一、引言
ConcurrentHashMap是Java并发工具包中的Map实现类,它支持多个线程并发操作Map。可以说,ConcurrentHashMap就是支持并发操作的HashMap。和HashMap不同的是,ConcurrentHashMap不支持添加键或值为null的键值对。
ConcurrentHashMap继承关系及其内部类继承关系图(红色部分为内部类):
ConcurrentHashMap继承了AbstractMap类,实现了ConcurrentMap接口。
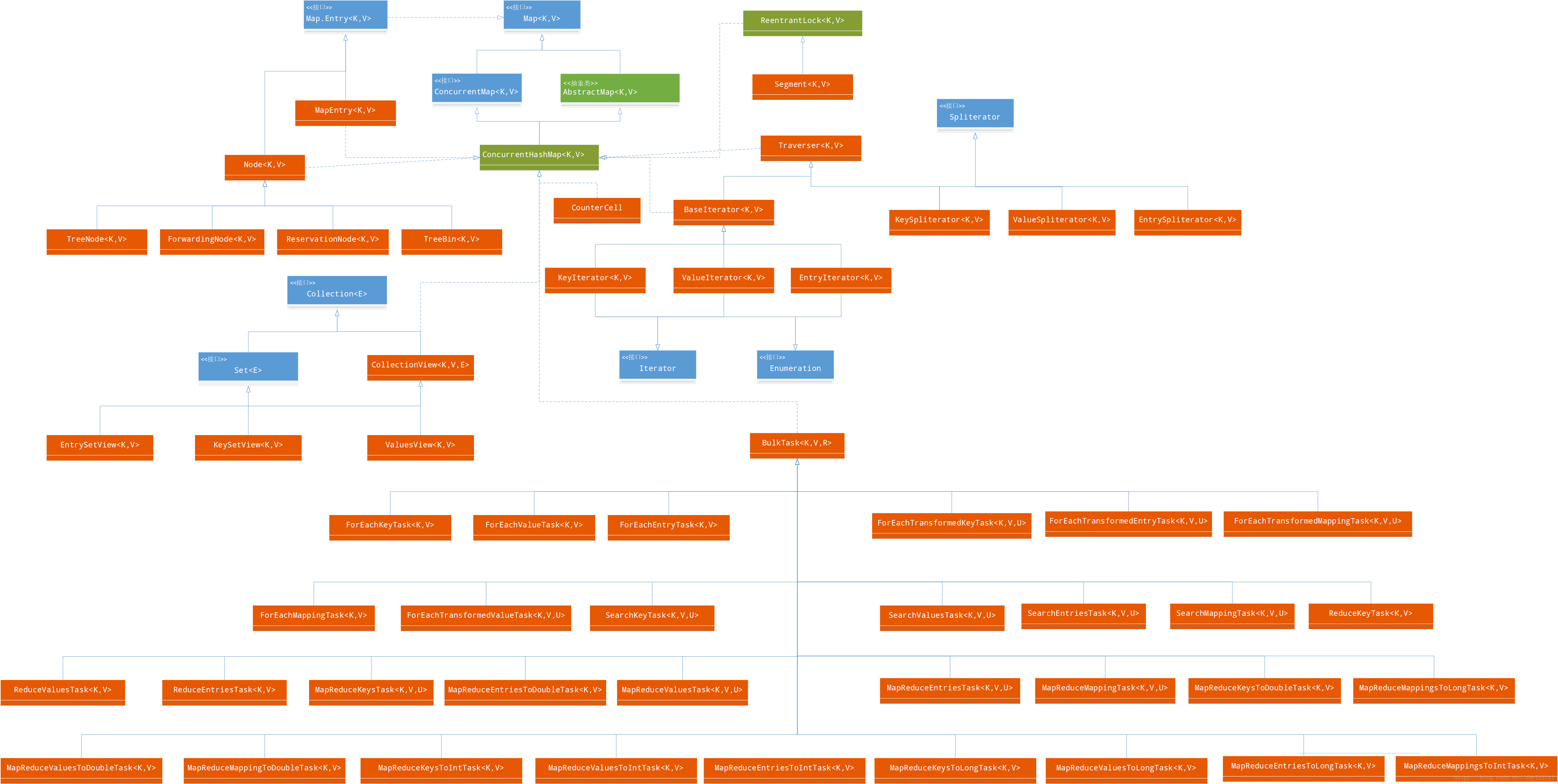
由于ConcurrentHashMap的源码较为复杂,总代码量达到了6300行,所以只讨论以下几个重点:
1、ConcurrentHashMap的存储结构以及Node及其子类
2、ConcurrentHashMap的putVal、remove方法及其键值对的迭代
3、ConcurrentHashMap的扩容策略
二、源码分析
1、静态变量、静态常量
ConcurrentHashMap定义了以下静态变量和常量:
| 常量名 | 类型及值 | 作用 |
|---|---|---|
| MAXIMUM_CAPACITY | (int) 1 << 30 | 最大的桶数组(table)长度 |
| DEFAULT_CAPACITY | (int) 16 | 默认的桶数组(table)长度 |
| MAX_ARRAY_SIZE | (int) Integer.MAX_VALUE - 8 | 最大的数组大小(用于toArray方法) |
| DEFAULT_CONCURRENCY_LEVEL | (int) 16 | 默认的并发级别(并发级别即预计有多少线程对这个Map进行并发操作) |
| LOAD_FACTORY | (float) 0.75f | 默认的负载因子 |
| TREEIFY_THRESHOLD | (int) 8 | 当一个桶中的键值对大于这个数时,会转换为红黑树结构存储 |
| UNTREEIFY_THRESHOLD | (int) 6 | 当一个桶中的键值对小于这个数时,会由之前的红黑树结构转换为链表结构 |
| MIN_TREEIFY_CAPACITY | (int) 64 | 一个桶转换为红黑树时需要的最小桶长度,如果没有达到这个值则不会转换为红黑树 |
| MIN_TRANSFER_STRIDE | (int) 16 | 扩容操作进行桶的迁移时,每个线程(每次处理)最小的桶数组处理数量 |
| RESIZE_STAMP_BITS | (int) 16 | 扩容操作位移量 |
| MAX_RESIZERS | (int) 1 << 16 - 1 | 进行扩容操作的最大线程并发数 |
| RESIZE_STAMP_SHIFT | (int) 16 | 位移量,用来计算校验值 |
| MOVED | (int) -1 | 用于键值对Node的hash变量,此值表示这个桶正在进行扩容 |
| TREEBIN | (int) -2 | 表示这个桶的结构是红黑树 |
| RESERVED | (int) -3 | 表示这个桶正在执行compute或computeIfAbsent方法 |
| HASH_BITS | (int) 0x7FFFFFFF | 用于计算键的哈希值,保证哈希值为正数 |
| NCPU | 通过Runtime类方法获得 | 当前运行机器的CPU核心数量 |
除此之外,还有:
//序列化类缓存
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
2、实例变量
//桶数组
transient volatile Node<K,V>[] table;
//用于缓存扩容后的数组
private transient volatile Node<K,V>[] nextTable;
//键值对数量预计值
private transient volatile long baseCount;
//扩容状态或者阈值
private transient volatile int sizeCtl;
//扩容操作剩余的数组长度,用于给扩容线程分配待处理的桶数组
private transient volatile int transferIndex;
//counterCells的状态,值为0或1
private transient volatile int cellsBusy;
//键值对数量临时计数器
private transient volatile CounterCell[] counterCells;
//键迭代器对象缓存
private transient KeySetView<K,V> keySet;
//值迭代器对象缓存
private transient ValuesView<K,V> values;
//键值对迭代器缓存
private transient EntrySetView<K,V> entrySet;
sizeCtl可以用来表示ConcurrentHashMap的扩容状态和阈值,它默认为0,其数值有以下含义:
-1 :代表table正在初始化
-N: 表示正有N-1个线程执行扩容操作
0:尚未初始化。
>0:相当于HashMap中的threshold,表示阈值,即键值对达到了这个数,那么会启动桶数组的扩容。
3、构造方法
ConcurrentHashMap提供了5个public构造方法:
| 构造方法签名 | 解释 |
|---|---|
| ConcurrentHashMap() | 构造一个初始桶大小为16的Map |
| ConcurrentHashMap(int) | 构造一个指定大小的Map(如果int参数不为2的幂次,那么取一个最近的2幂次数) |
| ConcurrentHashMap(Map<? extends K, ? extends V>) | 构造一个Map,其初始元素为传入的Map中所有的元素 |
| ConcurrentHashMap(int, float) | 构造一个指定桶大小、指定负载因子的Map |
| ConcurrentHashMap(int, float, int) | 构造一个指定桶大小、指定负载因子、指定并发级别的Map |
下面来看这些构造方法的源代码:
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
//保证桶的长度为2的幂次并且没有超出最大值
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//如果桶长度小于并发级别,那么将并发级别作为桶长度
if (initialCapacity < concurrencyLevel)
initialCapacity = concurrencyLevel;
//设置桶长度
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
//保证是2的幂次并且大小合法
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
4、ConcurrentHashMap的Map.Entry实现类:Node
和HashMap一样,ConcurrentHashMap通过Node对象来存放一个键值对:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //键的哈希值,这里不一定等于key.hashCode()
final K key; //键引用,不可变
volatile V val; //值引用
volatile Node<K,V> next; //下一个键值对,用于维持桶中的链表结构
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
//键值对的hashCode,并非键的hashCode
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) { throw new UnsupportedOperationException(); }
//在这个链表中查找Node,h为键的哈希值,
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
//遍历链表
do {
K ek;
//如果哈希值相同,那么判断key是否为一个对象或者equals方法是否返回true,条件满足后返回这个Node
if (e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
//通过判断键和值是否为同一个对象或者通过equals方法来确定是否返回true
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) && (k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null && (k == key || k.equals(key)) && (v == (u = val) || v.equals(u)));
}
}
虽然Node的setValue方法的实现是抛出UnsupportedOperationException,但是下面的代码却不会抛出异常:
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
map.put("haha","1");
for(Map.Entry<String, String> entry : map.entrySet()) {
entry.setValue("123");
}
为什么呢?因为这里的entry并不是Node。我们先从entrySet方法开始:
public Set<Map.Entry<K,V>> entrySet() {
EntrySetView<K,V> es;
return (es = entrySet) != null ? es : (entrySet = new EntrySetView<K,V>(this));
}
该方法首先判断entrySet缓存是否为null,如果为null则构造一个EntrySetView并赋给变量entrySet,然后返回。如果不为null则直接返回缓存中的EntrySetView。
EntrySetView是ConcurrentHashMap的一个静态内部类,它继承了静态内部类CollectionView,并实现了Set接口:
static final class EntrySetView<K,V> extends CollectionView<K,V,Map.Entry<K,V>>
implements Set<Map.Entry<K,V>>, java.io.Serializable {
EntrySetView(ConcurrentHashMap<K,V> map) { super(map); }
public Iterator<Map.Entry<K,V>> iterator() {
ConcurrentHashMap<K,V> m = map;
Node<K,V>[] t;
int f = (t = m.table) == null ? 0 : t.length;
return new EntryIterator<K,V>(t, f, 0, f, m);
}
//省略其它方法......
}
EntryViewSet只有一个实例变量:当前ConcurrentHashMap的this引用,对这个集合的添加等操作实际上都会调用到外部类的方法。
EntrySetView的iterator方法会返回一个EntryIterator:
static final class EntryIterator<K,V> extends BaseIterator<K,V> implements Iterator<Map.Entry<K,V>> {
EntryIterator(Node<K,V>[] tab, int index, int size, int limit, ConcurrentHashMap<K,V> map) {
super(tab, index, size, limit, map);
}
public final Map.Entry<K,V> next() {
Node<K,V> p;
//获取next变量
if ((p = next) == null)
throw new NoSuchElementException();
K k = p.key;
V v = p.val;
lastReturned = p;
advance();
//构造一个MapEntry结点返回,这个结点的源码已经分析过了
return new MapEntry<K,V>(k, v, map);
}
}
可以看出,当尝试对键值对进行迭代时,实际上返回的是MapEntry累,它同样实现了Map.Entry接口,它在ConcurrentHashMap中的作用是为了键值对的迭代,每调用一次迭代器的next方法,就会根据原来的Node构造一个MapEntry对象。
static final class MapEntry<K,V> implements Map.Entry<K,V> {
final K key;
V val;
final ConcurrentHashMap<K,V> map;
MapEntry(K key, V val, ConcurrentHashMap<K,V> map) {
this.key = key;
this.val = val;
this.map = map;
}
public V setValue(V value) {
if (value == null) throw new NullPointerException();
V v = val;
val = value;
map.put(key, value);
return v;
}
//省略其它方法...
}
从上述代码可以看出,当通过迭代器遍历Map的键值对时,调用的方法其实是MapEntry的方法而不是Node的方法。至于setValue方法,则相当于是重新构造一个Node,再将原来的那个键值对覆盖掉。
上述的Node只能用来维持一个链表,当桶的长度大于64并且一个桶中的键值对数量超过8时,就会将其转换成红黑树,红黑树的结点实现类是Node的子类:TreeBin和TreeNode,前者用于维持红黑树的根节点,后者则是单个红黑树的结点。这里就不详细介绍红黑树的结点实现了。
5、键值对的添加操作
ConcurrentHashMap提供了很多插入元素的方法:put、putAll等,但这些方法实际上都离不开一个内部方法:putVal方法
putVal方法需要提供三个参数:需要插入的键引用key,值引用value,以及当这个键存在时是否不替换这个键值对的值。
final V putVal(K key, V value, boolean onlyIfAbsent) {
//不允许插入键或值为null的元素,和HashMap不一样
if (key == null || value == null) throw new NullPointerException();
//计算出键的hash值
int hash = spread(key.hashCode());
//记录目标桶的键值对数量
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果桶数组尚未初始化,那么调用initTable初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//调用tabAt方法定位桶,并且如果这个桶为空,那么通过CAS操作将元素插入到桶中,操作成功则跳出循环
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
//如果这个桶的状态为MOVED,则代表有其它线程进行扩容操作,调用helpTransfer方法一起扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//到这一步说明发生了哈希冲突,并且没有进行扩容
else {
V oldVal = null;
//对这个桶加锁
synchronized (f) {
//检查这个桶的一个键值对是否依然是f
if (tabAt(tab, i) == f) {
//如果这个桶是链表实现的
if (fh >= 0) {
binCount = 1;
//遍历这个桶
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果参数key和这个键值对的键相同
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
//根据参数onlyIfAbsent决定是否替换这个值
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//如果已经遍历完这个桶的所有键值对,那么构造一个新的Node并插入到桶的尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
//如果这个桶中的键值对是通过红黑树存储的
} else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//调用红黑树的putTreeVal方法添加键值对,如果没有找到键相同的键值对,则默认添加新的键值对并返回null
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//最后检查这个桶的键值对数量
if (binCount != 0) {
//r如果桶中键值对超过8,那么转换成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//当定位的桶为空,添加完键值对的后续操作
addCount(1L, binCount);
return null;
}
putVal的执行步骤可以总结如下:
1、首先计算出新键值对key的哈希码,这里首先会调用key的hashCode方法然后调用内部静态方法spread:
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
上述计算哈希码的策略和HashMap相同:将哈希码的高16为和低16为进行异或运算,然后转换为正数。
2、然后,调用线程会进入一个自旋操作,首先会检查桶数组是否初始化,如果尚未初始化,则调用initTable方法进行初始化:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//成功分配数组后结束循环
while ((tab = table) == null || tab.length == 0) {
//如果有其它线程正在初始化,那么进行让步
if ((sc = sizeCtl) < 0)
Thread.yield();
//通过CAS操作将ctl值改为-1,表示当前线程正在初始化
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//如果已经有其它线程初始化了,那么跳出循环
if ((tab = table) == null || tab.length == 0) {
//如果sc大于0,那么本次扩容到sc长度,否则构造一个长度为16的桶数组
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
//构造数组并赋给实例变量table
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//将sizeCtl的值设为n-n/4
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
initTable方法同样会让一个线程进入自旋操作,不断尝试通过CAS操作将sizeCtl设为-1,保证此时只有一个线程进行初始化操作。如果有其它线程已经初始化了数组,那么当前线程不会再进行初始化操作。
CAS操作是通过sun.misc.Unsafe的compareAndSwapInt方法实现的,这个方法是一个native方法,由C++通过调用原子汇编指令来完成CAS。
3、初始化数组完毕后,就会开始根据键的哈希值和桶的大小定位桶的位置:(n-1)&hash(当n为2的幂次时,(n-1)&hash = hash % n),然后调用静态方法tabAt获取桶的第一个键值对:
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
tabAt方法同样是调用Unsafe的本地方法来获取最新值。
如果tabAt方法返回的是null,说明这个桶为空,随后,putVal方法将会构造一个新的键值对并调用casTabAt方法将这个键值对添加到桶中:
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
通过CAS操作,保证只有一个线程能够成功地将键值对直接放入桶中。如果方法返回true,说明当前线程成功将键值对放入桶中,随后就会跳出循环。如果该方法返回false,则说明有其它线程已经抢先将其它键值对加入到桶中,只能重新开始循环再次尝试添加键值对。
4、如果发现定位到的桶不为空,那么会检查这个桶的成员变量hash,如果hash等于MOVED(-1),则表明有其它线程正在进行扩容操作,那么当前线程就会调用helpTransfer方法帮助其它线程完成扩容操作:
其中,参数tab为桶数组,f为一个桶的第一个键值对
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
//如果f是ForwardingNode并且这个f的nextTable不为null
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
//返回一个长度为16位的扩容校验标识
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//将sizeCtl的值加1,并调用transfer方法参与扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
transfer方法的具体实现原理我们稍作分析。
5、如果这个桶不为空并且没有线程正在扩容,那么会将这个桶加上锁。然后,会再次检验这个桶的第一个键值对有没有发生改变,如果被其它线程修改了,那么重新开始循环。如果一切正常,那么会判断这个桶中的键值对是通过链表维持的还是通过红黑树维持的。
如果是通过链表维持的,那么会通过一个循环遍历链表来查找有没有键相同的键值对。如果存在这样一个键值对那么会根据onlyIfAbsent策略来决定是否替换这个键值对的值,随后就会跳出循环。
如果是通过红黑树维持的,那么会调用TreeBin的putTreeVal加入结点。
6、添加完键值对后,如果原来这个桶不为空,putVal方法会检查这个桶的键值对数量,如果键值对数量超过了8那么会调用treeifyBin将链表结构转换成红黑树结构:
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//如果桶数组长度小于64,那么尝试调用tryPersize方法尝试扩容到原来的2倍
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
//如果这个桶现在不为null并且状态正常,那么对这个桶加锁
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
//遍历链表
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
//构造一个TreeBin并放在这个桶中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
treeifyBin方法结束后,随即返回旧值结束putVal方法。
7、如果原来的桶存在键值对,那么会调用addCount方法修改键值对数量计数器并且会检查负载系数:
//参数x为键值对计数器的增加值,对于check,如果check小于0,那么不会检查是否需要对桶数组进行扩容
private final void addCount(long x, int check) {
CounterCell[] as;
long b, s;
//如果counterCells不为null或者尝试通过CAS将键值对计数器更改为baseCount+x时失败
if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
//counterCells为null或者元素数量为1,或者随机获取一个counterCells中的元素为null,
//或者没有成功地将获取到的CounterCell的值改为v+x,满足上述条件则调用fullAddCount并返回
if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
//计算出键值对数量
s = sumCount();
}
//如果需要检查扩容
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//如果s大于sizeCtl,则说明需要扩容
while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
//如果有其它线程正在进行扩容
if (sc < 0) {
//判断扩容操作进行状态
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0)
break;
//通过CAS将sizeCtl的值加1,调用transfer方法扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//如果没有其它线程扩容,那么重设sizeCtl的值,成功后调用transfer方法扩容
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
//重新计算键值对数量
s = sumCount();
}
}
}
addCount方法执行步骤如下:
(1)首先如果counterCells不为null,或者通过CAS将baseCount增加x时失败,那么会调用一系列方法获取键值对数量的预计值。
(2)如果check大于等于0,即需要检查是否需要扩容。方法首先会判断键值对预计值是否大于sizeCtl,如果满足那么首先判断是否有其它线程扩容,如果有其它线程扩容(nextTable不为空),那么会调用tansfer方法传入table和nextTable帮助其它线程一起扩容,否则调用transfer方法不传入nextTable,由当前线程构造新的数组。
transfer方法如下:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//扩容操作时,一个线程负责处理的数组长度,最小值为16。
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
//检查是否需要构造新的数组
if (nextTab == null) {
try {
//构造一个原桶数组长度2倍的数组,并将它赋给变量nextTab
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
//如果有异常发生,说明数组长度过大,那么将sizeCtl设为Integer.MAX_VALUE
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
//将新数组赋给成员变量nextTable,原数组长度赋给transferIndex
nextTable = nextTab;
transferIndex = n;
}
//从这里开始,transfer方法主要任务是完成旧数组到新数组的迁移
int nextn = nextTab.length;
//构造一个ForwardingNode,成员变量hash为MOVED(-1),保存了新数组的引用
//在处理完一个桶后,这个桶的第一个元素为fwd,代表已经处理完成
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true; //是否需要重新设置本次操作桶的位置
boolean finishing = false; //扩容操作是否完成
//i为本次循环操作的桶数组下标,bound为临界下标(i达到bound后不再处理桶)
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//将i的值减1,并判断有没有跃过bound
if (--i >= bound || finishing)
advance = false;
//如果transferIndex小于等于0,那么退出这个循环
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//如果扩容操作依然没有完成,那么重新设置bounds,首先尝试将transferIndex减去stride,成功后退出循环
else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
//如果i作为数组下标已经越界
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//如果扩容操作已完成,那么清除nextTable变量,并将新数组赋给table,更新sizeCtl的值
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//将sizeCtl值减1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//如果还有线程进行扩容操作,则方法直接返回
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//扩容操作完成
finishing = advance = true;
i = n;
}
}
//如果桶数组位置i上为空,那么将fwd添加在这个桶上,重新设置数组范围
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//如果这个桶的第一个元素为ForwardingNode类型,那么重新设置数组范围
else if ((fh = f.hash) == MOVED)
advance = true;
//如果这个桶包含键值对
else {
//对这个桶加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//如果是链表实现的,那么拆分为两个链表ln和hn(这里和HashMap的策略一样,不详细讨论具体实现了)
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
} else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//将拆分后的链表设置到桶中
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
//重新设置数组范围
advance = true;
//如果是红黑树实现的,那么同样将这个红黑树拆分为两个
} else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
//重新设置数组范围
advance = true;
}
}
}
}
}
}
代码虽然看起来长,但实际并不复杂。transfer方法首先会根据运行机器的CPU数量来算出每个线程应当处理的桶的数量stride。然后,如果传入的nextTab参数为null,那么当前线程会自己构造一个原来大小2倍的桶数组并赋给成员变量nextTable,以确保别的线程能够访问到,数组构造完成后,方法会将原来的桶数组长度赋给成员变量transferIndex,表示待处理的桶。
操作完成后,进入一个循环操作:
循环开头会检查i和bounds变量,如果这些变量尚未初始化(都为0),那么方法会将bounds设为transferIndex减去stride,表示原数组bounds~i上的桶由我来处理,每处理一个桶,都会将i减去1来处理下一个桶,直到处理到bounds。在处理过程中,如果有其它线程也想来参与扩容,那么就会根据transferIndex给这个线程分配另外一个区域的桶进行同样的处理。
如果处理到bounds后,当前线程如果发现扩容操作依然没有完成,那么这个线程会尝试再次根据transferIndex处理下一个区域的桶。
下面这幅流程图以一个长度为8的table,其nextTable长度为16来演示这一过程(stride实际上至少为16,为了演示方便我们取stride为4进行演示):
上面也提到过,如果没有第二个线程来参加任务,那么第一个线程在完成自己的扩容任务后并不会立刻结束,它会去完成第二个线程所需要完成的任务,直到扩容完成为止。
这样设计可以达到一种非常高效的扩容操作且不会产生线程安全问题。

8、addCount方法执行完成后,方法返回null,随即结束。
6、键值对的移除
理解了putVal方法后,再来看remove方法就比较简单了:
final V replaceNode(Object key, V value, Object cv) {
//计算键的哈希值
int hash = spread(key.hashCode());
//进入自旋操作
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果定位到的桶为空那么退出循环返回null
if (tab == null || (n = tab.length) == 0 || (f = tabAt(tab, i = (n - 1) & hash)) == null)
break;
//如果这个桶的第一个元素hash变量为MOVED,则代表有线程正在为这个桶进行迁移操作,调用helpTransfer方法帮助迁移
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
//对这个桶加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
//如果这个桶的结构是链表
if (fh >= 0) {
validated = true;
//遍历链表
for (Node<K,V> e = f, pred = null;;) {
K ek;
//将这个键值对的键进行比对
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
V ev = e.val;
if (cv == null || cv == ev || (ev != null && cv.equals(ev))) {
oldVal = ev;
if (value != null)
e.val = value;
else if (pred != null)
pred.next = e.next;
else
setTabAt(tab, i, e.next);
}
break;
}
pred = e;
//没有找到符合的键值对
if ((e = e.next) == null)
break;
}
}
//如果这个桶的结构是红黑树
else if (f instanceof TreeBin) {
validated = true;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null && (p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
if (cv == null || cv == pv || (pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null)
p.val = value;
else if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
if (validated) {
if (oldVal != null) {
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}
键值对移除步骤比较简单,和putVal方法的逻辑类似,这里就不再赘述了。