非阻塞队列——ConcurentLinkedQueue
首先查看ConcurrentLinkedQueue默认构造函数,观察它在初始化时做了什么操作。
/**
* 创建一个最初为空的{@code ConcurrentLinkedQueue}。
*/
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
可以看到ConcurrentLinkedQueue在其内部有一个头节点和尾节点,在初始化的时候指向一个节点。

对于入队(插入)操作一共提供了这么2个方法(实际上是一个):
| 入队(插入) |
add(e)(其内部调用offer方法,) |
offer(e)(插入到队列尾部,当队列无界将永远返回true) |
结合源码食用更佳:
//ConcurrentLinkedQueue#add
public boolean add(E e) {
return offer(e);//add方法和offer方法没区别啊,马飞
}
//ConcurrentLinkedQueue#offer
public boolean offer(E e) {
checkNotNull(e);//入队元素是否为空,不允许Null值入队
final Node<E> newNode = new Node<E>(e);
/*tail指向的是队列尾节点,但有时tail.next才是真正指向的尾节点*/
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {//此时tail=t=p指向的就是队列真正的尾节点
if (p.casNext(null, newNode)) {//cas算法
if (p != t)
casTail(t, newNode);
return true;
}
}
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
p = (p != t && t != (t = tail)) ? t : q;
}
}
//ConcurrentLinkedQueue#checkNotNull
private static void checkNotNull(Object v) {
if (v == null)
throw new NullPointerException();//为空抛出异常
}
//ConcurrentLinkedQueue#casNext
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
//ConcurrentLinkedQueue#casTail
private boolean casTail(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, tailOffset, cmp, val);
}UNSAFE.compareAndSwapObject(Object o, long offset,int expected,int x);应该可以猜到是调用了JVM处理器本身的CAS指令来实现原子操作。
-
第一个参数o为给定对象,offset为对象内存的偏移量,通过这个偏移量迅速定位字段并设置或获取该字段的值,
-
expected表示期望值,x表示要设置的值,下面3个方法都通过CAS(比较和交换,Compare and swap,一种有名无锁算法)原子指令执行操作。
入队过程如下图所示:
① 队列中没有元素,第一次入队操作:
进入循环体:
t = tail;
p = tail;
q = p.next = null;

判断尾节点的引用p是否指向的是尾节点(if(q == null))->是:
CAS算法将入队节点设置成尾节点的next节点(p.casNext(null, newNode))
判断tail尾节点指针的引用p是否大于等于1个next节点(if (p != t))->否
返回true

② 队列中有元素,进行入队操作:
1) 第一次循环:
t = tail;
p = tail;
q = p.next = Node1;
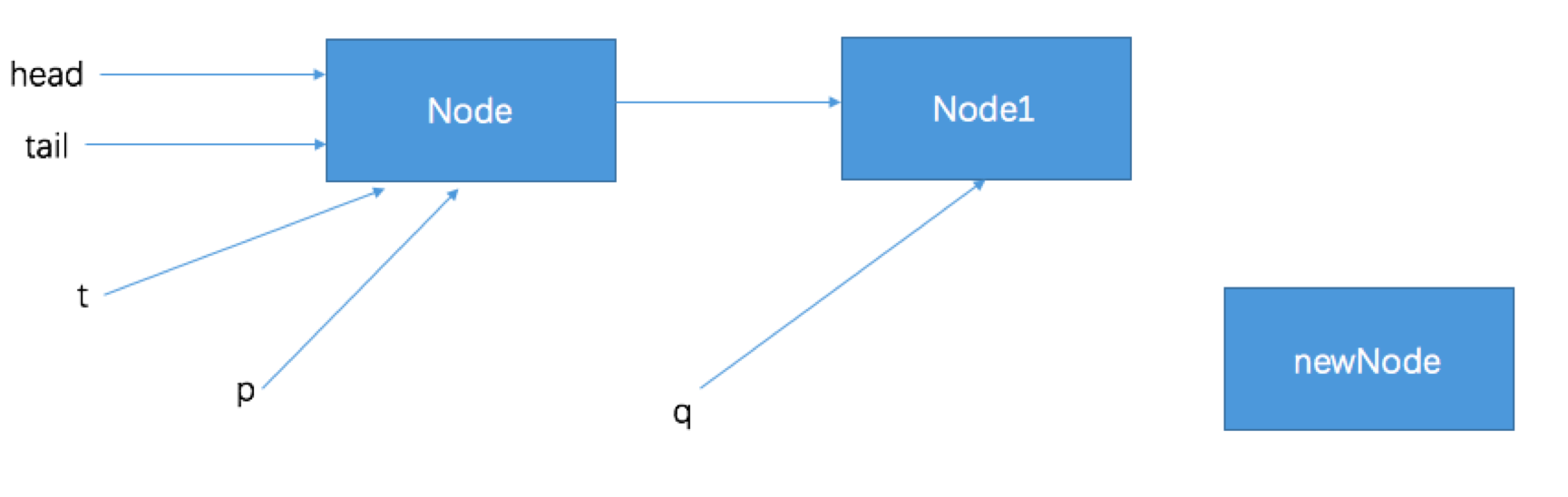
判断tail尾节点指针的引用p是否指向的是尾节点(if(q == null))->否
判断tail尾节点指针的引用p是否指向的是尾节点(else if (p == q))->否
将tail尾节点指针的引用p向后移动(p = (p != t && t != (t = tail)) ? t : q;)->p = Node1

2) 第二次循环:
t = tail;
p = Node1;
q = p.next = null;

判断tail尾节点指针的引用p是否指向真正的尾节点(if(q == null))->是:
CAS算法将入队节点设置成尾节点的next节点(p.casNext(null, newNode))
判断tail尾节点指针的引用p是否大于等于1个next节点(if (p != t))->是:
更新tail节点(casTail(t, nextNode))
返回true

入队的操作都是由CAS算法完成,显然是为了保证其安全性。整个入队过程首先要定位出尾节点,其次使用CAS算法将入队节点设置成尾节点的next节点。整个入队过程首先要定位队列的尾节点,如果将tail节点一直指向尾节点岂不是更好吗?每次即tail->next = newNode;tail = newNode;这样在单线程环境来确实没问题,但是,在多线程并发环境下就不得不要考虑线程安全,每次更新tail节点意味着每次都要使用CAS更新tail节点,这样入队效率必然降低,所以ConcurrentLinkedQueue的tail节点并不总是指向队列尾节点的原因就是减少更新tail节点的次数,提高入队效率。
对于出队(删除)操作一共提供了这么1个方法:
| 出队(删除) |
poll(e)(队列中有元素将元素移除对首并返回该元素)) |
offer(e)(插入到队列尾部,当队列无界将永远返回true) |
//ConcurrentLinkecQueue#poll
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
if (p != h)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}以上面队列中有两个元素为例:(注意,初始时,head指向的是空节点)

出队(删除):
1) 第一次循环:
h = head;
p = head;
q = null;
item = p.item = null;

判断head节点指针的引用是否不是空节点(if (item != null))->否,即是空节点
判断(暂略)
判断(暂略)
将head节点指针的引用p向后移动(p = q)
2) 第二次循环:
h = head;
p = q = Node1;
q = Node1;
item = p.item = Node1.item;

判断head节点指针的引用p是否不是空节点(if (item != null))->是,即不是空节点:
判断head节点指针与p是否指向同一节点(if (p != h))->否:
更新头节点(updateHead(h, ((q = p.next) != null) ? q : p))
返回item

实际上继续出队会发现,出队和入队类似,不会每次出队都会更新head节点,原理也和tail一样。