1.什么是采样
在信号系统、数字信号处理中,采样是每隔一定的时间测量一次声音信号的幅值,把时间连续的,模拟信号转换成时间离散、幅值连续的采样信号。如果采样的时间间隔相等,这种采样称为均匀采样。
在计算机系统中,有一个重要的问题就是给定一个概率分布p(x) , 我们如何在计算机中生成它的样本。平时我们接触比较多的场景是,给定一堆样本数据,求出这堆样本的概率分布p(x)。而采样刚好是个逆命题:给定一个概率分布p(x),如何生成满足条件的样本?
2.均匀分布采样
均匀分布式是一种最简单的分布。在计算机中生成[0,1]之间的伪随机数序列,就可以看做是一种均匀分布。随机数生成的方法有很多,比较简单的一种方式比如:
当然计算机中产生的随机数一般都是伪随机数,不过在绝大部分场景下也够用了。
3.离散分布采样
离散分布是比均匀分布稍微复杂一点的情况。例如令
,那么我们可以把概率分布的向量看做一个区间段,然后从
分布中采样,判断x落在哪个区间内。区间长度与概率成正比,这样当采样的次数越多,采样就越符合原来的分布。
举个例子,假设
,分别为"hello", “java”, “python”, "scala"四个词出现的概率。我们按照上面的算法实现看看最终的结果
import numpy as np
from collections import defaultdict
dic = defaultdict(int)
def sample():
u = np.random.rand()
if u <= 0.1:
dic["hello"] += 1
elif u <= 0.3:
dic["java"] += 1
elif u <= 0.6:
dic["python"] += 1
else:
dic["scala"] += 1
def sampleNtimes():
for i in range(10000):
sample()
for k,v in dic.items():
print k,v
sampleNtimes()
代码输出结果:
python 3028
java 2006
hello 971
scala 3995
上面的采样方法,基本满足我们的要求。
4. Box-Muller算法
如果概率密度分布函数 是连续分布,如果这个分布可以计算累积分布函数(Cumulative Distribution Function, CDF),可以通过计算CDF的反函数,获得采样。
如果随机变量
,
是IID独立同分布,且
,那么有:
独立且服从标准正态分布。
具体证明过程可以见参考文献2。
Box–Muller变换最初由 George E. P. Box 与 Mervin E. Muller 在1958年提出。George E. P. Box 是统计学的一代大师,统计学中的很多名词术语都以他的名字命名。Box 之于统计学的家学渊源相当深厚,他的导师是 统计学开山鼻祖 皮尔逊的儿子,英国统计学家Egon Pearson,同时Box还是统计学的另外一位巨擘级奠基人 费希尔 的女婿。统计学中的名言“all models are wrong, but some are useful”(所有模型都是错的,但其中一些是有用的)也出自Box之口
利用Box-Muller变换生成高斯分布随机数的方法可以总结为以下步骤:
1.生成两个随机数
2.令
,
3.
按上面的步骤生成正态分布的抽样:
import numpy as np
from pylab import *
def sample():
x = np.random.rand() # 两个均匀分布分别为x, y
y = np.random.rand()
R = np.sqrt(-2 * np.log(x))
theta = 2 * np.pi * y
z0 = R * np.cos(theta)
#z1 = R * np.sin(theta)
return z0
def sampleNtimes():
list = []
n = 100000
for i in range(n):
x = sample()
list.append(x)
y = np.reshape(list, n, 1)
hist(y, normed=1, fc='c') # 直方图
x = arange(-4, 4, 0.1)
plot(x, 1 / np.sqrt(2 * np.pi) * np.exp(-0.5 * x ** 2), 'g', lw=6) # 标准正态分布
xlabel('x', fontsize = 24)
ylabel('p(x)', fontsize = 24)
show()
sampleNtimes()
最后代码输出图像:
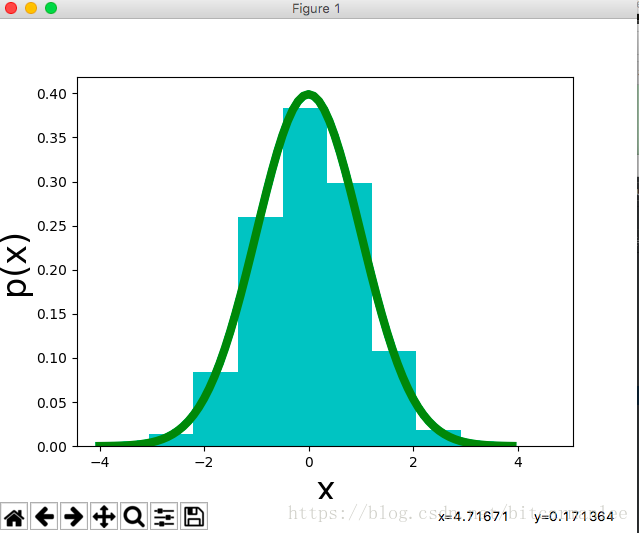
5.拒绝采样(Rejection Sampling)
假设我们已经可以抽样高斯分布q(x)(如Box–Muller_transform 算法),我们按照一定的方法拒绝某些样本,达到接近p(x)分布的目的:
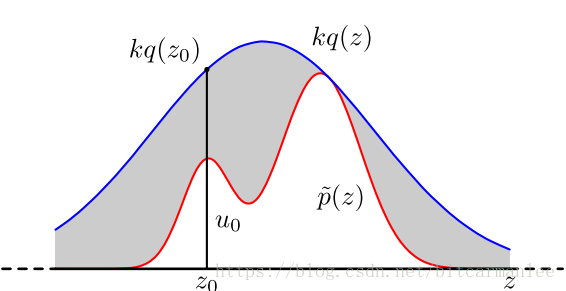
具体的步骤如下:
1.首先,确定常量k,使得p(x)总在kq(x)的下方。
2.x轴的方向:从q(x)分布抽样取得a。但是a不一定留下,会有一定的几率被拒绝。
3.y轴的方向:从均匀分布(0, kq(a))中抽样得到u。如果u>p(a),也就是落到了灰色的区域中,拒绝,否则接受这次抽样。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
def qsample():
"""使用均匀分布作为q(x),返回采样"""
return np.random.rand() * 4.
def p(x):
"""目标分布"""
return 0.3 * np.exp(-(x - 0.3) ** 2) + 0.7 * np.exp(-(x - 2.) ** 2 / 0.3)
def rejection(nsamples):
M = 0.72 # 0.8 k值
samples = np.zeros(nsamples, dtype=float)
count = 0
for i in range(nsamples):
accept = False
while not accept:
x = qsample()
u = np.random.rand() * M
if u < p(x):
accept = True
samples[i] = x
else:
count += 1
print "reject count: ", count
return samples
x = np.arange(0, 4, 0.01)
x2 = np.arange(-0.5, 4.5, 0.1)
realdata = 0.3 * np.exp(-(x - 0.3) ** 2) + 0.7 * np.exp(-(x - 2.) ** 2 / 0.3)
box = np.ones(len(x2)) * 0.75 # 0.8
box[:5] = 0
box[-5:] = 0
plt.plot(x, realdata, 'g', lw=3)
plt.plot(x2, box, 'r--', lw=3)
import time
t0 = time.time()
samples = rejection(10000)
t1 = time.time()
print "Time ", t1 - t0
plt.hist(samples, 15, normed=1, fc='c')
plt.xlabel('x', fontsize=24)
plt.ylabel('p(x)', fontsize=24)
plt.axis([-0.5, 4.5, 0, 1])
plt.show()
最终结果:
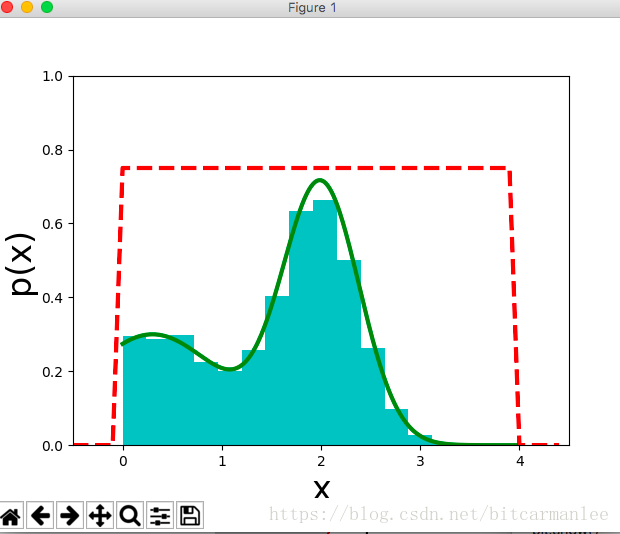
在高维的情况下,Rejection Sampling有两个问题:
1.合适的q分布很难找
2.很难确定一个合理的k值
导致拒绝率很高。
6.MCMC采样(Markov Chain Monte Carlo)
MCMC采样方法中的两个MC,分别指的是马尔可夫链Markov Chain与蒙特卡洛算法。关于蒙特卡洛算法,前面写的蒙特卡洛算法有专门分析过,见参考文献3。关于马尔可夫链见参考文献4。
之前提到的抽样方法都是可以并行的。换句话说,后面的样本跟前面的样本没关系。而MCMC是一个链式抽样的过程,每一个抽样的样本跟且只跟前面的一个样本有关系。
由平稳马尔可夫过程的结论可知:
1.不论初始状态为啥,只要该马尔科夫链收敛,第n次的抽样概率
一定会收敛到我们预期的分布
2.如果非周期马尔科夫链的状态转移矩阵P和概率分布π(x)对于所有的i,j满足:
则称概率分布π(x)是状态转移矩阵P的平稳分布。
由于马氏链能收敛到平稳分布, 于是一个很的漂亮想法是:如果我们能构造一个转移矩阵为 的马氏链,使得该马氏链的平稳分布恰好是p(x),那么我们从任何一个初始状态 出发沿着马氏链转移, 得到一个转移序列 。如果马氏链在第n步已经收敛,那么 以后的样本必然都满足p(x)分布,就达到了我们的抽样样本满足概率为p(x)分布的条件。
这个绝妙的想法在1953年被 Metropolis想到了,为了研究粒子系统的平稳性质, Metropolis 考虑了物理学中常见的波尔兹曼分布的采样问题,首次提出了基于马氏链的蒙特卡罗方法,即Metropolis算法,并在最早的计算机上编程实现。Metropolis 算法是首个普适的采样方法,并启发了一系列 MCMC方法,所以人们把它视为随机模拟技术腾飞的起点。 Metropolis的这篇论文被收录在《统计学中的重大突破》中, Metropolis算法也被遴选为二十世纪的十个最重要的算法之一。
(以上两小段来自参考文献5)
由于一般情况下,目标平稳分布
和某一个马尔科夫链状态转移矩阵Q不满足细致平稳条件
为了使细致平稳条件成立,可以这样做:
为了两边相等,可以取
这样,转移矩阵
最后就变成为:
也就是说,目标矩阵
可以通过任意一个马尔科夫链状态转移矩阵Q乘以
得到,
一般称为接受率,取值在[0,1]之间,即目标矩阵P
可以通过任意一个马尔科夫链状态转移矩阵Q以一定的接受率获得。与前面的拒绝采样比较,拒绝采样是以一个常用的分布通过一定的拒绝率获得一个非常见的分布。而MCMC则是以一个常见的马尔科夫链状态转移矩阵Q通过一定的拒绝率得到目标转移矩阵P,两者思路类似。
总结一下上面的过程,MCMC采样算法的过程为:
1.初始化马尔科夫链初始状态为
2.循环采样过程如下:
2.1 第t个时刻马尔科夫链状态为
,由转移矩阵
中采样得到
2.2 从均匀分布采样
2.3 如果
,则接受转移
,
2.4 否则不接受转移,即
以上的 MCMC 采样算法已经能很漂亮的工作了,不过它有一个小的问题:马氏链Q在转移的过程中的接受率 α(i,j) 可能偏小,这样采样过程中马氏链容易原地踏步,拒绝大量的跳转,这使得马氏链遍历所有的状态空间要花费太长的时间,收敛到平稳分布p(x)的速度太慢。有没有办法提升一些接受率呢?
假设 α(i,j)=0.1,α(j,i)=0.2, 此时满足细致平稳条件,于是
p(i)q(i,j)×0.1=p(j)q(j,i)×0.2
上式两边扩大5倍,我们改写为
p(i)q(i,j)×0.5=p(j)q(j,i)×1
看,我们提高了接受率,而细致平稳条件并没有打破!这启发我们可以把细致平稳条件中的α(i,j),α(j,i) 同比例放大,使得两数中最大的一个放大到1,这样我们就提高了采样中的跳转接受率。所以我们可以取
经过以上细微的变化,我们就得到了如下教科书中最常见的 Metropolis-Hastings 算法。
1.初始化马尔科夫链初始状态为
2.循环采样过程如下:
2.1 第t个时刻马尔科夫链状态为
,由转移矩阵
中采样得到
2.2 从均匀分布采样
2.3 如果
,则接受转移
,
2.4 否则不接受转移,即
(以上部分内容来自参考文献5)
说了这么多的理论,直接看代码
from __future__ import division
import numpy as np
import matplotlib.pylab as plt
mu = 3
sigma = 10
# 转移矩阵Q,因为是模拟数字,只有一维,所以Q是个数字(1*1)
def q(x):
return np.exp(-(x-mu)**2/(sigma**2))
# 按照转移矩阵Q生成样本
def qsample():
return np.random.normal(mu, sigma)
# 目标分布函数p(x)
def p(x):
return 0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.)**2/0.3)
def mcmcsample(n = 20000):
sample = np.zeros(n)
sample[0] = 0.5 # 初始化
for i in range(n-1):
qs = qsample() # 从转移矩阵Q(x)得到样本xt
u = np.random.rand() # 均匀分布
alpha_i_j = (p(qs) * q(sample[i])) / (p(sample[i]) * qs) # alpha(i, j)表达式
if u < min(alpha_i_j, 1):
sample[i + 1] = qs # 接受
else:
sample[i + 1] = sample[i] # 拒绝
return sample
x = np.arange(0, 4, 0.1)
realdata = p(x)
sampledata = mcmcsample()
plt.plot(x, realdata, 'g', lw = 3) # 理想数据
plt.plot(x,q(x),'r') # Q(x)转移矩阵的数据
plt.hist(sampledata,bins=x,normed=1,fc='c') # 采样生成的数据
plt.show()
最后结果:
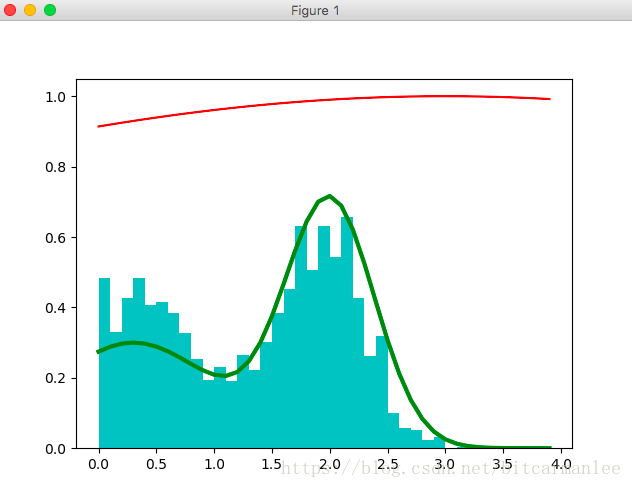
7.吉布斯采样(Gibbs)
吉布斯采样(Gibbs sampling)是统计学中用于马尔科夫蒙特卡洛(MCMC)的一种算法,用于在难以直接采样时从某一多变量概率分布中近似抽取样本序列。该序列可用于近似联合分布、部分变量的边缘分布或计算积分(如某一变量的期望值)。某些变量可能为已知变量,故对这些变量并不需要采样。
在高维的情况下,由于接受率
的存在,Metropolis-Hastings算法效率不够高。如果能找到一个转移矩阵Q使得
,那么抽样的效率会大大提高。
先看看二维的情况。假设有一个概率分布
,x坐标相同的两个点
,有:
很容易得到
即
通过上面的式子,我们发现在
这条平行于y轴的直线上,如果使用条件分布
作为任意两个点之间的转移概率,那么任意两个点之间的转移满足细致平稳条件。同理,如果在
这条直线上任意去两个点
,有如下等式
我们可以如下构造平面上任意两点之间的转移概率矩阵Q
于是这个二维空间上的马氏链将收敛到平稳分布 p(x,y)。而这个算法就称为 Gibbs Sampling 算法,是 Stuart Geman 和Donald Geman 这两兄弟于1984年提出来的,之所以叫做Gibbs Sampling 是因为他们研究了Gibbs random field, 这个算法在现代贝叶斯分析中占据重要位置。
则二维Gibbs Sampling的算法为:
1随机初始化
2.循环采样
2.1
2.2
总结起来,Gibbs sampling是 MCMC方法的一种特例。当我们采样几个变量,但是不知道其联合分布,但是知道几个变量相互之间所有的条件分布时,我们可以用其来获取一些近似观察样本。
直接看代码
from pylab import *
from numpy import *
def pXgivenY(y, m1, m2, s1, s2):
return random.normal(m1 + (y - m2) / s2, s1)
def pYgivenX(x, m1, m2, s1, s2):
return random.normal(m2 + (x - m1) / s1, s2)
def gibbs(N=5000):
k = 20
x0 = zeros(N, dtype=float)
m1 = 10
m2 = 20
s1 = 2
s2 = 3
for i in range(N):
y = random.rand(1)
# 每次采样需要迭代 k 次
for j in range(k):
x = pXgivenY(y, m1, m2, s1, s2)
y = pYgivenX(x, m1, m2, s1, s2)
x0[i] = x
return x0
def f(x):
return exp(-(x - 10) ** 2 / 10)
# 画图
N = 10000
s = gibbs(N)
x1 = arange(0, 17, 1)
hist(s, bins=x1, fc='b')
x1 = arange(0, 17, 0.1)
px1 = zeros(len(x1))
for i in range(len(x1)):
px1[i] = f(x1[i])
plot(x1, px1 * N * 10 / sum(px1), color='g', linewidth=3)
show()
效果如下
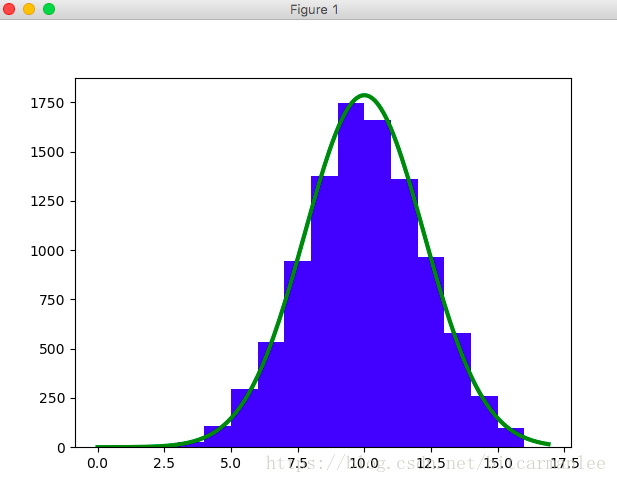
参考文献:
1.https://applenob.github.io/1_MCMC.html#MCMC
2.https://blog.csdn.net/baimafujinji/article/details/6492982
3.https://blog.csdn.net/bitcarmanlee/article/details/82716641 小白都能看懂的蒙特卡洛方法以及python实现
4.https://blog.csdn.net/bitcarmanlee/article/details/82819860 小白都能看懂的马尔可夫链详解
5.http://www.cnblogs.com/ywl925/archive/2013/06/05/3118875.html
6.https://zh.wikipedia.org/wiki/吉布斯采样