本文主要讲述以下 几个内容:
www 到底做了那些贡献而走向全世界
URL 与 URI
DNS
服务器与浏览器如何沟通
curl 命令 与 请求和响应的羁绊
http请求的格式
http响应的格式
一. www (World Wide Web)
在网页出来之前,人们是通过邮件交流信息的,www 组织是如何做到只要输入网址就能浏览网页的?用了这么多年浏览器,这真是一个令人匪夷所思的事件!!!那我们来看看到底是谁做了哪些神奇的事情,才让我们有机会处于一个信息时代。
传说,Tim Berners-Lee 在 90年左右发明了第一个页面 ,第一个服务器,第一个浏览器,这是一个简单而完美的系统,现代浏览器的雏形,至此以后便打开了一个新的世界,WWW可以让web客户端(常用浏览器)访问浏览器web服务器上的页面,是一个由许多互相链接的超文本组成的系统,通过互联网的访问。在这个系统中,每个有用的事物,称为“资源”,并且由一个全局统一资源标识符(URI:Uniform Resource Identifier)标识,这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而用户通过点击链接来获得资源。
万维网不等同于互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
www核心三个概念:
URI,俗称网址,能让你访问一个页面
HTTP,两个电脑之间传输内容的协议,让你能下载这个页面
HTML,超级文本,主要用来做页面跳转, 让你能看懂这个页面。
二.URL 与 URI
URI(Uniform Resource Identifier),统一资源标识符,就是方便找到资源,分为 URL 和 URN。
URL(Uniform Resource Locator), 统一资源定位符,就是给我们一个地址,一般使用URL作为网址。
那问题来了,URN是什么玩意??Uniform Resource Name,统一资源名称,为每个资源取一个ISBN编号,如果要是用它,我们得知道这个编号啊,那么当然URL首选,你直接搜不就行了。
URL的常见组成如下:

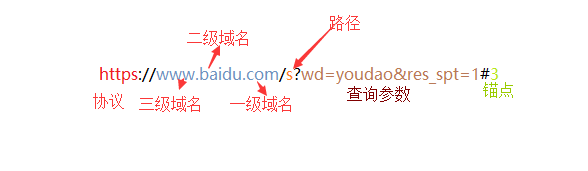
三.DNS
当输入网址后,不是说只输入网址就可以找到资源,需要找到资源对应的服务器,因为资源是从服务器获取的,必须找到该服务器的IP地址才能拿到资源,所以浏览器必须查找IP地址,
网址上咋就没有IP呢,emm....每个电脑都有ip,如果把电脑当做手机,ip就是电话号码,哈哈哈哈哈哈嗝,再问,域名是什么,查了一下,哦,原来域名可是理解为IP地址的代称,比如,http://wikipedia.org是一个域名,然后和某地址相对应,一个域名可以对应多个IP,只要找到一个就可以了。
为什么不直接使用IP呢???
原来因为IP太难记了,所以产生了域名这一种字符型标识,它比IP地址更容易记忆。
浏览器是怎么通过域名找IP的?
DNS(Domain Name System)就牛逼哄哄的出现了,他就是来解决这个问题的,DNS域名系统,记住这个DNS!
可以通过命令行来找到百度的IP : nslookup baidu.com ,输出 Address: 220.181.57.216,百度有很多台服务器,所以每个人输出的地址都不一样,他会找离你最近的服务器!!
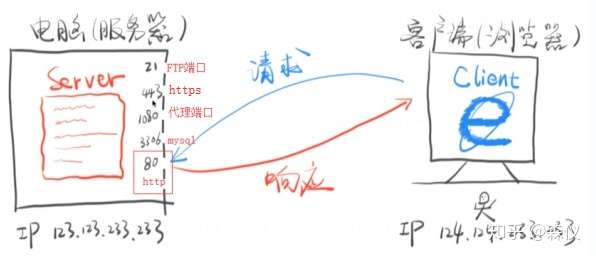
四.服务器 和浏览器如何沟通
Server + Client + http
-
浏览器负责发起请求
-
服务器在 80 端口接收请求
-
服务器负责返回内容(响应)
-
浏览器负责下载响应内容
HTTP 的作用就是指导浏览器和服务器如何进行沟通,http负责规定请求报文上该怎么写,响应报文该怎么写,
当访问一个网页时,浏览器会向网页所在服务器发出请求,当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
服务器有很多接口,每个接口有固定的用法。

五. curl 命令 与 请求和响应的羁绊
curl 转到一个URL
-s(slient): 你安静一点,不要给我显示进度或者错误信息
-v(verbose):详细的,繁琐的,显示请求和响应,以 “>”开头的为请求信息,"<"开头的为相应信息,“*”开头的为注释内容,
-d <data>: 向服务器发送数据curl -X POST -d "1234567890" -s -v -H "Frank: xxx" -- "https://www.baidu.com"
-H(header)"senyi:XXX" 添加一个请求头
-X <command> 指定请求方法,默认get,想要POST 则为 -X POST
示例: curl -s -v -H "senyi: xxx" -- "https://www.baidu.com"


示例:curl -X POST -d "1234567890" -s -v -H "Frank: xxx" -- "https://www.baidu.com"
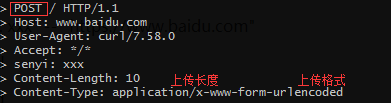

x-www-for.....x 表示没有写入的格式,用urencode的形式压缩
实例:curl -s -v -H -- "https://www.baidu.com?wd=javascript"
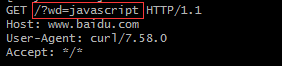

示例:curl -s -v -H -- "https://www.baidu.com?wd=javascript#4",服务器不看锚点,是浏览器看的
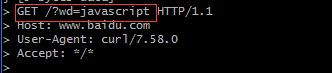

六.请求的格式
1 动词 路径 协议/版本
2 Key1: value1
2 Key2: value2
2 Key3: value3
2 Content-Type: application/x-www-form-urlencoded
2 Host: www.baidu.com
2 User-Agent: curl/7.54.0
3
4 要上传的数据-
请求最多包含四部分,最少包含三部分。(也就是说第四部分可以为空)
-
第三部分永远都是一个回车(\n)用于区分第二部分和第四部分,第四部分可能是密码
-
动词有 GET POST PUT PATCH DELETE HEAD OPTIONS 等
-
put 整体更新,patch 局部更新
-
这里的路径包括「查询参数」,但不包括「锚点」
-
如果你没有写路径,那么路径默认为 /
-
第 2 部分中的 Content-Type 标注了第 4 部分的格式
-
第 2 部分中的 Content-Type 遵循 MIME 规范
使用google查看请求内容:
f12 > network > 打开任意get请求,查看Request Headers ,点击view source查看源代码!
用户登录发送请求:选择preserve log



ps:请求和响应的四部分中 前三个在headers里面,第四部分在response里面
七.响应的格式
1 协议/版本号 状态码 状态解释
2 Key1: value1
2 Key2: value2
2 Content-Length: 17931
2 Content-Type: text/html 第四部分的格式
3
4 要下载的内容-
GET 请求和 POST 请求对应的响应可以一样,也可以不一样
-
响应的第四部分可以很长很长很长
-
第 2 部分中的 Content-Type 标注了第 4 部分的格式
-
第 2 部分中的 Content-Type 遵循 MIME 规范
-
状态码要背,是服务器对浏览器说的话
-
1xx 不常用
-
2xx 表示成功
-
3xx 表示滚吧, 301永久不在了,302暂时不在,304和上次返回的一样
-
4xx 表示你丫错了
-
5xx 表示好吧,我错了 服务器出错
示例:
