摘要: 原来本来是测试的服务器做了hadoop,然后上线了,然后磁盘要满了,不想加机器,就把磁盘扩容一下。 这也就是所谓的纵向扩展了吧。
一、扩容本地磁盘并挂载
机器都是阿里云的服务器,需要现在阿里云购买磁盘。然后挂载到服务器上,可以参考:
https://help.aliyun.com/knowledge_detail/5974196.html
1、把新加的磁盘挂载到了/hdfs_data
2、原来默认的hdfs的数据目录为/usr/local/hadoop/hdfs/data/
<name>dfs.datanode.data.dir</name>
<value>二、停止Datanode
我这里有三台datanode,数量比较小,所以就一台一台的做操作了。
如果是小环境,就一台一台的Datanode操作,这样能保证数据不会丢,因为有3个副本,所以,即使停掉一台Datanode也没有问题,不影响使用。
注意:以下操作逐一在需要扩容的datanode服务器上都执行。
1、暴力停止(kill),因为./hadoop-daemon.sh stop datanode 不能停。
kill `ps -ef | grep datanode | grep -v grep | awk '{print $2}'`2、迁移数据
mv /usr/local/hadoop/hdfs/data/current /hdfs_data/3、修改hadoop配置文件
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
把:
<name>dfs.datanode.data.dir</name>
<value>
改成:
<name>dfs.datanode.data.dir</name>
<value>file:///hdfs_data</value>三、启动Datanode
逐一在Datanode服务器上执行:
/usr/local/hadoop/sbin/hadoop-daemon.sh start datanode检测datanode是否正常启动:
ps -ef | grep datanode | grep -v grep四、平衡数据
逐一在Datanode服务器上执行:
/usr/local/hadoop/sbin/start-balancer.sh五、测试Datanode是否扩容成功
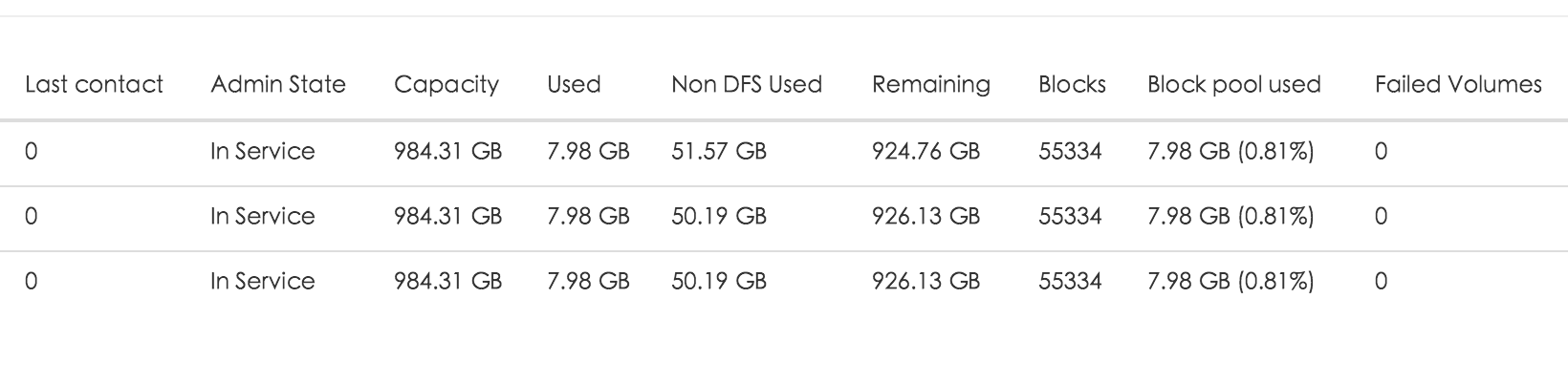
或者,通过hdfs dfsadmin -report 命令进行查看。
然后测试各种读写操作。
最后上个图:
© 著作权归作者所有