在文章开头给出结对同学的博客链接、本作业博客的链接、你所Fork的同名仓库的Github项目地址
给出具体分工
徐明盛:代码修改,消除警告,性能分析改进,爬虫
魏璐炜:单元测试,编写样例
本次作业沿用了徐明盛同学的代码,因此任务分配主要出于效率的考量:徐明盛同学熟悉自己的代码;魏璐炜同学只需要清楚函数接口便可以编写单元测试。
此外的爬虫和附加题没有硬性要求,按时间自行分配。各自都有进行尝试。
给出PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 600 | 480 |
| · Design Spec | · 生成设计文档 | 30 | 120 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 300 | 180 |
| · Code Review | · 代码复审 | 120 | 480 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 300 | 300 |
| 合计 | 1680 | 1840 |
解题思路描述与设计实现说明:
爬虫使用
用python编写了代码。有丰富的函数方便使用,主要流程如下:
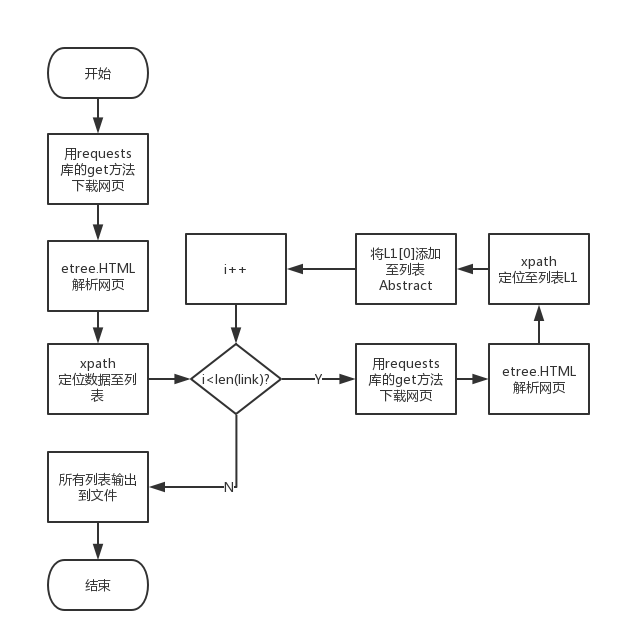
代码组织与内部实现设计(类图)
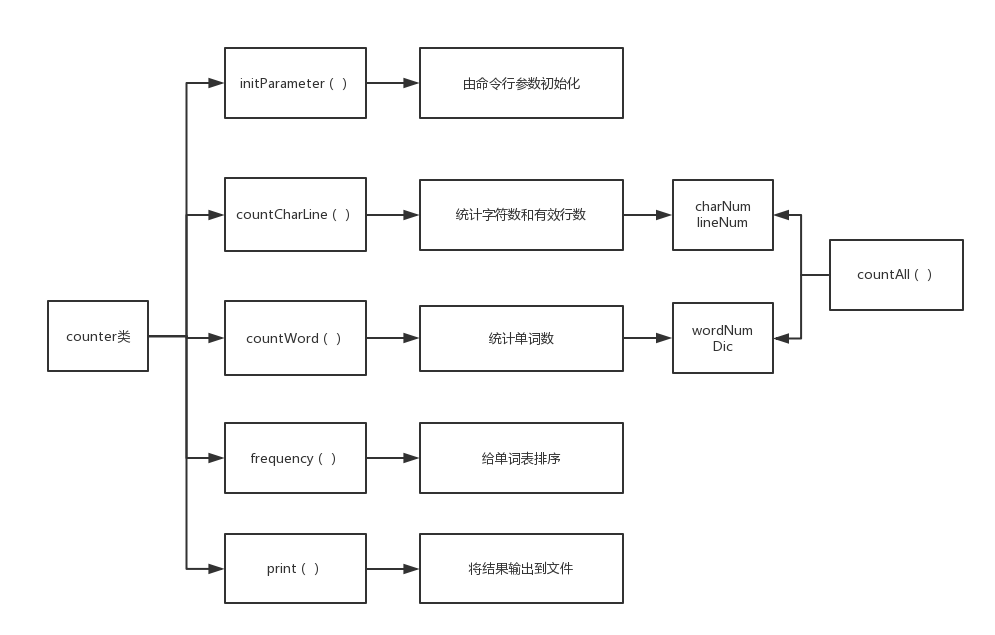
说明算法的关键与关键实现部分流程图
新增要求大部分只需要在原代码中增加一些自定义的参数,这些要求包括指定输入输出文件、权重、TopN,不介绍。
最大的改动是词组要求,且这个词组要求特别在:
1.不合法单词隔断词组;
2.分隔符一起输出。我认为,词组的累计性(一个单词可以在多个词组中)不适合维持一个当前词组,每次增减单词。
我想到,可以维持一个长度为m的队列,队列中的单词是词组的潜在成分。考虑到需要纳入分隔符,因此不直接把单词放在队列里;又注意到词组总是以单词开头以单词结尾,就可以在队列中存放单词首字母在line(文件中的一行)中的位置,那么单词的生成方式是:line.substr(queue.first(),词组长度)。词组长度由当前位置i-queue.first() 得到。
这个队列的重要行为是push和pop和清空:
push:当发现一个新单词首字母时,首字母位置push
pop:每输出一个词组,长度为m的套环往前移,pop清空:不合法单词阻断词组,因此清空时机即发现不合法单词时:
1.一个过早出现数字的单词
2.字母不到4就遇见分隔符的单词
3.一个数字开头的字母数字串附加题设计与展示
在要求爬取的基础上爬取了作者和PDF链接
实现思路
只需要在原来的爬虫代码上增加几个xpath获取位置就好了。
实现成果展示
关键代码解释:
贴出你认为重要的/有价值的代码片段,并解释
上文中算法提到的队列及其操作时机是我认为最重要的部分。尤其注意以数字开头的字母数字串也会阻隔单词,所以要清空单词队列。
以及下文消除警告的部分提到的,比如类型转换;虽然大部分时候没有影响,但是注重细节的人写的代码也给人带来安全感。
重要的是思想!代码很简单,就不罗列了。
性能分析与改进:
描述你改进的思路
关于性能改进,我拟出的标题是————vector of pair VS. map
这个问题还是挺有趣的!在上一次的个人项目中,有提到————
我将单词及其频率存储在map中。这是一读题就做出的决定,因为考虑到map可以直接通过key值访问索引,方便我对词频计数;然而在后期发现,在对单词词频自增前,需要查询其存在,这就必须要搜索。既然都搜索了,想必也找到了其索引,因此“通过key值访问value”的操作显得不必要了。并且,题目要求先对词频排序再对key值排序,而map不便于实现。为此我将map拷贝到vector<pair<string,int> >中。既然总是要使用到vector,而map有没有体现其优势,不如一开始就使用vector。我这样使用map,浪费了空间,拷贝到vector浪费了时间。
在上文中已经提到的本例中使用map的缺点之外,由性能分析我还注意到另外一点:map之insert————排序。
意思就是map在你插入之时,会主动由键值排序。然而这种排序不是我们想要的,我们要的是频率优先,所以我们之后还得自己排序。这就导致了时间的浪费————你map排序白排啦。
看上去一切都在为款款而来的vector<pair<string,int> > 做铺垫!
然而在引入容器时,会遇到新的问题:vector之查询————find_if。
vector的find对于pair似乎是没有支持,我们需要更明确的find_if来查找。一番查找后写好了find_if需要的函数对象,下面是使用对比图(采用的爬取结果作为样例):


是不是!很惊人!地!慢!(注意蓝色部分 find_if )
我猜测是这种pair容器以及find_if使用的仿函数似乎是太复杂了,以至于查询时带来了更更更更多的时间消耗。所以map与vector of pair之争目前看来是前者胜利了,map更迂回的使用方法虽然带来了一些额外消耗,但却具备更方便以及快速的查询功能(从这一点看来,map的自动排序并没有白白浪费),成为单词表的优秀人选~
结论:实验说话,不可以貌取人。
此外,还做了一些其它努力:
1.遍历次数:为了函数划分,我们遍历了两遍文件。但若是处于效率考量,遍历一遍就可以得到所有结果了。于是产生了countAll函数,遍历一遍文件,生成所有结果。两种调用方法供挑选。
2.tempWord:原先要维持一个string单词以存入字典。现在只需记录单词长度,改成int,会比操作字符串简单。
展示性能分析图和程序中消耗最大的函数

initDic->splitPerLine
分词组确实是程序运行的大头
单元测试:
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
(1)运行请在x86环境下运行
(2)单元测试说明
| 测定内容 | 测试函数 | 最终结果 |
|---|---|---|
| 不存在的文件名(或者错误的文件名) | countall() | 通过 |
| 测定字符数是否正确 | countCharLine() | 通过 |
| 测定行数是否正确 | countCharLine() | 通过 |
| 测定单词数是否正确 | countWord() | 通过 |
| 统计单词的频率功能(含权重\不含权重)且只输出一个单词 | frequency() | 通过 |
| 统计单词的频率功能(含权重\不含权重)且只输出多个单词 | frequency() | 通过 |
| 增加特殊用例测试(即词组中是否存在不合法的单词) | frequency() | 通过 |
| 更多词组形式(不合法+分隔符) | frequency() | 通过 |
| 使用cvpr爬取的结果测试 | 所有函数 | 通过 |
说明:最后一个测试是与几位优秀同学的结果相互比对后得出的答案,不能保证一定是正确的

函数说明
测试字符数以及行数是否正确
TEST_METHOD(testcountCharLine)
{
int argc = 11;
char **argv;
counter *myCounter = new counter;
argv = new char *[20];
for (int i = 0; i < 20; i++)
{
argv[i] = new char[20];
}
strcpy(argv[0], "WordCount.exe");
strcpy(argv[1], "-i");
strcpy(argv[2], "input.txt");
strcpy(argv[3], "-m");
strcpy(argv[4], "3");
strcpy(argv[5], "-n");
strcpy(argv[6], "3");
strcpy(argv[7], "-w");
strcpy(argv[8], "1");
strcpy(argv[9], "-o");
strcpy(argv[10], "output.txt");
myCounter->initParameter(argc, argv);
pair<int, int> lineresult = myCounter->countCharLine();
Assert::AreEqual(lineresult.first, 74);
Assert::AreEqual(lineresult.second, 2);
}
测定单词数
TEST_METHOD(testcountWord)
{
int argc = 11;
char **argv;
counter *myCounter = new counter;
argv = new char *[20];
for (int i = 0; i < 20; i++)
{
argv[i] = new char[20];
}
myCounter->initParameter(argc, argv);
int wordresult = myCounter->countWord();
Assert::AreEqual(wordresult, 9);
}测定输出的结果是否正确
TEST_METHOD(testprint)
{
myCounter->initParameter(argc, argv);
myCounter->countAll();
myCounter->frequency();
myCounter->print();
FILE *fp = NULL;
fopen_s(&fp, "output.txt", "r");
string fileBuf;
char c = 0;
while ( (c = fgetc(fp)) != EOF)
{
fileBuf += c;
}
string stdFile = "characters: 74\nwords: 9\nlines: 2\n<monday tuesday wednesday>: 11\n<tuesday wednesday thursday>: 11\n<wednesday thursday frida>: 1\n";
Assert::AreEqual(stdFile, fileBuf);
fclose(fp);
}运行结果:
上述的单元测试代码是中测试助教给的Wordcount样例对于这个程序是否运行正确,我们考虑到的异常以及输入的文本情况为:
(1)空文本(或者输入一个不存在的文本)
(2)单词的各种情况
· 合法词组之间穿插着多个分隔符
(例如hhhh qq@aaaa*qad hello等)
· 单词前面有数字的情况
(例如123qazd,qqqw852的单词统计以及词频考虑情况)
· 单词中夹带的不合法单词的情况
(例如:hhhh in hhhhh)
(3)单词频率(主要是对-m模块的测试)
贴出Github的代码签入记录
请合理记录commit信息
遇到的代码模块异常或结对困难及解决方法
将消除警告写在这里。
问题描述
warning LNK4042:对象被多次指定;
已忽略多余的指定大意是同名文件生成了同名的.obj文件。试了很多办法都不ok,最终这个解决了我的问题:
warning C4018:“<”:有符号/无符号不匹配map,vector等使用size方法时返回的是无符号数,我用来与之比较的是整型数,故警告。
解决方法是:1.定义无符号数i与size比较;2.强制转换。这个问题大多数时候是温和的,但是在一个时候会出现问题:i<v.size()-1。当无符号数0(容器大小为零)时,减1会变成一个大数,本来结果为false现在变成true了,你说问题大不大嘞。
warning C4996: 'strcpy': This function or variable may be unsafe. Consider using strcpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
警告原因是strcpy对于复制时超出内存的行为没有定义,所以推荐更安全的strcpy_s。解决过程中我的思考是:strcpy_s函数是vs自己的函数吧,兼容会不会不好。于是考虑使用strncpy。但是发现strncpy同时也存在危险:可能存在数组没有以'/0'结尾的问题。所以我还是使用了strpy_s。
warning C26495: Variable 'counter::inFilename' is uninitialized. Always initialize a member variable (type.6).
警告说输入文件名指针没有被初始化。要消除这个警告,可以在构造函数中:
1.给指针分配空间,并赋默认值“input.txt”;
2.给指针赋值NULL。这个问题我解决了很久。起因是我非常强迫症地想要动态分配空间。我非常不情愿使用方法1,因为我要在之后由用户输入的文件名动态分配空间,而使用方法1导致之后需要重新分配空间。麻烦!
但是采用方法2并由输入动态分配空间会导致下面这个警告:
warning C6387: “inFilename”可能是“0”: 这不符合函数“strcpy_s”的规范。// strcpy_s(inFilename, (strlen(argv[i]) + 2), argv[i]);
有可能在参数中没有找到输入文件名,所以inFilename动态分配内存后可能仍为NULL。消除警告的方法是在strcpy_s前加上inFilename是否为空指针的判断。
warning C26444: Avoid unnamed objects with custom construction and destruction (es.84). // myCounter->frequency();
说明:
The warning can flag code that is not compiler generated and that invokes a function that returns an object of a RAII type.
This warning helps to detect ignored call results in addition to wrong declarations.
它会导致:
inefficient code that allocates and immediately throws away resources or to the code that unintentionally ignores non-primitive data.
报警处的的frequency()函数将会排序单词表,并返回一个pair容器。但是在主函数中,这个返回值无人接收,成为local variable with no name,分配得资源又立即抛弃了。
解决办法是在主函数定义一个变量接收,或者修改函数不返回容器。前者太没必要了,故考虑后者:当初我设定这个返回值是为了方便单元检测或者日后有别的需求可以对它直接操作,
但仔细考虑觉得:
1.单元检测可以从输出文件读取结果,就不直接对字典检查了;
2.日后新的需求应该增加函数处理,而不是在主函数处理。
这个警告到处都找不到中文资料。所以后人遇到这个问题时,会不会翻到这篇文章呢? Hello from 2018!
做过哪些尝试:
当然是搜索因特网。对于找不到中文资料的部分,必应有给相关英文结果,但是很多名词都无法在中文语境里找到对应项。
是否解决
√
有何收获
学习英语很重要。代码质量分析很不错,会给出编译不给出的警告。做一个注重规范的人。
模块异常
· 单元测试时需要模拟采用命令行传参,通过二级指针解决char命令行传参的问题
· 单元测试中没有加入环境造成的问题
评价你的队友
魏璐炜评价徐明盛:
值得学习的地方:
- 他是一个非常严谨,好学的人,他教会了我许许多多,包括怎么去做一个项目,出现问题怎么排错,做单元测试时是否考虑的周全,还有哪些可能存在没有考虑到的地方,还有一些vs2017使用小技巧,他对于题目,对于需求非常的了解,是我学习的榜样!
需要改进的地方:
- 不需要改进,需要膜拜
徐明盛评价魏璐炜:
值得学习的地方:
-认真勤奋,熬了挺多夜的
值得改进的地方:
学习进度条
在看到题目后觉得正好可以学习新的语言!python!
本次任务过程中粗浅的将python语法看过一遍,并通过写爬虫加深了一部分理解~