(一)四大语言
- 数据定义语言(DDL): create alter drop truncate
- 数据操纵语句(DML): insert update delete
- 数据查询语言(DQL): 由select子句 from子句 where子句组成的查询快
- 数据控制语句(DCL):grant、revoke
(二)四大完整性
- 实体完整性
- 域完整性
- 自定义完整性
- 引用完整性
(三)五大约束
- 主键约束
- 外键约束
- 唯一键约束
- 检查约束
- 默认值约束
(四)Sql server几种常用的数据类型
| 数据类型 |
说明 |
| Char |
固定长度、非Unicode字符数据类型。 |
| Varchar |
可变长度、非Unicode字符数据类型。 |
| Nchar |
固定长度、Unicode字符数据类型。 |
| Nvarchar |
可变长度、Unicode字符数据类型。 |
| tinyint/smallint/int |
整数 |
| float/decimal/real |
小数 |
| Money(C#:double) |
|
| Bit |
存储布尔数据类型(1-true;0-false) |
| Image |
可用来存储图像 |
(五).Char、Varchar、Nchar和Nvarchar之间区别
一、了解Sql Server中的两个函数:
- Len(参数) ---计算指定参数的字符个数,不区分中英文。
- DataLength(参数)---计算指定参数所占的字节长度。一个英文占一个字符,中文占两个。
通过例子看下两者的区别:
Select Len('aaa')
Select Len('小黄人')
---结果为 3 3
Select DATALENGTH('aaa')
Select DATALENGTH('小黄人')
---结果为 3 6二、区别
一个字符占一个字节:
Char:当存储的字符所占空间小于分配空间时,分配空间的大小不会发生变化。
Varchar: Var,可变的。一个字符占一个字节。分配空间的大小是一个动态变化的过程。
一个字符占两个字节:
Nchar: 除了每个字符用两个字节存储这点与Char不同之外,其余和Char类似。
Nvarchar: 以此类推,很好理解了。
测试:
表(Person)设计:
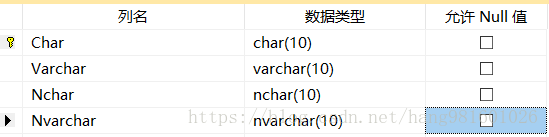
有个细节需要注意:char(10),这个10表示的是 能够存储的字符个数,而不是字节长度 。
表数据:

测试用例:
Select Len(Char) from Person
---结果:3 5 7
Select DataLength(Char) from Person
---结果:10 10 10
Select Len(Varchar) from Person
---结果:3 5 7
Select DataLength(Varchar) from Person
---结果:3 5 7
---下面两种均为Unicode字符,每个字符占用2个字节。
Select Len(Nchar) from Person
---结果:3 5 7
Select DataLength(Nchar) from Person
---结果:20 20 20
Select Len(Nvarchar) from Person
---结果:3 5 7
Select DataLength(Nvarchar) from Person
---结果:6 10 14
(六)为什么英文数据不会出现乱码而中文数据会?
一个英文对应一个byte,而byte是存储和读取数据的最短长度。所以即使出现英文数据未全部读取的情况也不会出现乱码。而一个中文对应两个byte,如果出现读取一半的情况,就会产生乱码。为了解决这种情况,Unicode编码产生了。英文字符也好,中文字符也罢,存储和读取的最短数据长度为两个byte,这样就解决了中文数据乱码的问题。