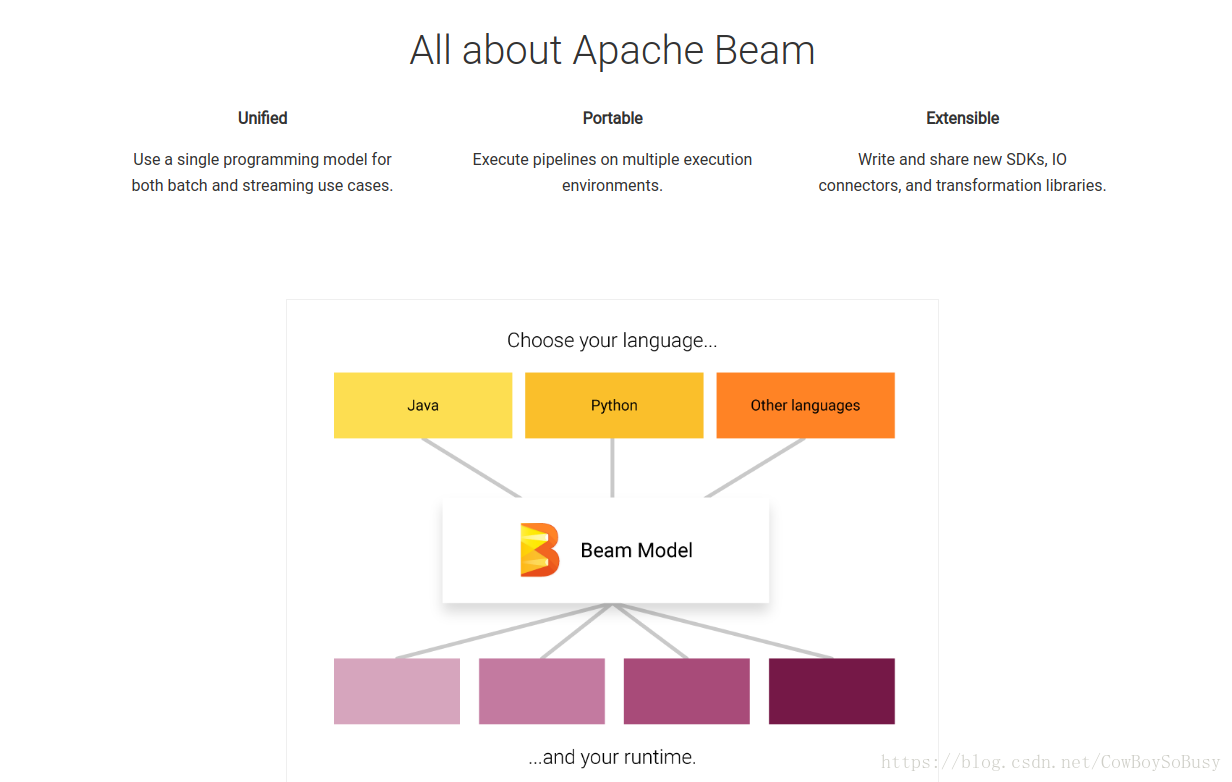
ApacheBeam是统一批处理(Batch)模式和数据流(Stream)处理模式的标准. 在大数据各种框架中,比如进行批处理的MapReduce,实时流处理的Flink,以及SQL交互的Spark SQL等等,把这些开源框架,工具,类库,平台整合到一起,所需要的工作量以及复杂度,可想而知。这也是大数据开发者比较头疼的问题。而整合这些资源的一个解决方案,就是 Apache Beam。
java快速启动:https://beam.apache.org/get-started/quickstart-java/
将WordCount的Beam程序以多种不同Runner运行:
Get the WordCount Code:
在终端中输入以下命令
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.7.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
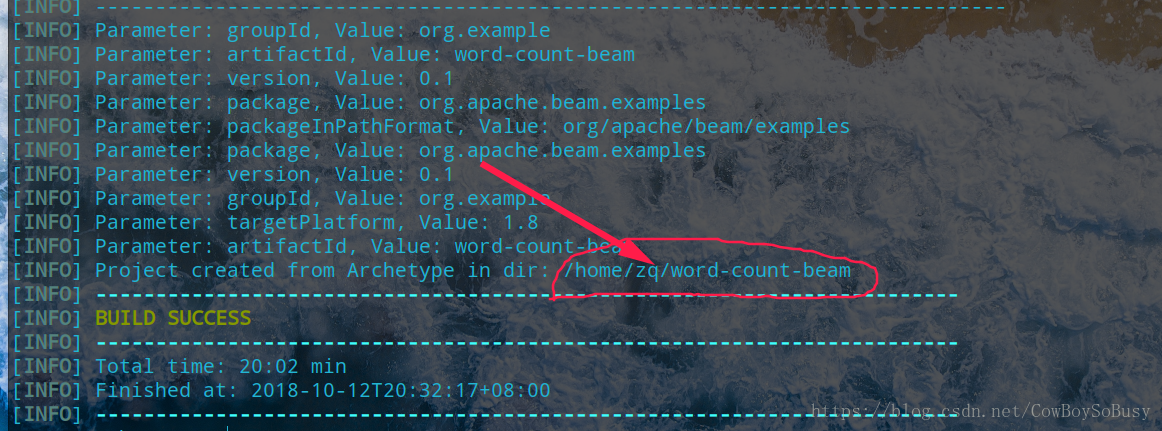
将会下载一段时间,自动会创建一个word-count-beam的文件夹,里面包含pom.xml文件
可见创建成功
输入tree查看文件夹树结构
A single Beam pipeline can run on multiple Beam runners, including the ApexRunner, FlinkRunner, SparkRunner or DataflowRunner.
运行WordCount:
1.DirectRunner

mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=/home/zq/Desktop/test.txt --output=counts" -Pdirect-runner
讲真,第一次的时候下载这么多jar包,速度是真的慢.
后面从本地加载,就会快很多.
2.SparkRunner
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=SparkRunner --inputFile=/home/zq/Desktop/test.txt
--output=counts" -Pspark-runner
3.FlinkRunner
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=FlinkRunner --inputFile=/home/zq/Desktop/test.txt
--output=counts" -Pflink-runner
以Flink为例,其他平台运行方式只是比直接运行多了指定–runner=FlinkRunner和-Pflink-runner
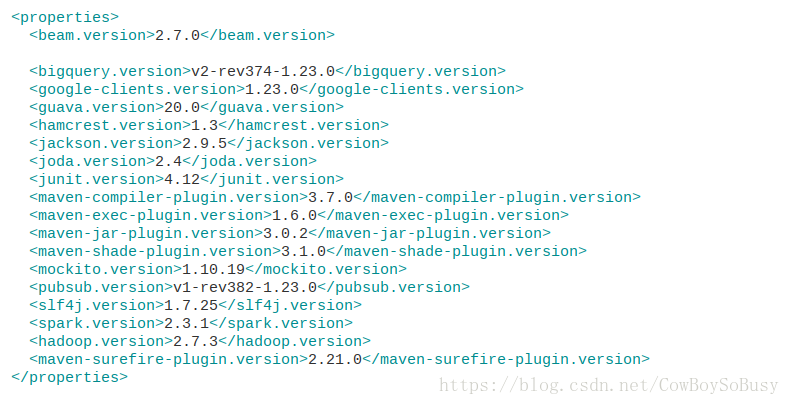
运行时如果你发现spark等的版本不是最新的,可以自己去pom.xml文件中做相应修改,再加载一次就行了
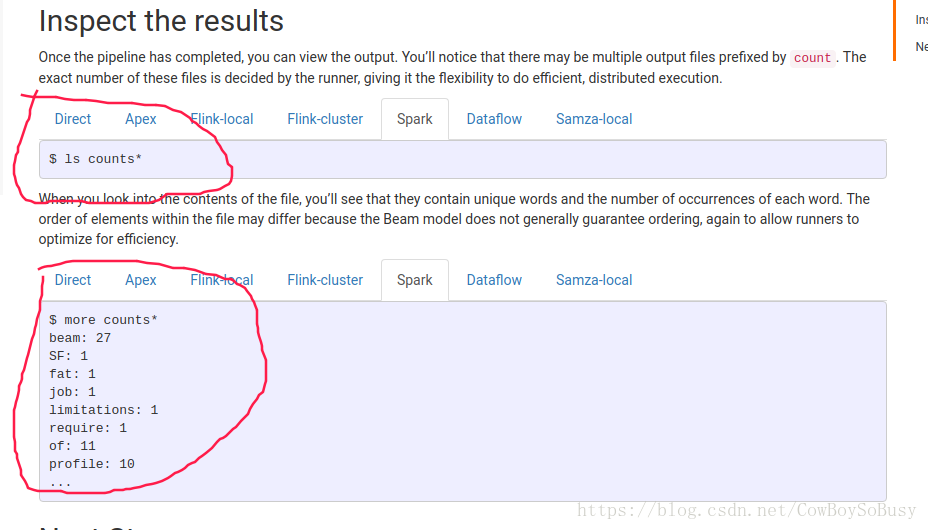
查看结果:
ls counts*
这样,同一份代码(WordCount.java)实现了在不同平台引擎Runner(Flink,Spark等等)上面的运行,并且效果是一样的.类似JVM对于java跨平台性的支持