python中有一个读写csv文件的包,直接import csv即可。
csv文件的性质:
- 值没有类型,所有值都是字符串
- 不能指定字体颜色等样式
- 不能指定单元格的宽高,不能合并单元格
- 没有多个工作表
- 不能嵌入图像图表
在CSV文件中,以,作为分隔符,分隔两个单元格。像这样a,,c表示单元格a和单元格c之间有个空白的单元格。依此类推。
excel形式
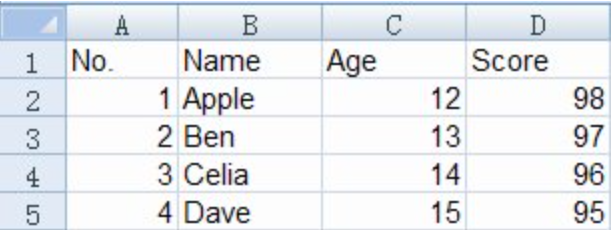
存储为csv文件
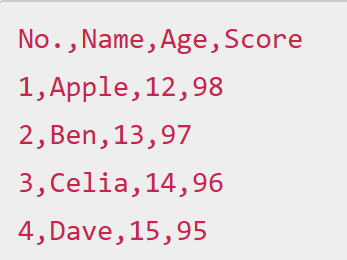
假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一列,即一个字段,利用Python自带的csv模块,有两种方法可以实现:
一、 csv.reader()方法
reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:比如下面的代码可以读取csv的全部内容,以行为单位:
1. 一行行取csv文件里的内容
with open('A.csv','rb') as csvfile: reader = csv.reader(csvfile) rows= [row for row in reader]
# print rows得到: ['1', 'Apple', '12', '98'], ['2', 'Ben', '13', '97'], ['3', 'Celia', '14', '96'], ['4', 'Dave', '15', '95']]
要提取其中某一列,可以用下面的代码:
ith open('A.csv','rb') as csvfile: reader = csv.reader(csvfile) column = [row[2] for row in reader] #print column得到: ['11','12','13','14','15']
注意: 从csv读出的都是str类型。这种方法要事先知道列的序号,比如Age在第2列,而不能根据'Age'这个标题查询。
二、csv.DictReader()方法
2.1 读取全部行
使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
with open('A.csv','rb') as csvfile: reader = csv.DictReader(csvfile) column = [row for row in reader] #print column得到: {'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'}, {'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'}, {'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
2.2 读取某一列
如果我们想用DictReader读取csv的某一列,就可以用列的标题查询:
with open('A.csv','rb') as csvfile: reader = csv.DictReader(csvfile) column = [row['Age'] for row in reader] print column
# 就得到: ['12', '13', '14', '15']
三、csv.writer()方法
3.1 用with open写
import csv with open("test.csv","w") as csvfile: writer = csv.writer(csvfile) #先写入columns_name writer.writerow(["index","a_name","b_name"]) #写入多行用writerows writer.writerows([[0,1,3],[1,2,3],[2,3,4]]) index a_name b_name 0 1 3 1 2 3 2 3 4
3.2 用open写
out = open(outfile, 'w', newline='') csv_writer = csv.writer(out, dialect='excel') csv_writer.writerow(list) # 必须添加newline='',和 dialect='excel',否则会导致文件每一行后面会多一个空行
四、pandas包
import pandas as pd
#任意的多组列表
a = [1,2,3] b = [4,5,6] #字典中的key值即为csv中列名 dataframe = pd.DataFrame({'a_name':a,'b_name':b}) #将DataFrame存储为csv,index表示是否显示行名,default=True dataframe.to_csv("test.csv",index=False,sep='') a_name b_name
0 1 4
1 2 5 2 3 6同样pandas也提供简单的读csv方法
import pandas as pd
data = pd.read_csv('test.csv')会得到一个DataFrame类型的data,不熟悉处理方法可以参考pandas十分钟入门