InfuxDB学习文档 https://xtutu.gitbooks.io/influxdb-handbook/content/
默认端口:8086
web访问端口:8083 http://localhost:8083/
infuxdb与传统数据库比较,这里选用mysql对比
InfluxDB中独有的一些念概

Point由时间戳(time)、数据(field)、标签(tags)组成。
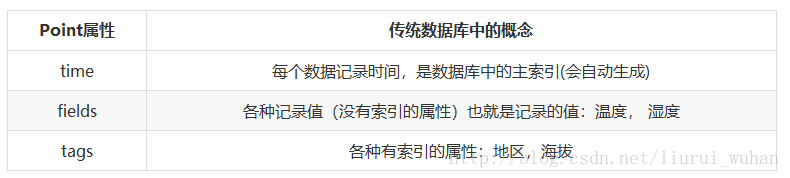
1、fields 的值只能是四种基本数据类型(int、float、boolean、string),使用string需要使用双引号
官方api描述:https://docs.influxdata.com/influxdb/v0.10/write_protocols/line/
2、对于influxDb的measurement来说,field是必须的,并且不能根据field来排序
3、Tag是可选的,tag可以用来做索引,tag是以字符串的形式存放的;
4、retention policy,保留策略,用于决定要保留多久的数据,保存几个备份,以及集群的策略等;
5、series,a series is the collection of data that share a retention policy, measurement, and tag set
关于series的理解,参照博客:http://www.cnblogs.com/strinkbug/p/5079553.html
6、time是主索引,跟操作系统的时间有关,如果插入的数据日期小于系统时间,插入失败,time的时间是0时区的时间,目前influxdb没有提供相应修改的方式,所以在使用api write数据的时候,指定time值就需要将时间+8小时。

Line Protocol格式
插入数据的格式似乎比较奇怪,这是因为influxDB储存数据所采用的是Line Protocol格式。
在上面两个插入数据的方法中,都有一样的部分。
weather,altitude=1000,area=北 temperature=11,humidity=-4
其中:
1.weather : 表名
2.altitude=1000,area=北 : tag
3.temperature=11,humidity=-4 :field
数据保存策略(Retention Policies)
InfluxDB没有提供直接删除Points的方法,但是它提供了Retention Policies。
主要用于指定数据的保留时间:当数据超过了指定的时间之后,就会被删除。
查看当前数据库的Retention Policies
创建新的Retention Policies
其中:
rp_name:策略名
db_name:具体的数据库名
30d:保存30天,30天之前的数据将被删除
它具有各种时间参数,比如:h(小时),w(星期)
REPLICATION 1:副本个数,这里填1就可以了
DEFAULT 设为默认的策略
修改Retention Policies
删除Retention Policies
函数
Aggregations Selectors Transformations
COUNT() BOTTOM() CEILING()
DISTINCT() FIRST() DERIVATIVE()
INTEGRAL() LAST() DIFFERENCE()
MEAN() MAX() FLOOR()
MEDIAN() MIN() HISTOGRAM()
SPREAD() PERCENTILE() NON_NEGATIVE_DERIVATIVE()
SUM() TOP() STDDEV()
配置文件
Global Options
[meta] ---配置集群
[data] ----数据信息
[hinted-handoff]
[cluster]
[retention]
[shard-precreation]
[admin]
[monitor]
[subscriber]
[http]
[graphite]
[collectd]
[opentsdb]
[udp]
[continuous_queries]
查询语法
表名都可以正则
select * from /.*/ limit 1
查询一个表里面的所有数据
select * from cpu_idle
查询数据大于200的。
select * from response_times where value > 200
查询数据里面含有下面字符串的。
select * from user_events where url_base = ‘friends#show’
约等于
select line from log_lines where line =~ /[email protected]/
按照30m分钟进行聚合,时间范围是大于昨天的 主机名是server1的。
select mean(value) from cpu_idle group by time(30m) where time > now() – 1d and hostName = ‘server1′
select column_one from foo where time > now() – 1h limit 1000;
select reqtime, url from web9999.httpd where reqtime > 2.5;
select reqtime, url from web9999.httpd where time > now() – 1h limit 1000;
类似like查询:url搜索里面含有login的字眼,还以login开头
select reqtime, url from web9999.httpd where url =~ /^\/login\//;
还可以做数据的merge
select reqtime, url from web9999.httpd merge web0001.httpd;