原文地址:https://blog.csdn.net/and1kaney/article/details/51214219
1、业务日志相关
如果系统出现异常或者业务有异常,首先想到的都是查看业务日志
查看日志工具:
less 或者more
grep
tail -f filename 查看实时的最新内容
ps:切忌vim直接打开大日志文件,因为会直接加载到内存的
2、数据库相关
java应用很多瓶颈在数据库,一条sql没写好导致慢查询,可能就会带来应用带来致命危害。
如果出现Could not get JDBC Connection 、接口响应慢、线程打满等,
需要登录线上库,
查看数据库连接情况:show processlist,查看当前数据库的连接情况,确实由于慢查询造成,需要手动kill
3、JVM相关
java虚拟机相关的问题一般多是以下几种问题:gc时间过长、OOM、死锁、线程block、线程数暴涨等问题。一般通过以下几个工具都能定位出问题。
3.1 OOM问题
发生OOM问题一般服务都会crash,业务日志会有OutOfMemoryError。OOM一般都是出现了内存泄露,需要查看OOM时候的jvm堆的快照,如果配置了-XX:+HeapDumpOnOutOfMemoryError, 在发生OOM的时候会在-XX:HeapDumpPath生成堆的dump文件,结合MAT,可以对dump文件进行分析,查找出发生OOM的原因. 关于MAT使用不详述了,google上一堆(http://inter12.iteye.com/blog/1407492)。
ps.
1、服务器的内存一般较大,所以要保证服务器的磁盘空间大于内存大小
2、另外手动dump堆快照,可以使用命令jmap -dump:format=b,file=file_name pid 或者kill -3 pid
3.2 死锁
死锁原因是两个或者多个线程相互等待资源,现象一般是出现线程hung住,更严重会出现线程数暴涨,系统出现api alive报警等。查看死锁最好的方法就是分析当时的线程栈。
具体case 可以参考jstack命令里面的例子
用到的命令:
jps -v
jstack -l pid
3.3 线程block、线程数暴涨
jstack -l pid |wc -l
jstack -l pid |grep "BLOCKED"|wc -l
jstack -l pid |grep "Waiting on condition"|wc -l
线程block问题一般是等待io、等待网络、等待监视器锁等造成,可能会导致请求超时、造成造成线程数暴涨导致系统502等。
如果出现这种问题,主要是关注jstack 出来的BLOCKED、Waiting on condition、Waiting on monitor entry等状态信息。
如果大量线程在“waiting for monitor entry”:
可能是一个全局锁阻塞住了大量线程。
如果短时间内打印的 thread dump 文件反映,随着时间流逝,waiting for monitor entry 的线程越来越多,没有减少的趋势,可能意味着某些线程在临界区里呆的时间太长了,以至于越来越多新线程迟迟无法进入临界区。
如果大量线程在“waiting on condition”:
可能是它们又跑去获取第三方资源,迟迟获取不到Response,导致大量线程进入等待状态。
所以如果你发现有大量的线程都处在 Wait on condition,从线程堆栈看,正等待网络读写,这可能是一个网络瓶颈的征兆,因为网络阻塞导致线程无法执行。
3.3 gc时间过长
todo
先贴一个文章占坑:http://www.oracle.com/technetwork/cn/articles/java/g1gc-1984535-zhs.html
4、服务器问题
4.1 CPU
top命令(参考https://linux.cn/article-2352-1.html)
主要关注cpu的load,以及比较耗cpu的进程
由于现在服务器都是虚拟机,还要关注st(st 的全称是 Steal Time ,是分配给运行在其它虚拟机上的任务的实际 CPU 时间)

常用交互命令:
h 帮助,十分有用
R: 反向排序
x:将排序字段高亮显示(纵列)
y 将运行进程高亮显示(横行)
shift+> 或shift+<:切换排序字段
d或s: 设置显示的刷新间隔
f: 字段管理 设置显示的字段
k:kill进程
4.2 内存
free命令:
free -m -c10 -s1
-m:以MB为单位显示,其他的有-k -g -b
-s: 间隔多少秒持续观察内存使用状况
-c:观察多少次

vmstat命令:(http://man.linuxde.net/vmstat)
vmstat 1 10
1表示每隔1s输出一次,10 表示输出10次

两个参数需要关注
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量。
4.3 IO
iostat 命令(http://www.orczhou.com/index.php/2010/03/iostat-detail/)
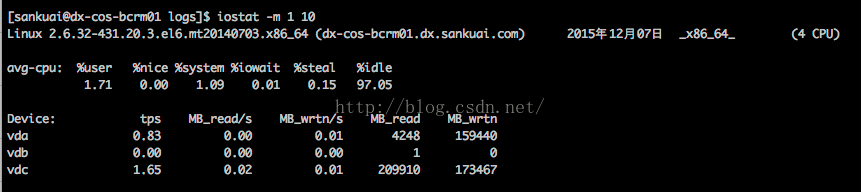
iostat -m 1 10
- -m:某些使用block为单位的列强制使用MB为单位
- 1 10:数据显示每隔1秒刷新一次,共显示10次
4.4 网络
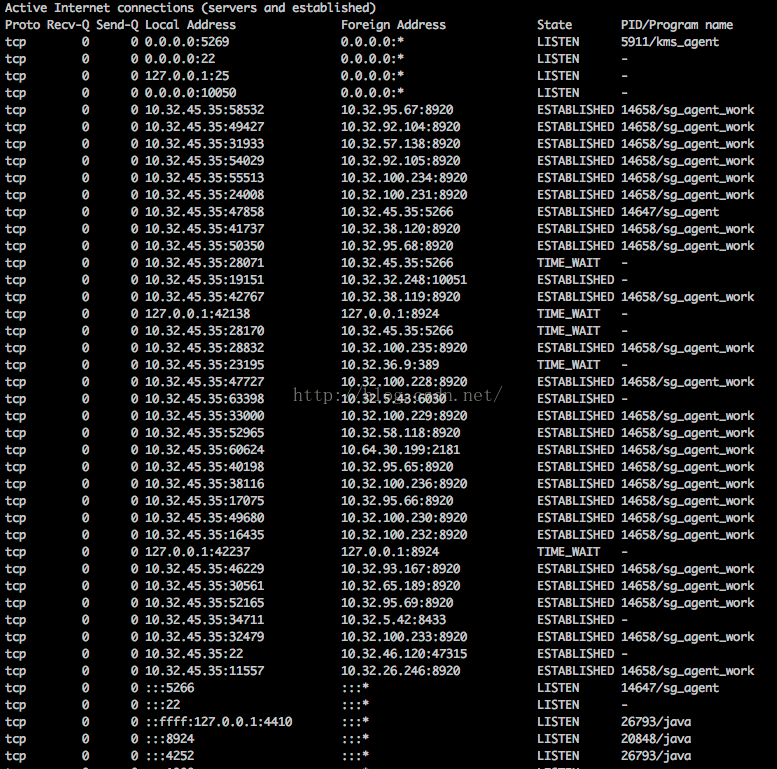
netstat 命令(http://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316661.html)
netstat -antp
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服服务状态
-p 显示建立相关链接的程序名
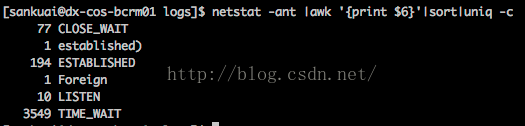
显示tcp各个状态数量:
netstat -ant |awk '{print $6}'|sort|uniq -c
查看连接某服务端口最多的的IP地址
netstat -nat | grep "10.32.45.35:8924" |awk '{print $5}'|awk -F: '{print $4}'|sort|uniq -c|sort -nr|head -10


--------------------- 本文来自 and1kaney 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/and1kaney/article/details/51214219?utm_source=copy