原文:https://blog.csdn.net/shijing_0214/article/details/51134802?locationNum=2&fps=1
前面讲支持向量机的时候,提到了核函数,通过核函数可以实现特征点的非线性转换,从而实现分类。
字符串核函数也是一种核函数,但它与一般的核函数不同。其他核函数一般定义在欧氏空间上,而字符串核函数是定义在字符串集合上的核函数。字符串核函数被广泛用在文本分类、信息检索等方面。首先解释下什么是字符串核函数。与一般核函数一样,字符串核函数也需要高维特征空间。特征空间的维度由映射函数决定,例如映射ϕ(x1,x2,x3)ϕ(x1,x2,x3),则特征空间维数为三维。字符串核函数的特征空间维数也是由映射函数决定的,但不同的是,特征空间的每一维是用字符串来表示的。例如字母表为{a,b,c}长度大于等于3的字符串集合的特征空间有六维,分别是abc、acb、bac、bca、cab、cba。这样就可以将字符串s,t用长度为3的子串向量来“表示”,当然这里的表示不是说字符串能够用这些子串等价地表示,因为字符串核函数k(s,t)k(s,t)定义的是字符串s和t的余弦相似度,它们的子串越多,相似性就越高。
首先给出字符串核函数的映射函数在每一维上的取值表达式:
其中,特征空间是由所有长度为n的子串组成的,维数为∑n∑n维,∑∑是一个有限字符表,如上例长度为3的子串组成的特征空间维数为6,特征空间每一维都对应着一个子串;s表示长度大于等于n的字符串;0<λ≤10<λ≤1是一个衰减参数,l(i)l(i)表示子串u在字符串s中的长度,i是子串的下标序列,例如:
给定字符串s=“sectionalization”,子串subU1subU1=”set”,subU2subU2=”tion”,则subU1subU1下标序列i=(1,2,4)i=(1,2,4),长度l(i)l(i)为4;subU2subU2的下标序列i=(4,5,6,7)i=(4,5,6,7),长度l(i)l(i)为4。
举个例子来说明,如下: 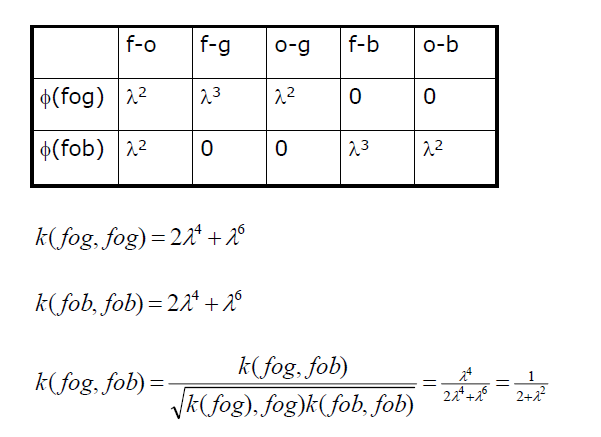
表示的是在字母表∑={f,o,g,b}∑={f,o,g,b}中长度为2的子串(部分子串两个字符串均没有,故不列出)组成的特征空间,由上面给出的映射函数每一维取值公式可知,
λλ的指数表示子串在字符串中的长度,系数表示出现次数,如2λ32λ3表示出现了两次长度为3的子串u。根据核函数的定义k(fog,fob)=<ϕ(fog),ϕ(fob)>=2λ4+λ6k(fog,fob)=<ϕ(fog),ϕ(fob)>=2λ4+λ6
因为字符串核函数kn(s,t)kn(s,t)定义的是字符串s和t中长度等于n的所有子串组成的特征向量的余弦相似度,所以字符串核函数以前面的核函数定义不同,为映射函数的内积再除以每个串对应的向量范数,如上例最后一个等式k(fog,fob)k(fog,fob)所示。