存储过程定义:
1.就是预先编译sql语句的集合
2.可以代替传统的逐条执行SQL语句的方式
3.可包含查询,插入,删除,更细等操作的一系列SQL语句
4.存储在sql server中
5.通过名称和参数执行
6.可带参数,也可返回结果
7.可包含数据操纵语句,变量,逻辑控制语句
存储过程的优点:
执行速度更快:因为存储过程在创建时就被编译,每次执行都不需要编译,而SQL语句的每一次执行都需要编译
允许模块化程序设计:存储过程一旦被创建,以后即可在程序中调用任意多次,这可以改进应用程序的可维护性,并允许应用程序统一访问数据库提高系统的安全性:存储过程在数据库中,用户只需提交存储过程名称就可以直接执行,避免了攻击者非法截取SQL代码获得用户数据的可能性
减少网络流通性:一个需要几百SQL语句代码的操作可以通过一条执行过的程序代码来执行,而不需要在网络中发送百行代码
重要的优点是:安全,执行速度快
存储过程的分类:
系统存储过程:用来管理SQLserver和显示有关数据库和用户信息的存储过程,sp_开头,存放在master的数据库中
扩展存储过程:使用其他编程语言创建外部存储过程,
并将这个存储过程在SQLserver作为存储过程来使用,xp_开头
自定义存储过程:用户在SQLserver中通过采用SQL语句
创建存储过程,通常以usp_开头(用的比较多)

存储过程的创建与调用:
不带参数的存储过程的创建与调用:
--常用的系统存储过程 use master go execute sp_databases exec sp_renamedb @dbname='Demo',@newname='myDemo' exec sp_renamedb 'myDemo','Demo' --查看Post表中的所有信息 use Demo go exec sp_help Post --常用的扩展存储过程: use master go exec sp_configure 'show advanced option',1 --能够启动xp_cmdshell高级配置 go reconfigure go exec sp_configure 'xp_cmdshell',1 --打开xp_cmdshell,可以调用SQLserver之外的系统命令 --使用xp_cmdshell 在D盘创建myFile的文件夹 exec xp_cmdshell 'mkdir d:\myFile',no_output --[no_output]是否输出返回信息 go --如果SQLserver版本高的话,执行xp_cmdshell这个扩展存储过程的时候会报以下的错误: --SQL Server 阻止了对组件 'xp_cmdshell' 的 过程 'sys.xp_cmdshell' 的访问, --因为此组件已作为此服务器安全配置的一部分而被关闭。 --系统管理员可以通过使用 sp_configure 启用 'xp_cmdshell'。 --有关启用 'xp_cmdshell' 的详细信息,请参阅 SQL Server 联机丛书中的 "外围应用配置器"。 --创建不带参数的存储过程: use E_Market go --题目: /* 查看xiangxiang所购买的商品信息,包括用户名,付款方式,购买数量,商品的名称 商品的类别 */ --检测是否存在要创建的存储过程,如果存在将其删除 if exists (select * from sysobjects where name='usp_GetCommodityInfo') drop proc usp_GetCommodityInfo go --删除之后要加go因为create proc 是批处理仅有的语句 create proc usp_GetCommodityInfo as select O.UserId as 用户号 ,payWay as 付款方式 ,O.Amount as 购买数量, C.CommodityName as 商品名称,S.SortName as 类别名称 from OrderInfo as O inner join CommodityInfo as C on O.CommodityId=C.CommodityId inner join CommoditySort as S on S.SortId=C.SortId where O.UserId='xiangxiang' go --存储过程的结束 --如何使用不带参数的存储过程 exec usp_GetCommodityInfo go

带输入参数的存储过程的创建与调用:
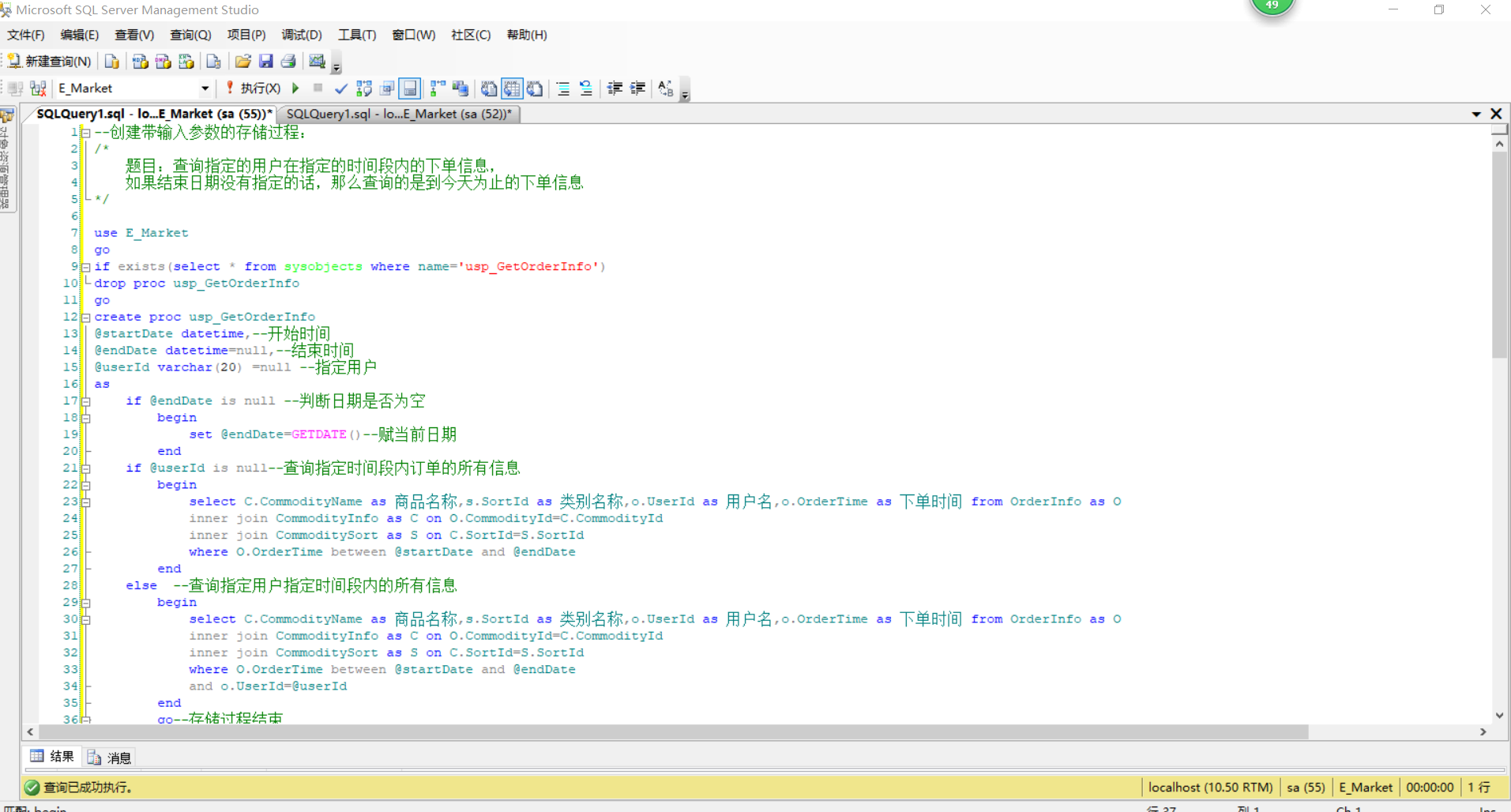
--创建带输入参数的存储过程: /* 题目:查询指定的用户在指定的时间段内的下单信息, 如果结束日期没有指定的话,那么查询的是到今天为止的下单信息 */ use E_Market go if exists(select * from sysobjects where name='usp_GetOrderInfo') drop proc usp_GetOrderInfo go create proc usp_GetOrderInfo @startDate datetime,--开始时间 @endDate datetime=null,--结束时间 @userId varchar(20) =null --指定用户 as if @endDate is null --判断日期是否为空 begin set @endDate=GETDATE()--赋当前日期 end if @userId is null--查询指定时间段内订单的所有信息 begin select C.CommodityName as 商品名称,s.SortId as 类别名称,o.UserId as 用户名,o.OrderTime as 下单时间 from OrderInfo as O inner join CommodityInfo as C on O.CommodityId=C.CommodityId inner join CommoditySort as S on C.SortId=S.SortId where O.OrderTime between @startDate and @endDate end else --查询指定用户指定时间段内的所有信息 begin select C.CommodityName as 商品名称,s.SortId as 类别名称,o.UserId as 用户名,o.OrderTime as 下单时间 from OrderInfo as O inner join CommodityInfo as C on O.CommodityId=C.CommodityId inner join CommoditySort as S on C.SortId=S.SortId where O.OrderTime between @startDate and @endDate and o.UserId=@userId end go--存储过程结束 --如何调用带参数的存储过程 --1)结束日期与用户都使用默认值 --指定了开始时间,查询的是从开始时间到今天的所有订单信息 exec usp_GetOrderInfo '2018-05-02' --2.结束日期不为空,从开始时间到结束时间的所有信息 --隐式调用,参数顺序必须与创建存储过程的参数顺序完全相同 exec usp_GetOrderInfo '2018-05-02','2018-05-10','xiangxiang' --3.显示调用,对参数顺序无要求,但是如果有参数中一个写了@名称=值的形式, --之后的参数都必须写成@名称=值,默认值可以使用default代替 exec usp_GetOrderInfo @UserId ='xiangxiang',@startDate='2018-05-02', @endDate=default --显示调用时的@userId,@startDate,@endDate是存储过程定义时的参数 --要和上面声明的参数相同 --4.可以通过声明变量来调用 declare @d1 datetime,@d2 datetime,@uid varchar(20) set @d1='2018-05-02' set @d2='2018-05-19' set @uid='xiangxiang' exec usp_GetOrderInfo @d1,@d2,@uid --除了显示调用之外,要求参数位置必须与存储过程定义时的顺序相同

带输出参数的存储过程的创建与调用:
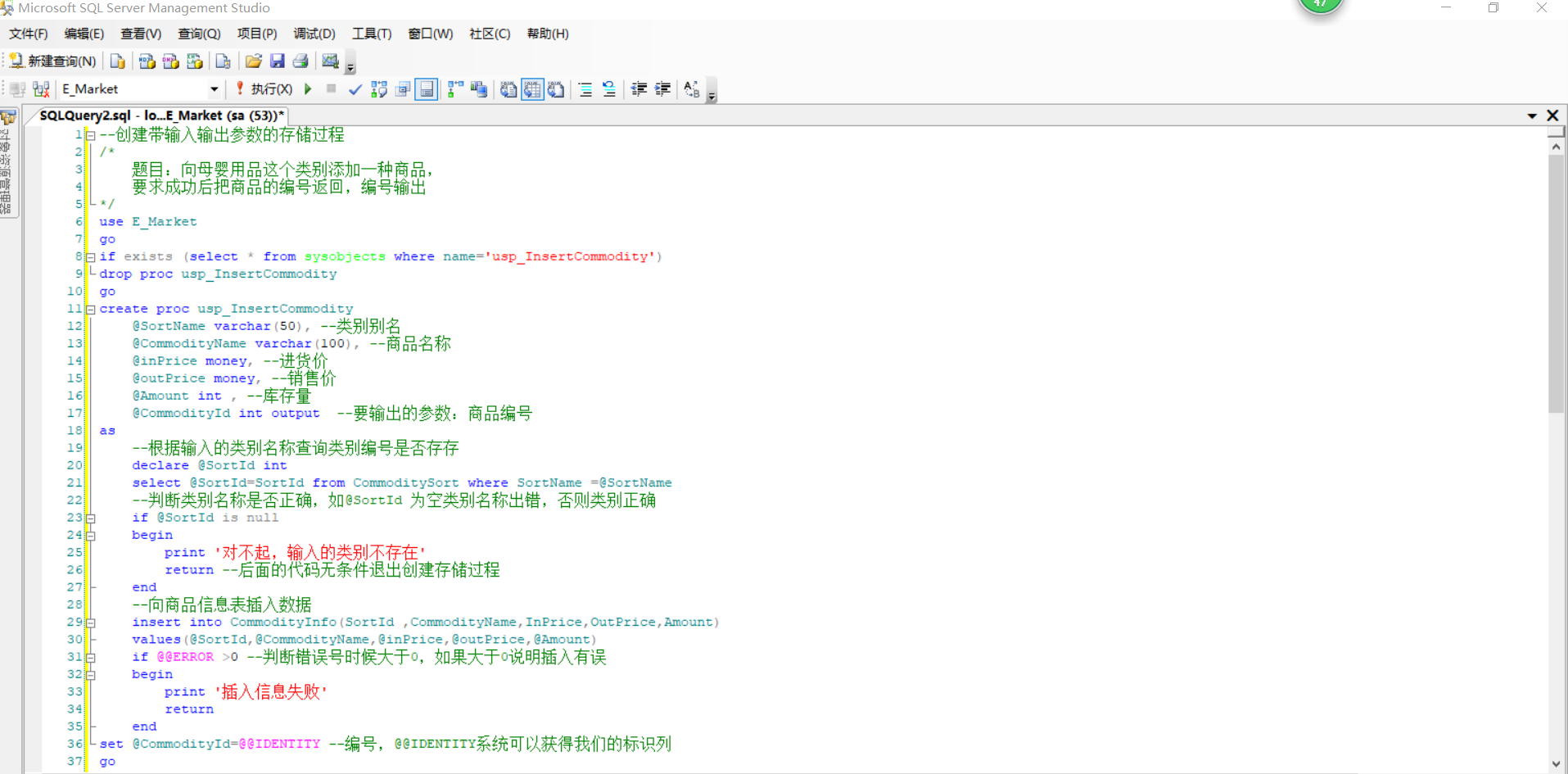
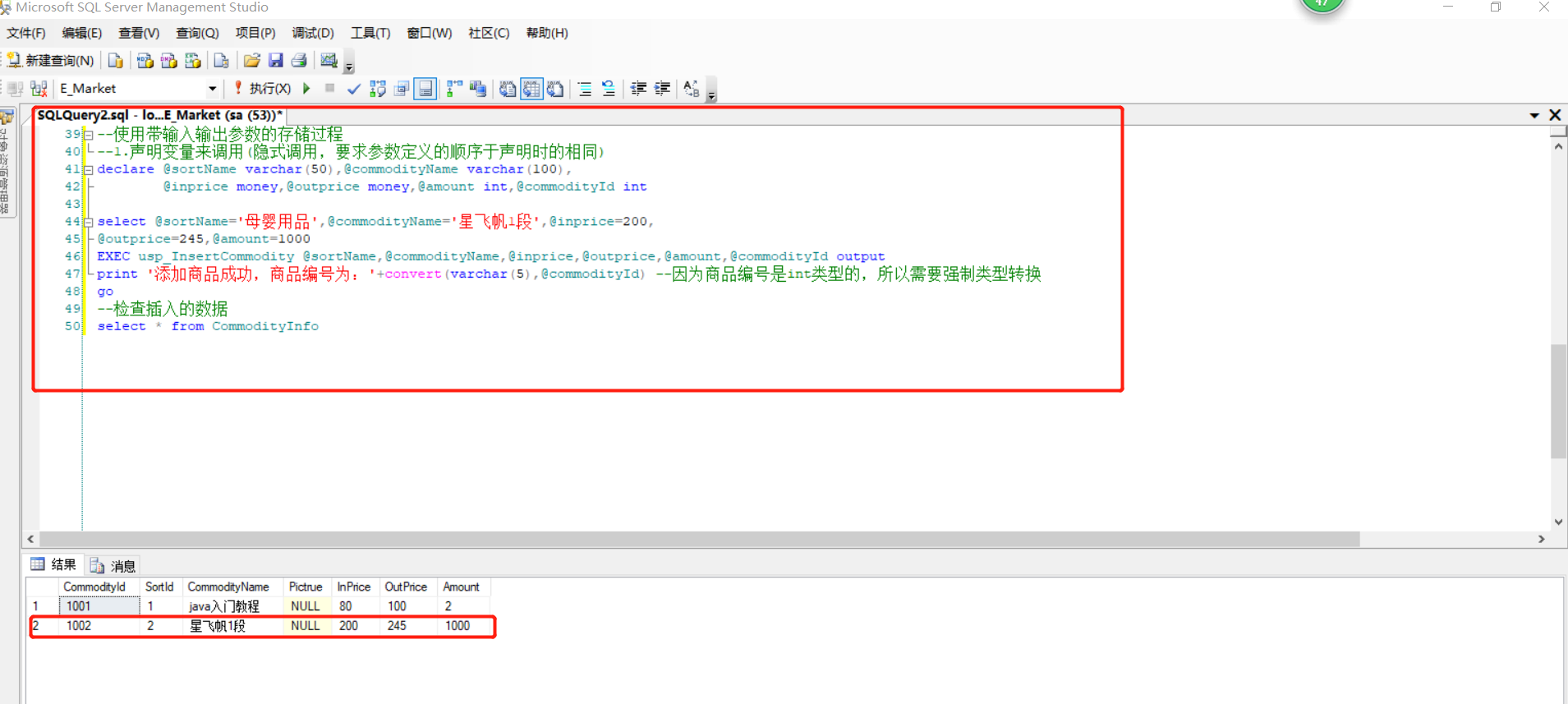
--创建带输入输出参数的存储过程 /* 题目:向母婴用品这个类别添加一种商品, 要求成功后把商品的编号返回,编号输出 */ use E_Market go if exists (select * from sysobjects where name='usp_InsertCommodity') drop proc usp_InsertCommodity go create proc usp_InsertCommodity @SortName varchar(50), --类别别名 @CommodityName varchar(100), --商品名称 @inPrice money, --进货价 @outPrice money, --销售价 @Amount int , --库存量 @CommodityId int output --要输出的参数:商品编号 as --根据输入的类别名称查询类别编号是否存存 declare @SortId int select @SortId=SortId from CommoditySort where SortName =@SortName --判断类别名称是否正确,如@SortId 为空类别名称出错,否则类别正确 if @SortId is null begin print '对不起,输入的类别不存在' return --后面的代码无条件退出创建存储过程 end --向商品信息表插入数据 insert into CommodityInfo(SortId ,CommodityName,InPrice,OutPrice,Amount) values(@SortId,@CommodityName,@inPrice,@outPrice,@Amount) if @@ERROR >0 --判断错误号时候大于0,如果大于0说明插入有误 begin print '插入信息失败' return end set @CommodityId=@@IDENTITY --编号,@@IDENTITY系统可以获得我们的标识列 go --使用带输入输出参数的存储过程 --1.声明变量来调用(隐式调用,要求参数定义的顺序于声明时的相同) declare @sortName varchar(50),@commodityName varchar(100), @inprice money,@outprice money,@amount int,@commodityId int select @sortName='母婴用品',@commodityName='星飞帆1段',@inprice=200, @outprice=245,@amount=1000 EXEC usp_InsertCommodity @sortName,@commodityName,@inprice,@outprice,@amount,@commodityId output print '添加商品成功,商品编号为:'+convert(varchar(5),@commodityId) --因为商品编号是int类型的,所以需要强制类型转换 go --检查插入的数据 select * from CommodityInfo
带返回值的存储过程的创建与调用:
use E_Market--创建带返回值的一个存储过程 go /* 向母婴用品中添加一条商品信息 */ use E_Market go if exists(select * from sysobjects where name='usp_insertCommodityReturn') drop proc usp_insertCommodityReturn go create proc usp_insertCommodityReturn @sortName varchar(50), @commodityName varchar(100), @inPrice money, @outPrice money, @amount int--@commodityId int output as declare @sortid int select @sortid=SortId from CommoditySort where SortName=@sortName --根据输入的名称查看类别编号是否存在 if @sortid is null begin return -1 --用-1代表类别名不正确 end --向商品信息表添加一条商品信息 insert into CommodityInfo(SortId,CommodityName,InPrice,OutPrice,Amount) values(@sortid,@commodityName,@inPrice,@outPrice,@amount) if @@ERROR >0 begin return 0 --用0来代表插入信息失败 end else begin return @@IDENTITY end go --来使用带返回的存储过程,返回值有三个,0,-1 ,商品的编号 --使用显示调用 declare @Result int -- 接受存储过程的返回值 exec @Result=usp_insertCommodityReturn @sortName='会变美食',@commodityName='好吃点', @inprice=3.5,@outprice=7.6 ,@amount=100 if @Result =-1 begin print '对不起,输入的类别名称不存在' end else if @Result=0 begin print '插入的信息失败' end else begin print'添加商品成功,商品编号为'+convert(varchar(5),@Result) end go


最后是介绍创建和调用存储过程的一些注意事项:
创建存储过程的注意事项:
1.有默认值的参数要写在最后
2.存储过程创建结束,必须加批处理的go 否则的话会造成递归调用
调用存储过程的注意事项:
1.不写参数名,必须与定义的时候的参数顺序相同
2.不按照顺序,必须写上参数名
3.如果有一个写为“@名称=值”的形式,那么后面的所有参数都要这样写
4.如果调用存储过程的批处理中的第一句话,也就是go exec 存储过程名称这样的格式可以不写exec,也就是
go 存储过程名称