Nomad是一个功能强大、灵活的调度器,适用于长期运行的服务和批处理任务。通过广泛的驱动程序,Nomad可以调度基于容器的工作负载、原始二进制文件、java应用程序等等。Nomad操作简单,易伸缩,与HashiCorp Consul(服务注册),Vault(证书管理)产品无缝集成。
Nomad为开发人员提供了自助服务基础设施。Nomad任务使用高级声明格式语法进行描述,该语法是版本控制的,并将基础结构作为代码进行推广。一旦任务提交给Nomad,它就负责部署和确保服务的可用性。运行Nomad的好处之一是提高了计算基础设施的可靠性和弹性。
欢迎来到我们关于用Nomad构建弹性基础设施的系列文章,在这里我们将探讨Nomad如何处理意外故障、停机和集群基础设施的日常维护,通常不需要操作员干预。
在第一篇文章中,我们将了解Nomad如何自动重启失败和无响应的任务,以及如何将反复失败的任务重新调度到其他节点。
Tasks and job 声明
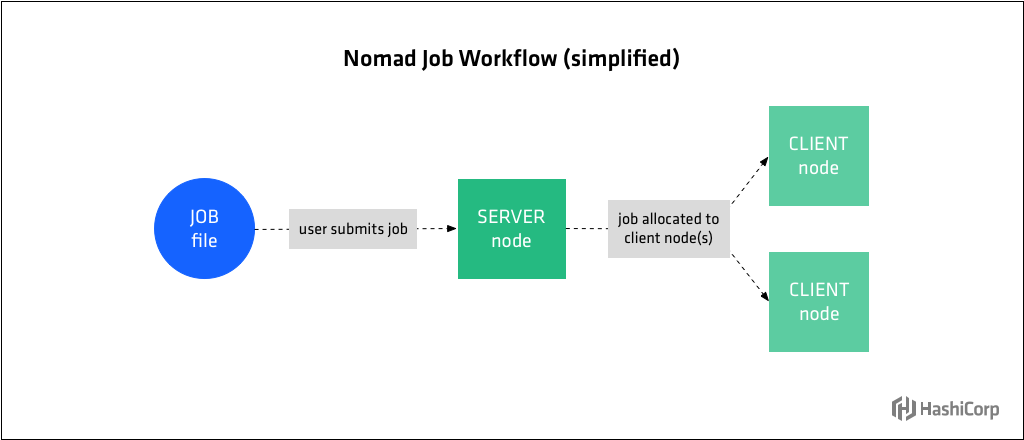
一个Nomad task是由其驱动程序在Nomad客户端节点上执行的命令、服务、应用程序或其他工作负载。task可以是短时间的批处理作业(batch)或长时间运行的服务(service),例如web应用程序、数据库服务器或API。
Tasks是在用HCL语法的声明性job规范中定义的。Job文件提交给Nomad服务端,服务端决定在何处以及如何将job文件中定义的task分配给客户端节点。另一种概念化的理解是:job规范表示工作负载的期望状态,Nomad服务端创建并维护其实际状态。
job定义的层次是:job→group→task。每个job文件只有一个job,但是一个job可能有多个group,每个group可能有多个task。group包含一组要放在同一个节点上的task。
下面是一个定义Redis工作负载的简单job文件:
job "example" {
datacenters = ["dc1"]
type = "service"
constraint {
attribute = "${attr.kernel.name}"
value = "linux"
}
group "cache" {
count = 1
task "redis" {
driver = "docker"
config {
image = "redis:3.2"
}
resources {
cpu = 500 # 500 MHz
memory = 256 # 256MB
}
}
}
}job作者可以为他们的工作负载定义约束和资源。约束(constraint)通过内核类型和版本等属性限制了工作负载在节点上的位置。资源(resources)需求包括运行task所需的内存、网络、CPU等。
有三种类型的job:system、service和batch,它们决定Nomad将用于此job中task的调度器。service 调度器被设计用来调度永远不会宕机的长寿命服务。batch作业对短期性能波动的敏感性要小得多,寿命也很短,几分钟到几天就可以完成。system调度器用于注册应该在满足作业约束的所有客户端上运行的作业。当某个客户端加入到集群或转换到就绪状态时也会调用它。
Nomad允许job作者为自动重新启动失败和无响应的任务指定策略,并自动将失败的任务重新调度到其他节点,从而使任务工作负载具有弹性。
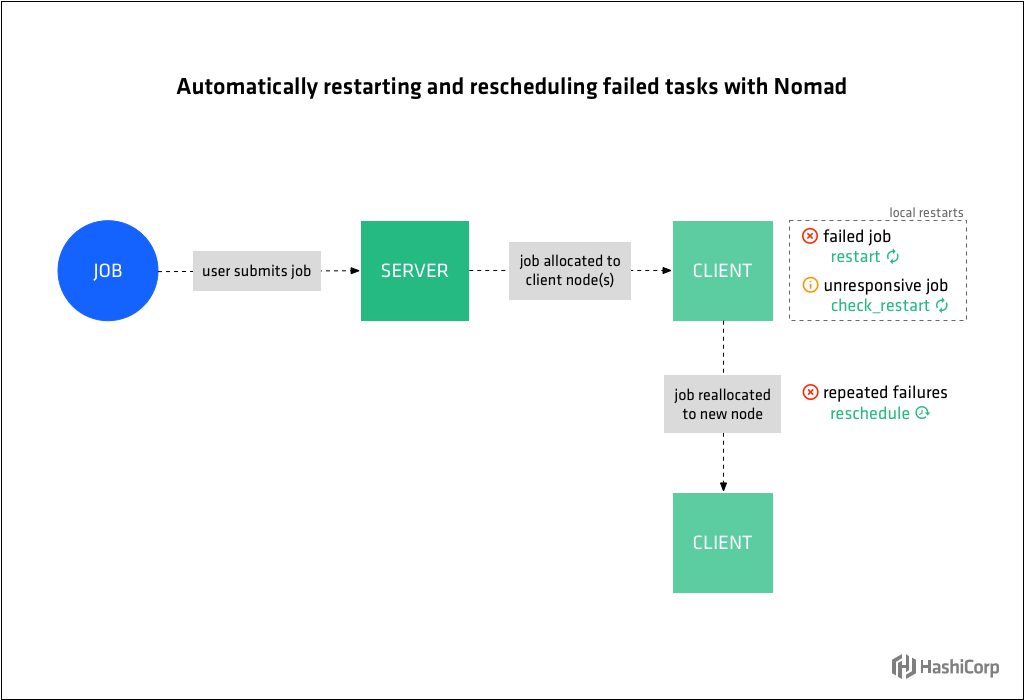
重启失败的任务
任务失败可能发生在任务未能成功完成时,例如批处理(batch)类型作业或服务(service)由于致命错误或内存耗尽而失败。
Nomad将根据job文件的restart节中的指令在同一个节点上重启失败的任务。attempts指定允许重启的次数,delay指定Nomad在重启任务之前应该等待多长时间,interval限制尝试重新启动到间隔时间的时间量。使用(fail)模式指定在给定间隔内的所有重启尝试都已耗尽之后,如果job没有运行,Nomad应该做什么。
默认的失败模式是fail,它告诉Nomad不要尝试重启job。这是对非幂等job的推荐值,这些job在几次失败后不太可能成功。另一个选项是delay,告诉Nomad在重启作业之前等待interval指定的时间。
下面的restart节告诉Nomad在30分钟内最多重启2次,每次重启之间延迟15秒,在2次重启之后不要再尝试重启。这也是非批处理类型job的默认重启策略。
group "cache" {
...
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
task "redis" {
...
}
}这种本地重启行为旨在使任务对bug、内存泄漏和其他临时问题具有弹性。这类似于使用过程管理器,例如systemd、upstart或Nomad外部的runit。
重启没有响应的任务
另一个常见的场景是需要重启一个任务,该任务还没有失败,但已经变得没有响应或不健康。
Nomad将根据check_restart节中的指令重启没有响应的任务。这将与Consul健康检查功能结合。当健康检查失败limit次时,Nomad将重启任务。limit值为1表示在第一次失败时重启。默认值0则表示禁止基于健康检查的重启。
失败必须是连续的。一次健康检查将重置计数,因此在passing状态和失败状态之间交替进行的服务可能不会重启。使用grace指定重启后恢复健康检查的等待时间。设置 ignore_warnings = true 让Nomad将警告状态当作一个passing状态,而不触发重启。
下面的check_restart策略告诉Nomad在其健康检查连续失败3次后重启Redis任务,在重启任务后等待90秒以恢复健康检查,并在警告状态下重启(除了失败之外)。
task "redis" {
...
service {
check_restart {
limit = 3
grace = "90s"
ignore_warnings = false
}
}
}在传统的数据中心环境中,重启失败的任务通常由流程管理器(process supervisor)处理,该管理器需要由操作员配置。自动检测和重新启动不健康的任务更加复杂,需要定制脚本集成监控系统或操作员干预。而对于Nomad,它们会自动发生,不需要操作员干预。
重新调度失败任务
在指定的重启次数之后没有成功运行的任务可能会失败,原因是它们运行的节点出现了问题,例如硬件故障、内核死锁或其他不可恢复的错误。
使用reschedule节,操作员告诉Nomad在什么情况下要将失败的作业重新调度(reschedule)到另一个节点。
Nomad更喜欢重新调度到以前没有用于此任务的节点。与restart节一样,您可以使用attempts指定Nomad应该尝试的重新调度的次数,delay指定Nomad应该在重新调度尝试之间等待多长时间,interval指定重新调度尝试限制的间隔时间。
另外,使用delay_function指定用于计算初始延迟后的后续重新调度尝试的函数。选项有常数(constant)、指数(exponential)和斐波那契数(fibonacci)。对于service任务,斐波那契调度具有快速重新调度的特性,它可以在短时间内从中断中恢复,同时减慢速度以避免在较长时间内中断时出现中断。当使用指数或斐波那契delay_function时,使用max_delay设置延迟时间的上限,在此之后延迟时间不会增加。将unlimited设置为true或false以允许无限制的重新调度尝试。
要完全禁用重新调度,设置 attempts = 0 和 unlimited = false。
下面的reschedule 节告诉Nomad尝试重新调度任务组无限次,并在随后的尝试之间以指数级增加延迟,开始延迟30秒,最多1小时。
group "cache" {
... reschedule {
delay = "30s"
delay_function = "exponential"
max_delay = "1hr"
unlimited = true
}
}
reschedule 节不适用于system作业,因为它们在每个节点上都运行。
从Nomad 0.8.4版本开始,reschedule 节在部署期间应用。
在传统的数据中心中,节点故障将由监控系统检测到,并触发报警给操作员。然后操作人员需要手动进行干预,要么恢复失败的节点,要么将工作负载迁移到另一个节点。有了重新调度功能,操作员可以为最常见的故障场景进行规划,Nomad将自动响应,无需人工干预。Nomad应用了合理的默认值,这样大多数用户都可以在本地重新启动和重新调度,而不必考虑各种重启参数。
总结
在我们用Nomad构建弹性基础架构系列的第一篇文章中,我们介绍了Nomad如何通过自动重新启动和重新调度失败和无响应的任务,为计算基础架构提供弹性。
对于失败的任务,操作员使用restart节指定Nomad的本地重启策略。当与Consul和check_restart节一起使用时,Nomad将根据重启参数在本地重启无响应的任务。操作员通过reschedule 节指定Nomad重新调度失败任务的策略。
在下一篇文章中,我们将讨论Nomad客户端如何通过驱动健康检查和活跃的心跳来实现快速、准确的调度以及自我修复。