版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/nima1994/article/details/82686092
所用思路和上一个差不多,本篇基于天池论坛的这篇文章:Keras多分类联合训练+欧式距离迁移映射 ,并做了自己的处理。线上精度0.0905。
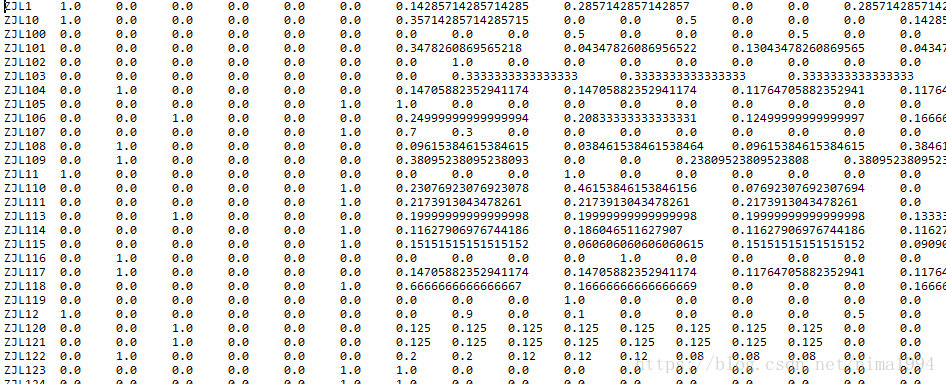
- 没有构造如
'non_1'的特征,直接使用如原来的全0特征表示,并对每类特征除和 - 使用的vgg16
处理后的特征文件如下:
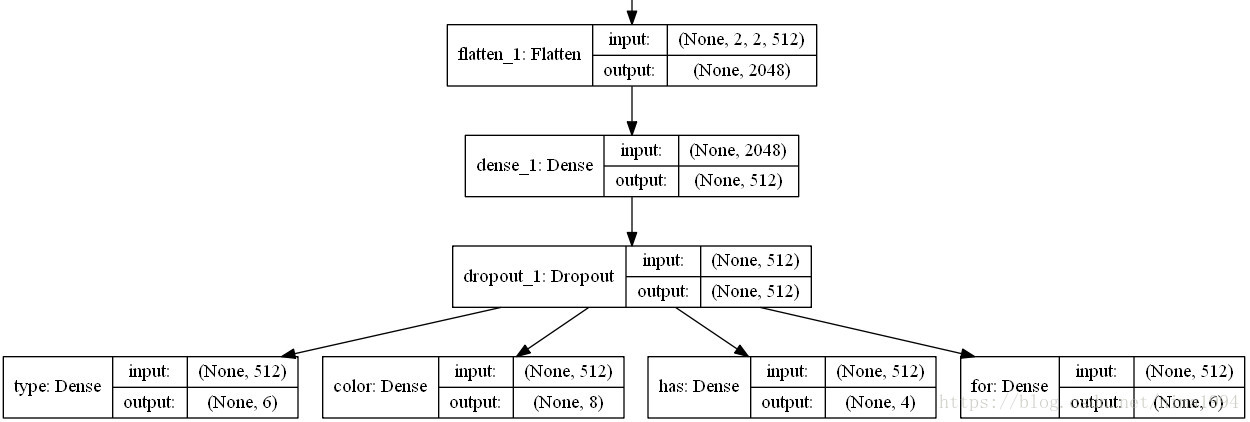
模型的关键之处在于:
该部分主要代码如下:
def normalline(data):
for i,cs in enumerate(np.sum(data,axis=1).values):
if cs!=0:
data.iloc[i,:]=data.iloc[i,:]*1.0/cs
return data
def wordsnormal():
words=pd.read_csv(r"D:\TianChi\201809ZSL\DatasetA_train_20180813\attributes_per_class.txt", header=None, sep='\t')
labels=np.array(words.iloc[:,0]).reshape(-1,1)
dentype=words.iloc[:,1:7]
dentype=normalline(dentype)
dencolor = words.iloc[:, 7:15]
dencolor=normalline(dencolor)
denhas = words.iloc[:, 15:19]
denhas = normalline(denhas)
denfor=words.iloc[:, 19:25]
denfor = normalline(denfor)
words=pd.DataFrame(np.concatenate((labels,dentype,dencolor,denhas,denfor),axis=1))
words.to_csv("../data/attributes_per_class_norm.csv",header=None,sep='\t',index=None)
可以从如下思路改进:
- 目前基于vgg16模型,不符合赛题要求,而且赛题图片是64x64的,模型提取图片特征的能力也有限。所以可以构建更复杂的单网络,进而做图片特征的merge等,从而提取更好的图片特征
- 在图片特征提取这一环,做图片的训练集和验证集,似乎验证集的结果并不好,如果打标签质量不好,是否可以考虑课程学习
- 样本属性的不同的预处理(归一化、标准化),或者如文中的分批
- 多种映射方式组合,文中仅仅基于神经网络,可以考虑将图片特征、属性特征提出从而构建不同的映射
代码上传在Github上。