文章首发于微信公众号《与有三学AI》
04 这是深度学习模型解读第4篇,本篇我们将介绍MobileNets。
01 概述
Google开发的MobileNets【1】是用于嵌入式平台计算机视觉应用的基准模型。MobileNets是流线型的架构,它使用depthwise sparable convolution(深度可分离卷积)来构建轻量级的深层神经网络。通过引入两个简单的全局超参数,可实现在速度和准确度之间有效地进行平衡。这两个超参数允许模型构建者根据问题的约束条件,为其应用选择合适大小的模型。MobileNets应用在广泛的场景中,包括物体检测,细粒度分类,人脸属性等。
02 Mobilenets结构
Mobilenets基本组成单元是depthwise sparable convolution+pointwise convolution,下图是其组成结构图。

我们可以看到它由3*3的通道分组卷积(depthwise separable convolution)加1*1的普通卷积(point wise convolution)组成。它的组成结构本质上就是Xception结构,如下图。
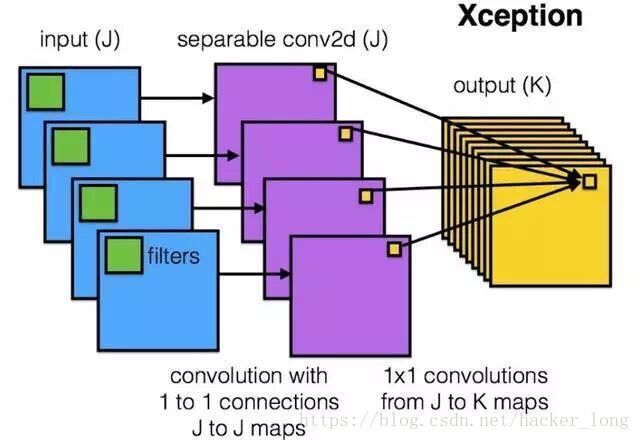
从图中可以看出,经过3*3深度卷积,每个通道的输出信息只和之前的对应通道信息相关,而普通3*3卷积每个通道输出信息和之前所有通道信息相关,这是它们的本质区别。
下面我们计算一下depthwise sparable convolution和普通卷积之间的计算量的比较,便于我们客观理解depthwise sparable convolution的有效性。
假设输入图片是DF*DF*M,输出图片是DF*DF*N,卷积核尺度是DK*DK。
普通卷积计算量:
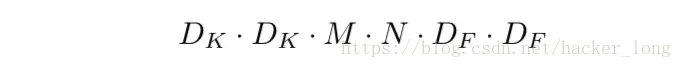
depthwise sparable convolution计算量:
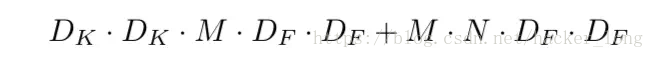
两个比值为:
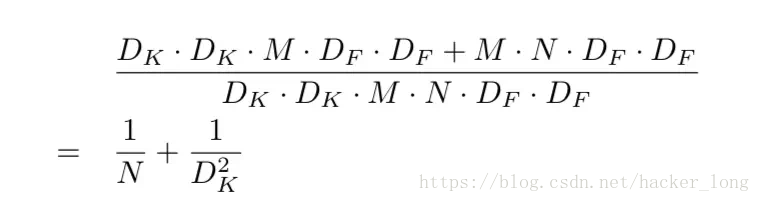
一般情况下N比较大,当DK=3时,depthwise sparable convolution计算量仅为普通卷积计算量的1/9。
Mobilenets结构就是由这些depthwise sparable convolution+pointwise convolution线性叠加构成的。结构如下图。
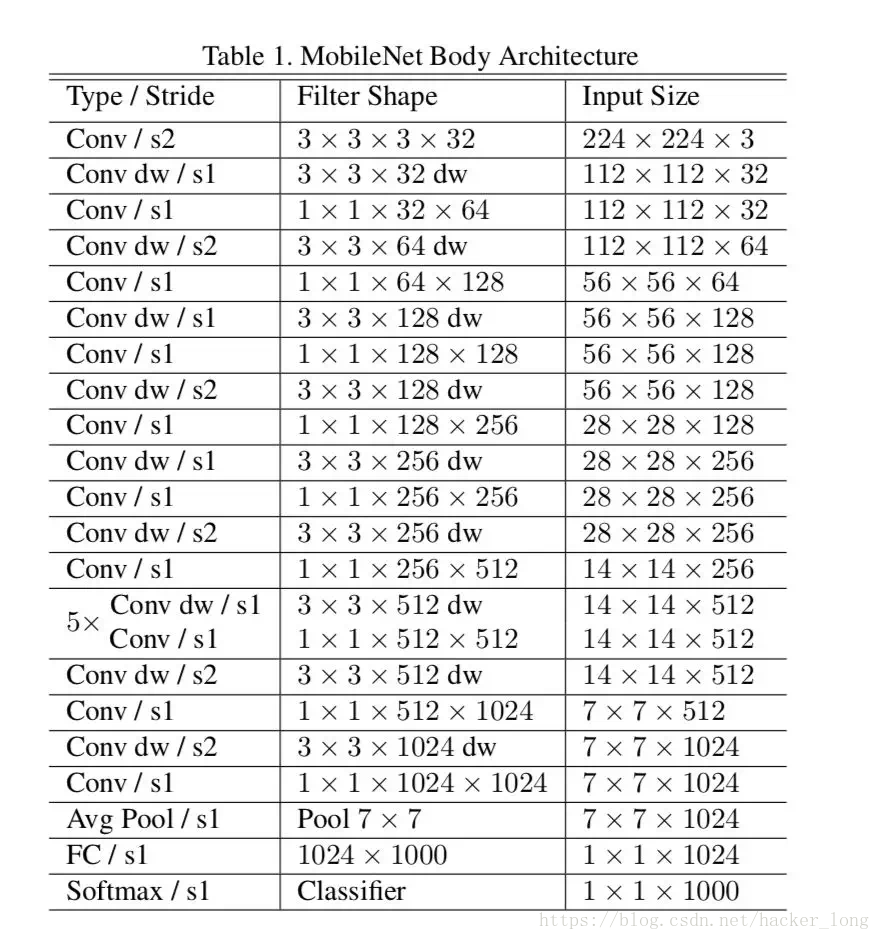
从图中可以看出先是一个3*3普通卷积,然后是叠加depthwise sparable convolution+pointwise convolution,之后是全局均值池化,接着是全连接层,最后Softmax输出。
下图是MobileNets和各个网络的比较。
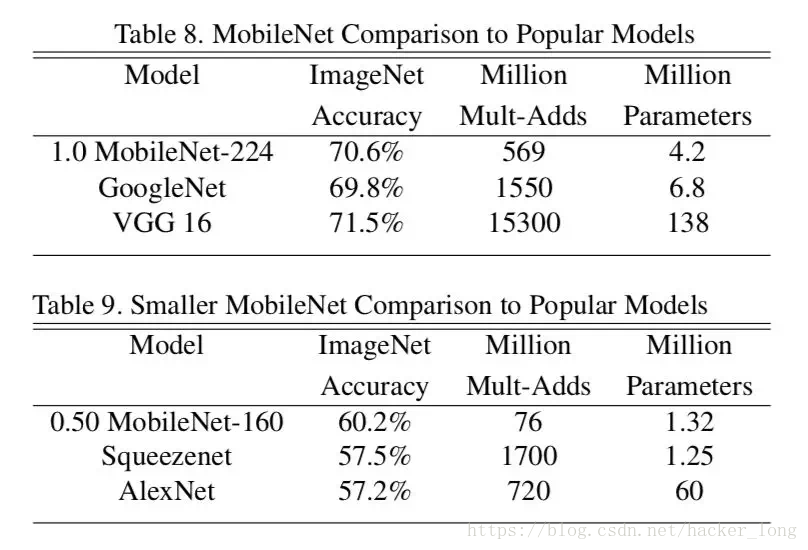
可以看出在参数量减小的领先优势之下,还能取的很高的准确率。
03 模型压缩
可以通过定义width multiplier α(宽度乘数)和resolution multiplier ρ (分辨率乘数)两个超参数,来实现不同版本的mobilenets,从而实现不同要求的模型压缩。
1.第一个参数α主要是按比例减少通道数,其取值范围为(0,1),α ∈ {1, 0.75, 0.5, 0.25} 的测试效果如下图:
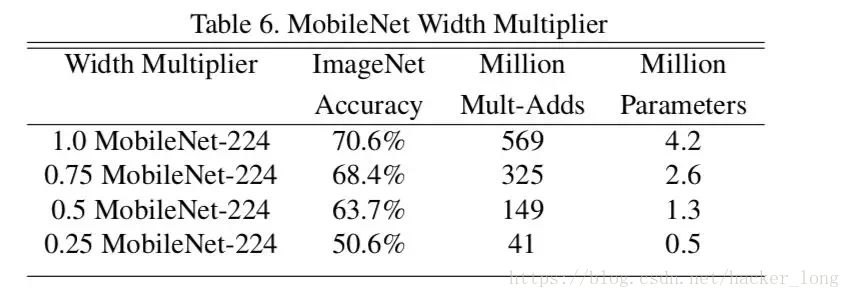
可以看出随着α减小,准确率下降,参数量减小,速度提升。
2.第二个超参数ρ 主要是按比例改变输入数据的分辨率。ρ 如果为{1,6/7,5/7,4/7},则对应输入分辨率为{224,192,160,128}。测试效果如下图:
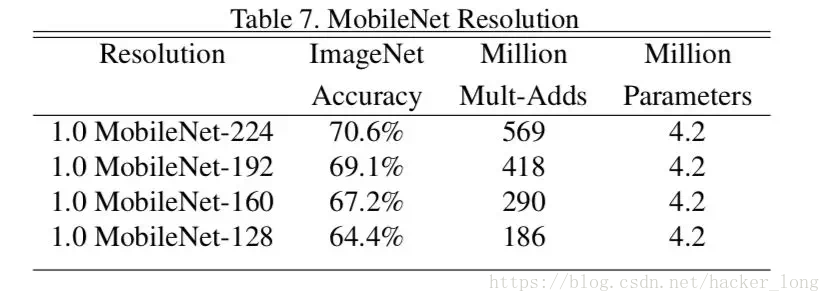
可以看出,随着分辨率下降,准确率下降,随之速度加快。日常应用中,可以通过这两个参数的选取来综合考虑选择模型。
模型分享到了第四篇,实习也到了尾声即将杀入校招大军,非常感谢鹏哥的帮助和指导。如果有朋友提供好的机会,欢迎后台留言。
参考文献
【1】Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. 2017.
同时,在我的知乎专栏也会开始同步更新这个模块,欢迎来交流
https://zhuanlan.zhihu.com/c_151876233
注:部分图片来自网络
—END—
打一个小广告,我在gitchat开设了一些课程和chat,欢迎交流。