Blob<Dtype>::Reshape(const vector<int>& shape)
功能:为blob分配内容空间
该函数一般在开辟空间内存时调用,如输入的data层,InputLayer<Dtype>::LayerSetUp中调用。
一般shape是(num, channel, width, height), 容量count = num*channel*width*height 是空间的大小,其中num一般是batch_size;capacity是历史reshape大小(如果空间不足,reshape就会重新扩充)。
reshape为SyncedMemory准备了capacity*sizeof(Dtype)个字节单元,SyncedMemory(size)并不会立刻启动状态转移自动机申请内存/显存。
只有执行Blob:: cpu_data/gpu_data/mutable_cpu_data/mutable_gpu_data,才会申请。也就是说,使用时才会有内存空间的损耗。
template <typename Dtype>
void Blob<Dtype>::Reshape(const vector<int>& shape) {
CHECK_LE(shape.size(), kMaxBlobAxes);
count_ = 1;
shape_.resize(shape.size());
if (!shape_data_ || shape_data_->size() < shape.size() * sizeof(int)) {
shape_data_.reset(new SyncedMemory(shape.size() * sizeof(int)));
}
int* shape_data = static_cast<int*>(shape_data_->mutable_cpu_data());
for (int i = 0; i < shape.size(); ++i) {
CHECK_GE(shape[i], 0);
if (count_ != 0) {
CHECK_LE(shape[i], INT_MAX / count_) << "blob size exceeds INT_MAX";
}
count_ *= shape[i];
shape_[i] = shape[i];
shape_data[i] = shape[i];
}
if (count_ > capacity_) {
capacity_ = count_; // 超过容量,重新分配内存
data_.reset(new SyncedMemory(capacity_ * sizeof(Dtype))); // 原始数据的内存空间
diff_.reset(new SyncedMemory(capacity_ * sizeof(Dtype))); // 梯度数据的内存空间
}
}
template <typename Dtype>
void Blob<Dtype>::Reshape(const BlobShape& shape) {
CHECK_LE(shape.dim_size(), kMaxBlobAxes);
vector<int> shape_vec(shape.dim_size());
for (int i = 0; i < shape.dim_size(); ++i) {
shape_vec[i] = shape.dim(i);
}
Reshape(shape_vec);
}
syncedMem值得好好了解,可以参考了这里:
https://blog.csdn.net/langb2014/article/details/51637636
顺手摘一段过来,主要是下面这个图比较形象
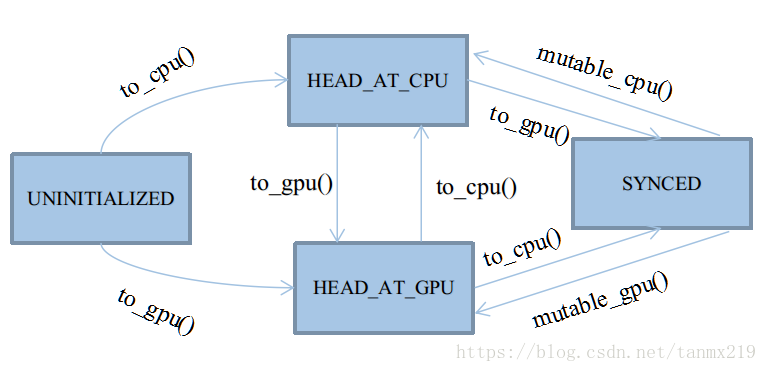
状态转移自动机
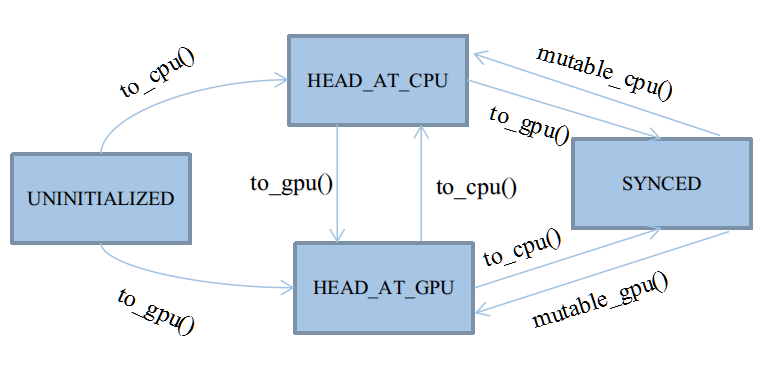
自动机共有四种状态,以枚举类型定义于类SyncedMemory中:
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };这四种状态基本会被四个应用函数触发:cpu_data()、gpu_data()、mutable_cpu_data()、mutable_gpu_data()
在它们之上,有四个状态转移函数:to_cpu()、to_gpu()、mutable_cpu()、mutable_gpu()
前两个状态转移函数用于未进入Synced状态之前的状态机维护,后两个用于从Synced状态中打破出来。
具体细节见后文,因为Synced状态会忽略to_cpu和to_gpu的行为,打破Synced状态只能靠人工赋值,切换状态头head。
后两个mutable函数会被整合在应用函数里,因为它们只需要简单地为head赋个值,没必要大费周章写个函数封装。
★UNINITIALIZED:
UNINITIALIZED状态很有趣,它的生命周期是所有状态里最短的,将随着CPU或GPU其中的任一个申请内存而终结。
在整个内存周期里,我们并非一定要遵循着,数据一定要先申请内存,然后在申请显存,最后拷贝过去。
实际上,在GPU工作的情况下,大部分主存储体都是直接申请显存的,如除去DataLayer的前向/反向传播阶段。
所以,UNINITIALIZED允许直接由to_gpu()申请显存。
由此状态转移时,除了需要申请内存之外,通常还需要将内存置0。
★HEAD_AT_CPU:
该状态表明最近一次数据的修改,是由CPU触发的。
注意,它只表明最近一次是由谁修改,而不是谁访问。
在GPU工作时,该状态将成为所有状态里生命周期第二短的,通常自动机都处于SYNCED和HEAD_AT_GPU状态,
因为大部分数据的修改工作都是GPU触发的。
该状态只有三个来源:
I、由UNINITIALIZED转移到:说白了,就是钦定你作为第一次内存的载体。
II、由mutable_cpu_data()强制修改得到:都要准备改数据了,显然需要重置状态。
cpu_data()及其子函数to_cpu(),只要不符合I条件,都不可能转移到改状态(因为访问不会引起数据的修改)
★HEAD_AT_GPU:
该状态表明最近一次数据的修改,是由GPU触发的。
几乎是与HEAD_AT_CPU对称的。
★SYNCED:
最重要的状态,也是唯一一个非必要的状态。
单独设立同步状态的原因,是为了标记内存显存的数据一致情况。
由于类SyncedMemory将同时管理两种主存的指针,
如果遇到HEAD_AT_CPU,却要访问显存。或是HEAD_AT_GPU,却要访问内存,那么理论上,得先进行主存复制。
这个复制操作是可以被优化的,因为如果内存和显存的数据是一致的,就没必要来回复制。
所以,使用SYNCED来标记数据一致的情况。
SYNCED只有两种转移来源:
I、由HEAD_AT_CPU+to_gpu()转移到:
含义就是,CPU的数据比GPU新,且需要使用GPU,此时就必须同步主存。
II、由HEAD_AT_GPU+to_cpu()转移到:
含义就是,GPU的数据比CPU新,且需要使用CPU,此时就必须同步主存。
在转移至SYNCED期间,还需要做两件准备工作:
I、检查当前CPU/GPU态的指针是否分配主存,如果没有,就重新分配。
II、复制主存至对应态。
处于SYNCED状态后,to_cpu()和to_gpu()将会得到优化,跳过内部全部代码。
自动机将不再运转,因为,此时仅需要返回需要的主存指针就行了,不需要特别维护。
这种安宁期会被mutable前缀的函数打破,因为它们会强制修改至HEAD_AT_XXX,再次启动自动机。