最近由于工作原因,开始进行一些爬虫的学习。记录一下我第一个爬虫踩过的坑!
首先感谢github给了我学习下去的动力。我使用的是python3.5,在window10下运行。爬虫用的是selenium+webserver的组合。
问题记录:
1、开始的化想使用webdriver.PhantomJS,但是报错

所以 PhantomJS是不能刚在3.5使用的,要使用headless

本人由于个人喜好问题,最后选用了chrome
2、在使用安装headless的时候一定要选择版本匹配。在chrome地址栏里面输入chrome://version/
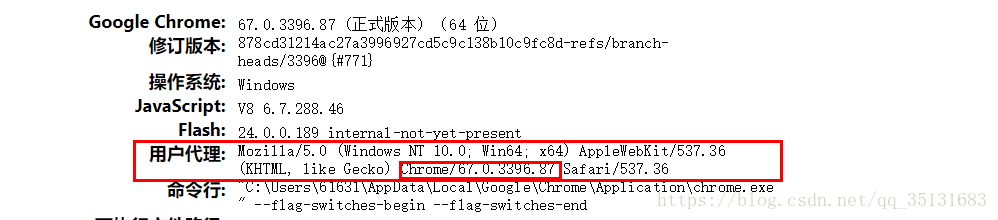
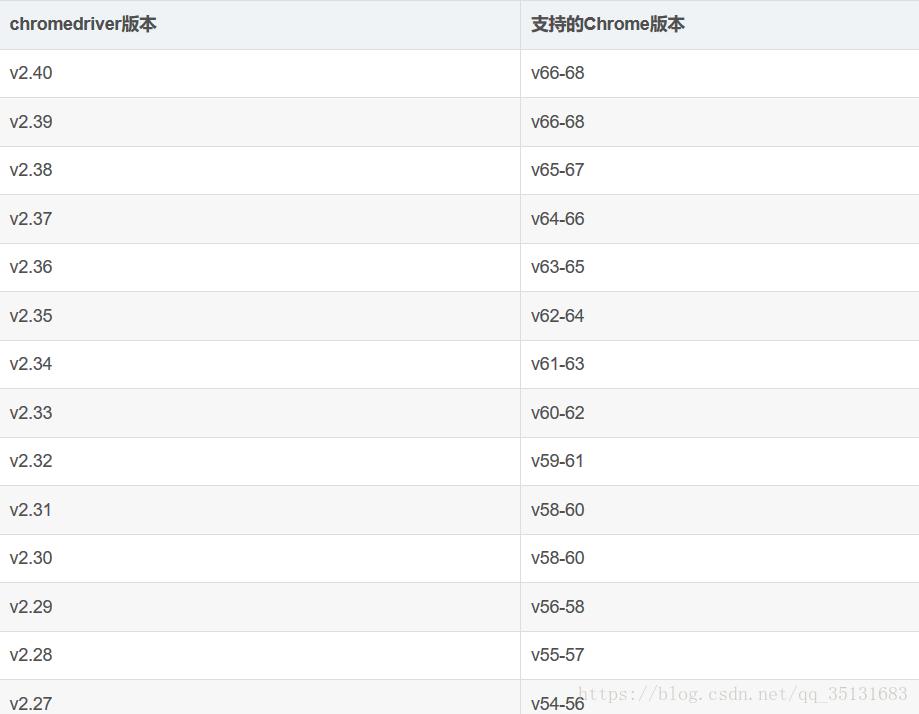
这个 chrome的版本号一定要匹配chromedriver的版本。
3、要注意 lxm和cssselect的安装,全靠这篇博文了https://blog.csdn.net/sinat_21302587/article/details/61935447,
我这边解决的时候还在cssselect.py里面添加了下述代码,才解决问题
from cssselect.parser import (parse, Selector, FunctionalPseudoElement,
SelectorError, SelectorSyntaxError)
from cssselect.xpath import GenericTranslator, HTMLTranslator, ExpressionError
VERSION = '1.0.3'
__version__ = VERSION
4、 根据运行的错误日志,把phantomjs添加完环境变量 ,但是chromedriver.exe执行的时候还是报错,无从下手,后来我把phantomjs有复制了一份,放在了python/scripts 没想到竟然好用了。。不知道为什么。
5、犯了一个很小白的错误,当时安装lxm和cssselect时候,找了好多资料上面写着用pip install 命令,我在IDLE上面敲了10几遍,都报错,后来才发现,在cmd的控制台上面安装就好。。
说了半天语无伦次,从写代码到完美运行中间弄了一周,其中翻过的山好多都忘掉了,所以写的很乱,附一张成功的图给自己加油打气,下次一定从头开始记录,毕竟我是一个彻底的小白。

