版权声明:转载请联系博主。 https://blog.csdn.net/sunyaowu315/article/details/82979073
视频网站数据清洗整理和结论研究
要求:
1、数据清洗 - 去除空值
- 要求:创建函数
- 提示:fillna方法填充缺失数据,注意inplace参数
2、数据清洗 - 时间标签转化
- 要求:
① 将时间字段改为时间标签
② 创建函数 - 提示:
需要将中文日期转化为非中文日期,例如 2016年5月24日 → 2016.5.24
3、问题1 分析出不同导演电影的好评率,并筛选出TOP20
- 要求:
① 计算统计出不同导演的好评率,不要求创建函数
② 通过多系列柱状图,做图表可视化 - 提示:
① 好评率 = 好评数 / 评分人数
② 可自己设定图表风格
4、问题2 统计分析2001-2016年每年评影人数总量
- 要求:
① 计算统计出2001-2016年每年评影人数总量,不要求创建函数
② 通过面积图,做图表可视化,分析每年人数总量变化规律
③ 验证是否有异常值(极度异常)
④ 创建函数分析出数据外限最大最小值)
⑤ 筛选查看异常值 → 是否异常值就是每年的热门电影? - 提示:
① 通过箱型图验证异常值情况
② 通过quantile(q=0.5)方法,得到四分位数
③ IQR=Q3-Q1
④ 外限:最大值区间Q3+3IQR,最小值区间Q1-3IQR (IQR=Q3-Q1)
⑤ 可自己设定图表风格
一 导入python包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
% matplotlib inline
二 数据读取
data = pd.read_csv('C:/Users/Hjx/Desktop/爱奇艺视频数据.csv', engine = 'python')
print(data.head())

三 数据清洗
1 去除空值
文本型字段空值改为“缺失数据”,数字型字段空值改为 0
- 要求:创建函数
- 提示:fillna方法填充缺失数据,注意inplace参数
def data_cleaning(df):
cols = df.columns
for col in cols:
if df[col].dtype == 'object':
df[col].fillna('缺失数据', inplace = True)
else:
df[col].fillna(0, inplace = True)
return(df)
- 该函数可以将任意数据内空值替换
data_c1 = data_cleaning(data)
print(data_c1.head(10))

2 时间标签转化
将时间字段改为时间标签
- 要求:创建函数
- 提示:需要将中文日期转化为非中文日期,例如 2016年5月24日 → 2016.5.24
def data_time(df,*cols):
for col in cols:
df[col] = df[col].str.replace('年','.')
df[col] = df[col].str.replace('月','.')
df[col] = df[col].str.replace('日','')
df[col] = pd.to_datetime(df[col])
return(df)
- 该函数将输入列名的列,改为DatetimeIndex格式
data_c2 = data_time(data_c1,'数据获取日期')
print(data_c2.head(10))

四 统计分析
- 问题1 分析出不同导演电影的好评率,并筛选出TOP20
- 要求:
① 计算统计出不同导演的好评率,不要求创建函数
② 通过多系列柱状图,做图表可视化 - 提示:
① 好评率 = 好评数 / 评分人数
- 要求:
df_q1 = data_c2.groupby('导演')[['好评数','评分人数']].sum()
df_q1['好评率'] = df_q1['好评数'] / df_q1['评分人数']
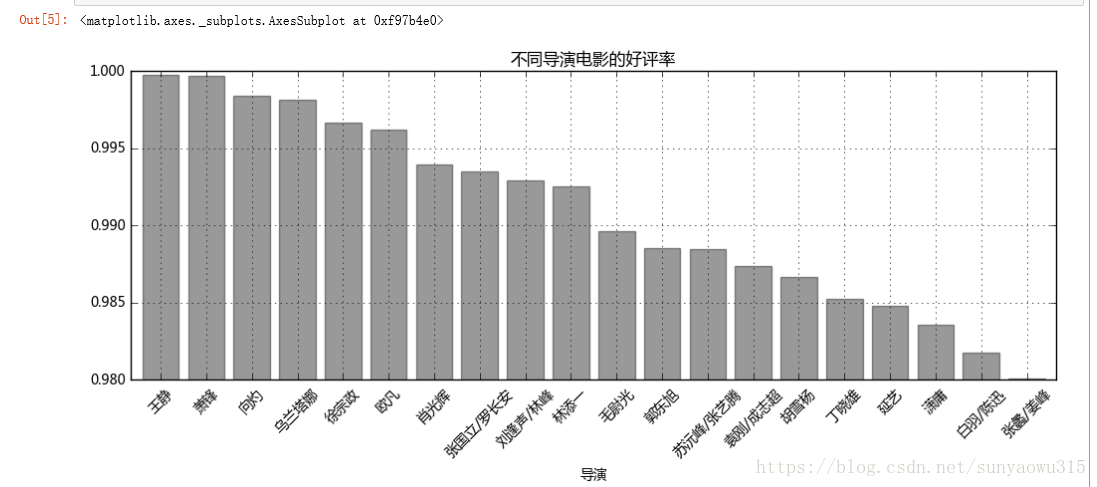
result_q1 = df_q1.sort_values(['好评率'], ascending=False)[:20]
- 计算统计不同导演的好评率
result_q1['好评率'].plot(kind='bar',
color = 'k',
width = 0.8,
alpha = 0.4,
rot = 45,
grid = True,
ylim = [0.98,1],
figsize = (12,4),
title = '不同导演电影的好评率')
- 问题2 统计分析2001-2016年每年评影人数总量
- 要求:
① 计算统计出2001-2016年每年评影人数总量,不要求创建函数
② 通过面积图,做图表可视化,分析每年人数总量变化规律
③ 验证是否有异常值(极度异常)
④ 创建函数分析出数据外限最大最小值)
⑤ 筛选查看异常值 → 是否异常值就是每年的热门电影? - 提示:
① 通过箱型图验证异常值情况
② 通过quantile(q=0.5)方法,得到四分位数
③ IQR=Q3-Q1
④ 外限:最大值区间Q3+3IQR,最小值区间Q1-3IQR (IQR=Q3-Q1)
- 要求:
q2data1 = data_c2[['导演','上映年份','整理后剧名']].drop_duplicates()
q2data1 = q2data1[q2data1['上映年份'] != 0]
- 筛选出不同年份的数据,去除‘上映年份’字段缺失数据
q2data2 = data_c2.groupby('整理后剧名').sum()[['评分人数','好评数']]
#print(q2data2)
- 求出不同剧的评分人数、好评数总和
q2data3 = pd.merge(q2data1,q2data2,left_on='整理后剧名',right_index=True)
#print(q2data3)
- 合并数据,得到不同年份,不同剧的评分人数、好评数总和
q2data4 = q2data3.groupby('上映年份').sum()[['评分人数','好评数']]
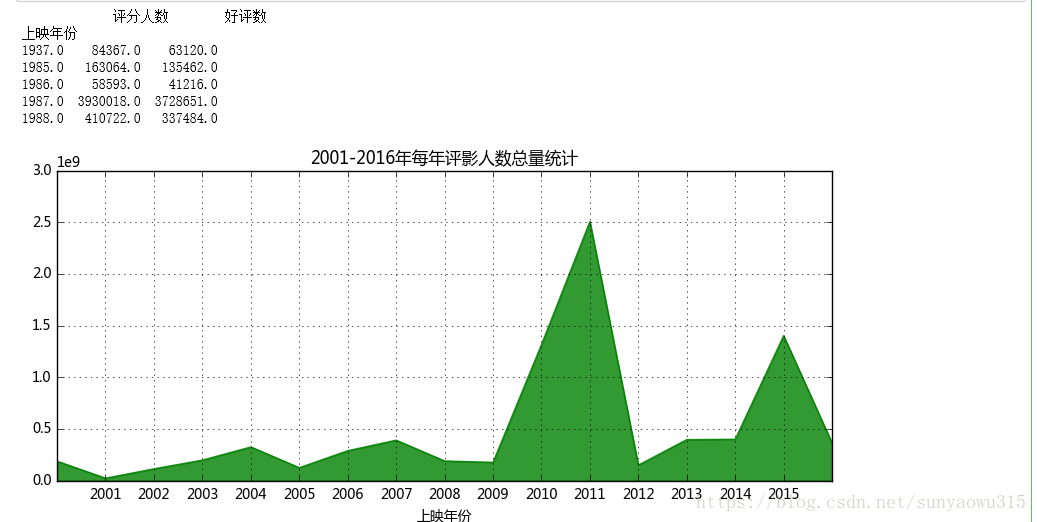
print(q2data4.head())
- 按照电影上映年份统计,评分人数量
fig1 = plt.figure(num=1,figsize=(12,4))
q2data4['评分人数'].loc[2000:].plot.area(figsize = (10,4),
grid = True,
color = 'g',
alpha = 0.8)
plt.xticks(range(2001,2016))
plt.title('2001-2016年每年评影人数总量统计')
- 创建面积图
- 每年影评人数通过每个电影来判断是否合理?
- 存在异常值,哪些是异常值?
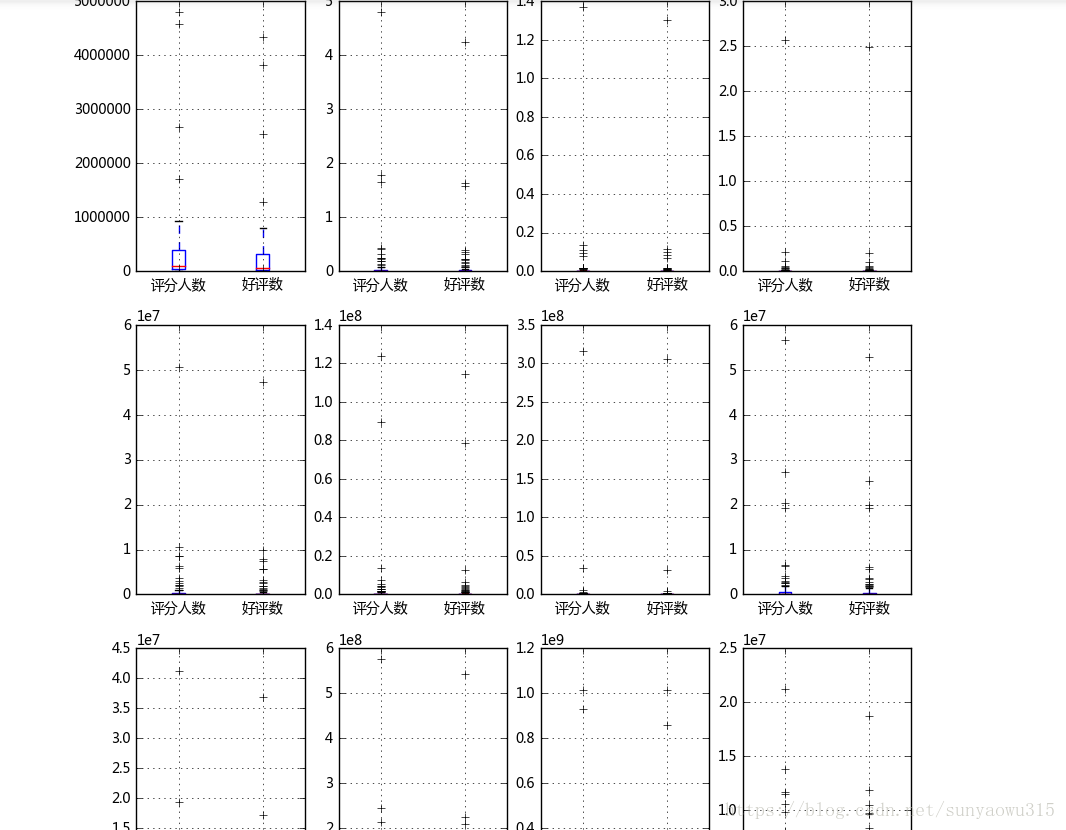
fig,axes = plt.subplots(4,4,figsize=(10,16))
start = 2001
for i in range(4):
for j in range(4):
data = q2data3[q2data3['上映年份'] == start]
data[['评分人数','好评数']].boxplot(whis = 3, # IQR为3
return_type='dict',ax = axes[i,j]) # 创建矩阵箱型图
start += 1
- 发现基本每年的数据中都有异常值,且为极度异常
- 创建函数得到外限最大最小值
- 查看异常值
a = q2data3[q2data3['上映年份'] == 2001]
def data_error(df,col):
q1 = df[col].quantile(q=0.25) # 上四分位数
q3 = df[col].quantile(q=0.75) # 下四分位数
iqr = q3 - q1 # IQR
tmax = q3 + 3 * iqr # 外限最大值
tmin = q3 - 3 * iqr # 外限最小值
return(tmax,tmin)
- 创建函数,得到外限最大最小值
for i in range(2000,2016):
datayear = q2data3[q2data3['上映年份'] == i] # 筛选该年度的数据
print('%i年有%i条数据' % (i,len(datayear))) # 查看每年的数据量
t = data_error(datayear,'评分人数') # 得到外限最大最小值
#print(t)
print(datayear[datayear['评分人数'] > t[0]]) # 查看评分人数大于外限最大值的异常值
print('-------\n')
- 查看异常值信息
