hive 内置函数很少,我们可以通过自定义的方式添加新的UDF上去,来增强hive的处理能力。
比如hive没有字符串包含的UDF.
我们通过Java+maven的方式来编写一个字符串包含的UDF
1、新建maven工程
2、修改pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lr.udf</groupId>
<artifactId>common.udf</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.source.version>1.8</java.source.version>
<java.target.version>1.8</java.target.version>
<maven.compiler.plugin.version>3.3</maven.compiler.plugin.version>
<file.encoding>UTF-8</file.encoding>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
</build>
</project>3、编写UDF类
package common.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 需要继承UDF
* @author liurui
*
*/
public class StringUDF extends UDF{
/**
* 重写evaluate方法,参数可以任意
* @param orgStr
* @param dest
* @return
*/
public Integer evaluate(String orgStr,String dest){
if(orgStr.contains(dest)){
return 1;
}
return 0;
}
public static void main(String[] args) {
StringUDF udf = new StringUDF();
System.out.println(udf.evaluate("aaabc", "b"));
}
}4、打包
mvn clean package5、上传到hdfs
hdfs dfs -put common.udf.jar /tmp/test/common.udf.jar
[root@bigdata-cdh001 home]# ll
total 4
drwx------. 2 centos-user centos-user 62 Aug 25 2017 centos-user
-rw-r--r-- 1 root root 2518 May 22 18:56 common.udf.jar
[root@bigdata-cdh001 home]# hadoop dfs -ls /tmp/test
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Found 1 items
drwxr-xr-x - hdfs supergroup 0 2018-04-10 15:11 /tmp/test/8a18f7a6b63a4b8180b242e448cea705
[root@bigdata-cdh001 home]# hdfs dfs -put common.udf.jar /tmp/test/common.udf.jar
[root@bigdata-cdh001 home]# hadoop dfs -ls /tmp/test
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Found 2 items
drwxr-xr-x - hdfs supergroup 0 2018-04-10 15:11 /tmp/test/8a18f7a6b63a4b8180b242e448cea705
-rw-r--r-- 3 root supergroup 2819 2018-05-21 22:34 /tmp/test/csot-hive-udf.jar
6、将UDF添加到hive
#将jar添加到hive
add jar hdfs:///tmp/test/common.udf.jar
#创建临时的UDF
create temporary function my_contains as 'common.udf.StringUDF';
#创建永久的只需要去掉temporary
[root@bigdata-cdh001 home]# hive
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.10.1-1.cdh5.10.1.p0.10/jars/hive-common-1.1.0-cdh5.10.1.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> add jar hdfs:///tmp/test/common.udf.jar;
converting to local hdfs:///tmp/test/common.udf.jar
Added [/tmp/6eaaaad7-1446-4bed-9543-0a02d901e8bc_resources/common.udf.jar] to class path
Added resources: [hdfs:///tmp/test/common.udf.jar]
hive> create temporary function my_contains as 'common.udf.StringUDF';
OK
Time taken: 1.692 seconds
hive>
> SELECT * FROM default.i_f_task_status where my_contains(task_id,'c')=0 LIMIT 5;
OK
1 100
1 100
1 100
1 100
1 100
Time taken: 0.109 seconds, Fetched: 5 row(s)
hive>
7、查询task_id不包含字符c的
my_contains(task_id,'c')=0 不包含 my_contains(task_id,'c')=1 包含SELECT * FROM default.i_f_task_status where my_contains(task_id,'c')=0 LIMIT 5;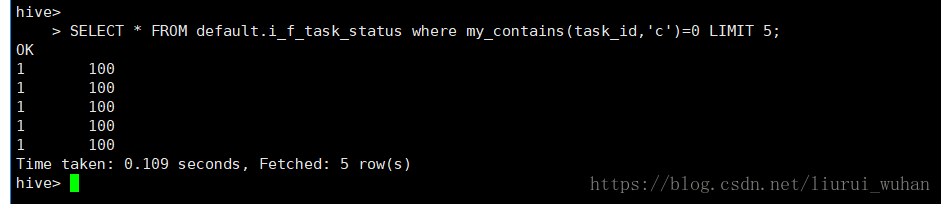

在hive添加的udf 在impala是不支持的,所以需要另外再加
如果是impala,创建函数的时候需要指定参数和返回值类型,如下:
则在impala-shell或者hue的impala上执行
create function csot_contains(string,string) returns int location 'hdfs:///tmp/test/common.udf.jar' symbol='cn.com.cloudstar.udf.StringUDF';[bigdata-cdh001:21000] > create function my_contains(string,string) returns int location 'hdfs:///tmp/test/common.udf.jar' symbol='common.udf.StringUDF';
Query: create function my_contains(string,string) returns int location 'hdfs:///tmp/test/common.udf.jar' symbol='common.udf.StringUDF'
Fetched 0 row(s) in 0.07s
[bigdata-cdh001:21000] > [bigdata-cdh001:21000] > SELECT * FROM default.i_f_task_status where my_contains(task_id,'c')=0 LIMIT 5;
Query: select * FROM default.i_f_task_status where my_contains(task_id,'c')=0 LIMIT 5
Query submitted at: 2018-05-22 19:19:09 (Coordinator: http://bigdata-cdh001:25000)
Query progress can be monitored at: http://bigdata-cdh001:25000/query_plan?query_id=34f236d41e4812c:9f1e208500000000
+---------+---------+
| process | task_id |
+---------+---------+
| 1 | 100 |
| 1 | 100 |
| 1 | 100 |
| 1 | 100 |
| 1 | 100 |
+---------+---------+
Fetched 5 row(s) in 4.55s
[bigdata-cdh001:21000] > 源码:https://gitee.com/qianqianjie/common.udf.git