现如今,词云技术遍地都是,分词模块除了jieba也有很多,主要介绍一下jieba的基本使用
import jieba import jieba.posseg as psg from os import path from collections import Counter s=u'我想和女朋友一起去北京天安门闲逛。。' cut = jieba.cut(s) print('精确模式') print(cut) print(','.join(cut)) print ('全模式') print(','.join(jieba.cut(s,cut_all = True))) print('搜索引擎模式') print(','.join(jieba.cut_for_search(s))) print('词性') print([(x.word,x.flag) for x in psg.cut(s)]) print([(x.word,x.flag) for x in psg.cut(s) if x.flag.startswith('n')]) print('--*--'*10) seg_list = jieba.cut("我来到北京清华大学", cut_all=True) print("Full Mode:", "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我来到北京清华大学", cut_all=False) print("Default Mode:", "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式 print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式 print(", ".join(seg_list)) d=path.dirname(__file__) sanguo_text=open(path.join(d,"data//sanguo.txt"),encoding='utf-8').read() print(len(sanguo_text)) sanguo_words = [x for x in jieba.cut(sanguo_text) if len(x) >= 2] c = Counter(sanguo_words).most_common(20) print(c)
运行结果
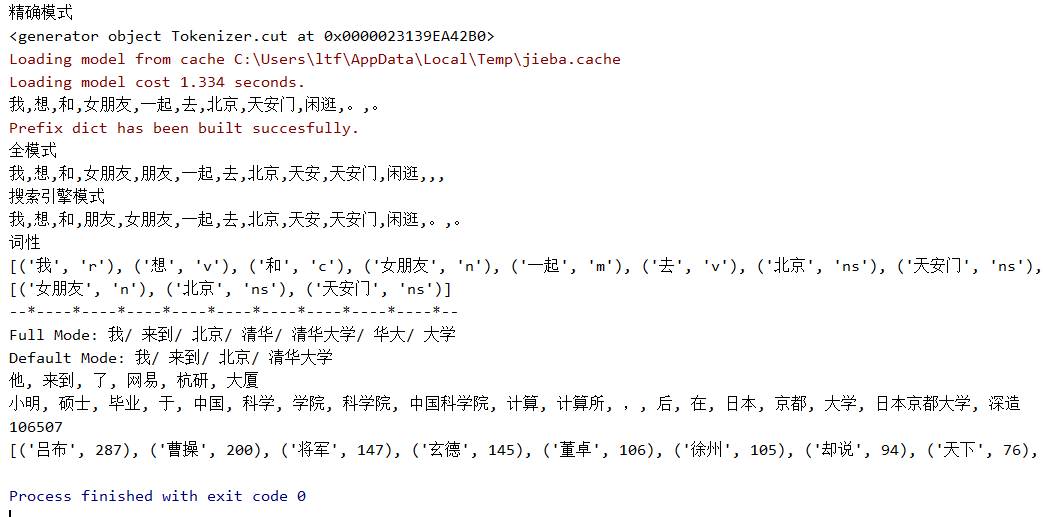
其中精确模式比较好用,全模式就是尽量将所有的词拿出来