版权声明:欢迎转载 https://blog.csdn.net/qq924862077/article/details/82994083
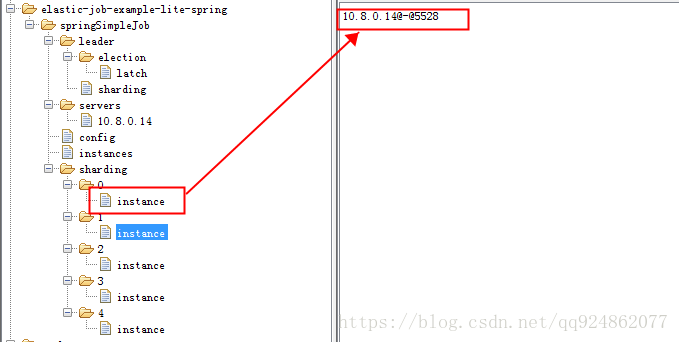
上一篇博客Elastic-Job原理--服务器初始化、节点选举与通知(二)介绍了Elastic-Job的启动流程,这篇博客我们了解学习一下Elastic-Job的任务分片策略,目前提供了三种任务分片策略,分片策略的实现最终是在注册中心zk中在分片的instance中写入实例信息。
目前Elastic-Job提供分片接口JobShardingStrategy:
/**
* 作业分片策略.
*
* @author zhangliang
*/
public interface JobShardingStrategy {
/**
* 作业分片.
*
* @param jobInstances 所有参与分片的单元列表
* @param jobName 作业名称
* @param shardingTotalCount 分片总数
* @return 分片结果
*/
Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount);
}目前有如下实现类:
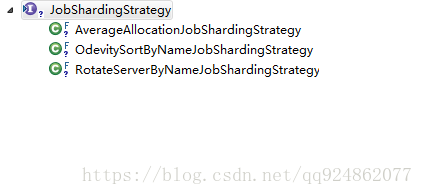
(1)AverageAllocationJobShardingStrategy:基于平均分配算法的分片策略.
如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
如:
1. 如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
2. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
3. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
/**
* 基于平均分配算法的分片策略.
*
* <p>
* 如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
* 如:
* 1. 如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
* 2. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
* 3. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
* </p>
*
* @author zhangliang
*/
public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy {
@Override
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
if (jobInstances.isEmpty()) {
return Collections.emptyMap();
}
Map<JobInstance, List<Integer>> result = shardingAliquot(jobInstances, shardingTotalCount);
addAliquant(jobInstances, shardingTotalCount, result);
return result;
}
//根据整除规则,将整除后的数据进行分配
private Map<JobInstance, List<Integer>> shardingAliquot(final List<JobInstance> shardingUnits, final int shardingTotalCount) {
Map<JobInstance, List<Integer>> result = new LinkedHashMap<>(shardingTotalCount, 1);
int itemCountPerSharding = shardingTotalCount / shardingUnits.size();
int count = 0;
for (JobInstance each : shardingUnits) {
List<Integer> shardingItems = new ArrayList<>(itemCountPerSharding + 1);
for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) {
shardingItems.add(i);
}
result.put(each, shardingItems);
count++;
}
return result;
}
//无法整除分片的数据,依次追加到实例中
private void addAliquant(final List<JobInstance> shardingUnits, final int shardingTotalCount, final Map<JobInstance, List<Integer>> shardingResults) {
int aliquant = shardingTotalCount % shardingUnits.size();
int count = 0;
for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) {
if (count < aliquant) {
entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count);
}
count++;
}
}
}(2)OdevitySortByNameJobShardingStrategy:根据作业名的哈希值奇偶数决定IP升降序算法的分片策略.
首先 作业名的哈希值为奇数则IP升序. 作业名的哈希值为偶数则IP降序.然后再调用AverageAllocationJobShardingStrategy的平均分片算法进行分片。
/**
* 根据作业名的哈希值奇偶数决定IP升降序算法的分片策略.
*
* <p>
* 作业名的哈希值为奇数则IP升序.
* 作业名的哈希值为偶数则IP降序.
* 用于不同的作业平均分配负载至不同的服务器.
* 如:
* 1. 如果有3台服务器, 分成2片, 作业名称的哈希值为奇数, 则每台服务器分到的分片是: 1=[0], 2=[1], 3=[].
* 2. 如果有3台服务器, 分成2片, 作业名称的哈希值为偶数, 则每台服务器分到的分片是: 3=[0], 2=[1], 1=[].
* </p>
*
* @author zhangliang
*/
public final class OdevitySortByNameJobShardingStrategy implements JobShardingStrategy {
private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy();
@Override
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
long jobNameHash = jobName.hashCode();
if (0 == jobNameHash % 2) {
Collections.reverse(jobInstances);
}
return averageAllocationJobShardingStrategy.sharding(jobInstances, jobName, shardingTotalCount);
}
}(3)RotateServerByNameJobShardingStrategy:根据作业名的哈希值对服务器列表进行轮转的分片策略.
/**
* 根据作业名的哈希值对服务器列表进行轮转的分片策略.
*
* @author weishubin
*/
public final class RotateServerByNameJobShardingStrategy implements JobShardingStrategy {
private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy();
@Override
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
return averageAllocationJobShardingStrategy.sharding(rotateServerList(jobInstances, jobName), jobName, shardingTotalCount);
}
private List<JobInstance> rotateServerList(final List<JobInstance> shardingUnits, final String jobName) {
int shardingUnitsSize = shardingUnits.size();
int offset = Math.abs(jobName.hashCode()) % shardingUnitsSize;
if (0 == offset) {
return shardingUnits;
}
List<JobInstance> result = new ArrayList<>(shardingUnitsSize);
for (int i = 0; i < shardingUnitsSize; i++) {
int index = (i + offset) % shardingUnitsSize;
result.add(shardingUnits.get(index));
}
return result;
}
}总结:总体上使用的还是平均分片算法,不过是将实例进行了不同的排序操作。