JPS(是jdk的工具):表示查看当前主机有哪些运行的进程
NameNode :表示主节点
DataNode:表示数据节点
SecondaryNameNode :表示次要名称节点
--节点表示:一台机器
进程是运行在机器上的,一个软件可以有多个进程(分布式软件:Hadoop)
HDFS只是Hadoop的一部分,Hadoop还有MR、yarn
HDFS是分布式软件系统:将文件自动分布在三台机器上(副本/备份)
HDFS的特点:
1.可容错:表示你把软件删除了,还可以复原
2,低廉硬件(安装了x86服务器/CPU)
3.高吞吐量(IO):分布多台机器同时处理
4.适用于有超大数据集的应用程序(1G以上大小的表格)
--但是不能满足:update(随机读写),但是可以以流的形式访问文件,提高了性能
---------
POSIX:可移植操作系统接口(是一个规范)
说白就是一个文件系统的接口,ext4、ext3、FAT32、NTFS全部都实现了这个接口,但是功能不一定全部实现
-HDFS框架是有中心的架构
主节点是:NameNode
用于对外(client)通信,通过交换机接收和发送,但是查询到的数据不经过这里直接由DataNode交给client
管理+协调,可以控制其他节点
完成任务(干活节点):DataNode
DataNode之间没有关联,之间的通信也是通过局域网
--实际生产环境中是有多个NameNode
MateData(元数据):元数据就是形容数据的数据
在这里他包含NameSpace:目录结构+blockdata(块数据)
HDFS是分块存储的,块表示一个文件存储在哪台机器上
------------
client(客户端)与NameNode之间是元数据交换
client与DataNode之间是数据交换
在同一个机架上通信快,HDFS会在同一个机架上放两个数据(在两台机器上),在不同的机架上保存一个(备份)
128M是一个block(块)
block就是键值对--映射到内存中就是元数据
key:block的id(哪台机器)-----------value:block的内容地址
--文件越小消耗的内存越大,因为保存相同大小,文件越多分的块越多,映射到内存中的元数据越多
例如:文件1024G,保存1T大小的这样的文件,占用内存8M,磁盘大小是3T
文件1M,保存1pb大小的这样的文件,占用内存1T,磁盘大小是3pb
分块是客户端
客户端将文件分块,串行依次写入,分的块不一定保存在同一台机器上
1.向文件系统(Hadoop集群)中上传文件
hadoop fs -put /abc /
/abc:表示将要上传的文件
/:表示上传到集群中的路径是:/
----------
Fs文件系统----保存file
数据库(DB)----保存表格/table-----存入之后需要经常修改
HDFS---file----crd(没有u不能随机读写,但是能追加),
记住HDFS与数据库无关,HDFS是处理海量数据的,不能经常修改
---
OLTP:在线事务处理(对数据库的写操作)
主要是数据库操作--web网站
特点:实时(立即有效果),处理的数据量小
OLAP:对数据库的读、分析处理
主要是:Hadoop
特点:实时不高,数据量大,HDFS是一次写入多次读取的模式
--元数据:ns(目录结构)+blockMap(文件所在的地址)
Secondary不是NameNode的备份,因为NameNode与Secondary共存亡
他类似于秘书:将内存中的内容持久化
工作:将最近的一个image(存量)与edit—log(增量)合并--生成出最新的image,并将开始的image删除,循环操作
这是因为每写一个文件,都会产生一个edit-log
过程:NameNode将日志+最新的image发送给--Secondary,Secondary将这两个和合并,并删除原来的image,发送给NameNode一个最新的image(这两个是进程之间通信通过Http协议)
--Hadoop中的配置文件
permission权限,false:表示任何人都可以访问,实际生产环境中true
每次格式化,version中的NameSpaceID、clusterID(集群的id)改变了
集群在开启前几分钟会开启安全模式(SafeMode),DataNode向NameNode汇报数据信息,之后自动关闭
50010是集群之间的通信端口号,如果是非知名端口号,防火墙会拦截
hadoop fs -checksum /fileName:校验码,可以查看文件是否被改变(是否成为脏数据)
------mapreduce
hdfs:是分布式存储,可以单独使用
mapreduce是分布式计算,必须按照分布式存储才能分布式计算
map:映射、转化、分
reduce:合并、减少
MR是计算模型:可以并行化处理大量数据(提高效率)
a.并行(事):一件事分成多个快,多个人同时做
b.并发(人):多个人同时做一件事
cdh与hdp是两家最大的hadoop上市公司(在2018年听说要合并)
以后spark(函数式设计语言)会代替mapreduce,因为mapreduce相对于比较慢、难以维护。
-------实际生产中的集群需求:
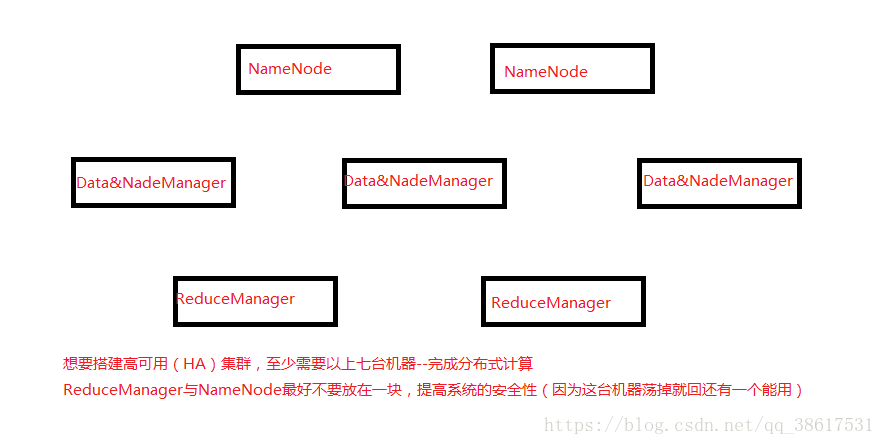
MapReduce集群搭建
1.yarn环境
在/usr/local/hadoop/etc/hadoop/yarn-env.sh中配置--java安装路径
2.MapReduce配置 IP:8088
将mapred-site.xml.tmplate复制成mapred-site.xml
cp mapred-site.xml.tmplate mapred-site.xml
将mapred-site.xml中添加配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
3.yarn配置
在yarn-site.xml中添加配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
这里表示yarn存放在master,这里value中的值填什么yarn就在那里
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
--如果不是单机伪分布集群则处理一下操作
4.将etc/hadoop复制到其他节点
5.最终启动
启动
执行start-yarn.sh命令(在这之前确保HDFS已经启动,没有启动的先start-dfs.sh)。
执行成功后,通过JPS检查ResourceManager、NodeManager是否启动。
如果启动成功,通过master:8088可以打开MapReduce“应用”站点:
注意:需要配置本地Windows系统的hosts文件才能在本地使用主机名!

<未完>