一、博客链接以及Github项目地址
具体分工
王锦扬负责解决方法思路的提供,何家健负责具体设计的实现
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 600分钟 | 900分钟 |
| · Estimate | · 估计这个任务需要多少时间 | 600分钟 | 900分钟 |
| Development | 开发 | 600分钟 | 2040分钟 |
| · Analysis | · 需求分析 (包括学习新技术) | 30分钟 | 50分钟 |
| · Design Spec | · 生成设计文档 | 10分钟 | 20分钟 |
| · Design Review | · 设计复审 | 20分钟 | 40分钟 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10分钟 | 10分钟 |
| · Design | · 具体设计 | 140分钟 | 200分钟 |
| · Coding | · 具体编码 | 300分钟 | 400分钟 |
| · Code Review | · 代码复审 | 60分钟 | 120分钟 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30分钟 | 60分钟 |
| Reporting | 报告 | 120分钟 | 240分钟 |
| · Test Repor | · 测试报告 | 60分钟 | 120分钟 |
| · Size Measurement | · 计算工作量 | 30分钟 | 60分钟 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30分钟 | 60分钟 |
| 合计 | 1320分钟 | 2880分钟 |
解题思路描述与设计实现说明
1.爬虫使用
本次作业中论文的爬取我们是用爬虫工具“后羿采集器”来从网页上爬取论文题目以及摘要,下图是爬取论文信息的过程
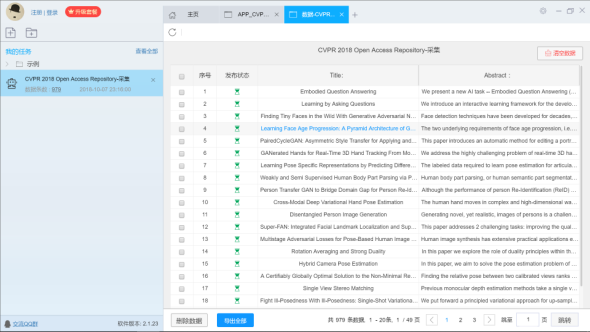
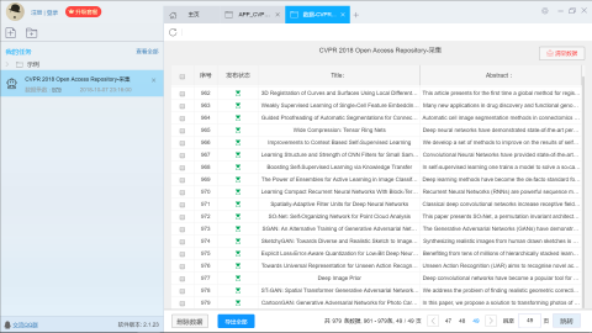
但是爬取下来之后,虽然可以导出为txt,但是却会是不符合要求的,实例如下:
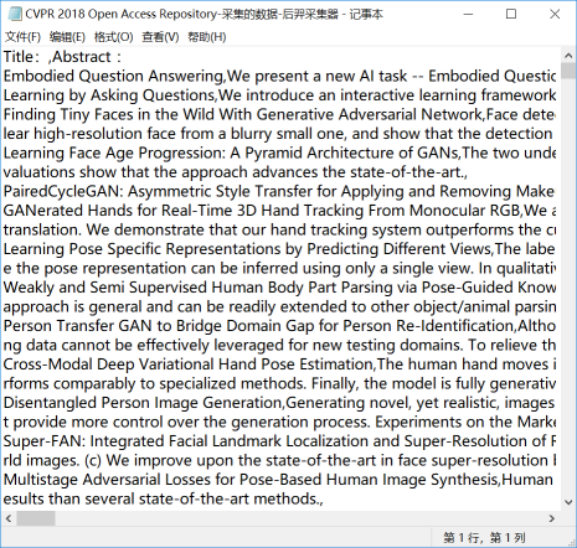
所以后来就直接导出为excle:

经过手动排版,最后转换为符合条件的txt形式。

代码组织与内部实现设计
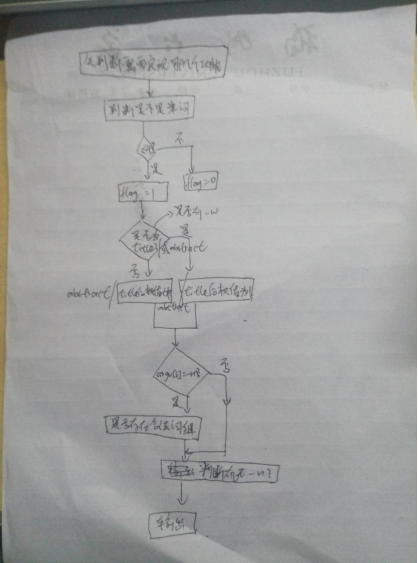
说明算法的关键与关键实现部分流程图
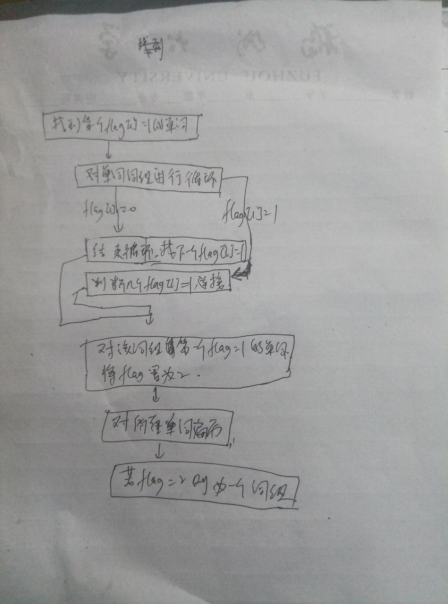
此用来判断哪一些单词可以构成词组
···
if (mm == true)
{
for (i = num - linewordsize; i < num; i++)
{
if (num - i >= m)
{
if (word[i].flag1 == 1)
{
string temp = word[i].content;
for (j = 1; j <= m - 1; j++)
{
if (word[i + j].flag1 == 1)
word[i].content = word[i].content + " " + word[i + j].content;
else if (word[i + j].flag1 == 0)
{
i = i + j; word[i].content = temp; break;
}
if (j == m - 1) word[i].flag1 = 2;
}
}
}
else break;
}
}
···
附加题设计与展示
无
关键代码解释
if (mm == true)
{
for (i = num - linewordsize; i < num; i++)
{
if (num - i >= m)
{
if (word[i].flag1 == 1)//判断是否为合法单词
{
string temp = word[i].content;
for (j = 1; j <= m - 1; j++)
{
if (word[i + j].flag1 == 1)//如果为合法单词就拼成词组
word[i].content = word[i].content + " " + word[i + j].content;
else if (word[i + j].flag1 == 0)//如果不是合法单词就break,继续遍历
{
i = i + j; word[i].content = temp; break;
}
if (j == m - 1) word[i].flag1 = 2;//如果构成合法词组,对词组的第一个合法单词做上标记
}
}
}
else break;
}
}
性能分析与改进
描述你改进的思路
用数组储存单词难以判断需要多少空间,导致有可能在测试样例巨大的情况下,导致系统的奔溃,而且运行速度回受到极大的影响,用链表可能会好一点
展示性能分析图和程序中消耗最大的函数
消耗最大的还是main函数
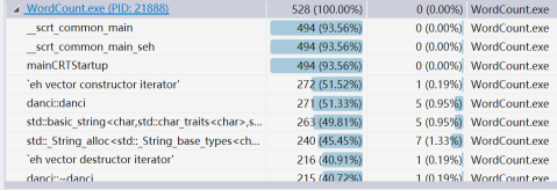
单元测试
//判断不同情况下的不同权值
if (linewordsize >= 1)
{
linenumber++;
}
if (d.find("title: ") != string::npos)
{
count = count - 7;
}
if (d.find("abstract: ") != string::npos)
{
count = count - 10;
}
if (d[0] >= 48 && d[0] <= 57) { count = count - d.size()-1;}
if ((d[0] >= 48 && d[0] <= 57) && (linenumber >= 2)) { count = count - 2; }贴出Github的代码签入记录

遇到的代码模块异常或结对困难及解决方法
问题描述
最先是数组的问题,一遇到文章多的情况基本上就会奔溃,然后是如何判断词组
做过哪些尝试
想改为链表,但因为代码比较混乱所以最终只是改变了算法的结构,判断词组用了遍历的方法跟布尔参数同时使用
是否解决
均已解决
有何收获
多做思考,多做尝试
评价你的队友
值得学习的地方
很会刻苦,愿意花很多时间在作业上面,对自己的不足会很快意识到并及时解决
需要改进的地方
并没有
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时 ) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 18.5 | 18.5 | 熟悉Axure的使用方法、对软件的原型设计有了更深刻的理解 |
| 2 | 286 | 286 | 48 | 66.5 | 学会了爬虫工具的使用,对C++string等类的功能有了更深的认识 |
| ... |