【思考点滴】
作者 : 杨考 微信号 : devin_cn_hd_09_16
一、背景
今天接到一个非常逗比的需求,按时间顺序展示一个订单的状态、信息流转顺序。

需求很明确,数据很模糊,而且是多个数据来源,还需要一定的去重、非去重之后,将有效数据保留下来。
看着需求就有点吐血。
二、数据来源
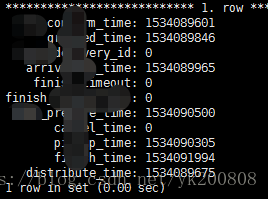
1. 数据来源 1 : order_brief 订单概要信息
亲们忍受一下,凑合着看吧,需要数据脱敏,所有关键信息都是秒级的,且有时间可能重复
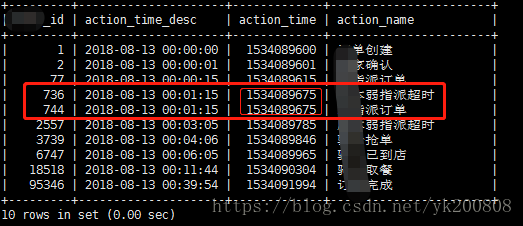
2. 数据来源 2 : order_status 表,订单状态变更表
记录的时间是秒级,且时间是有可能重复,重复部分已经使用红色标记出来了。
3. 数据来源 3 : 日志
日志中还定义了一些其它没有出现在 order_brief 和 order_status 表中的信息,也需要把这部分时间摘出来,和如上的时间合并,并按照时间顺序进行展示
三、产品需求
以 order_brief 中时间为主,将 order_status 和 日志中的关键信息【在order_brief中没有的】插入到 order_brief的时间序列中。
四、需求痛点
1、【一条SQL数据】order_brief 中的信息,如何做到重复,且按合理的次序保留出一个正确的操作顺序呢?
时间重复的操作,要保留,且要生成一个合理的操作顺序。
2、【多条SQL数据】order_status中,首先不能和 order_brief 中的操作重复的剔除,这里通过时间重复来剔除【从理论上来讲,也将 order_status中的部分合理数据剔除了,但实际业务很少有秒级重复的数据,忽略】
order_status 内部的,需要提取出来的数据,如下图中标红的部分,需要保留,且按顺序保留。
3、 【多条日志数据】将日志中的关键信息插入到如上的<order_brief , order_status> 的时间序列中,且不能和如上两个的时间重复,自己内部的有效重复数据,也需要按实际情况展示出来。基本需求同 【order_status表】。
五、设计方案
1. 头疼
2. order_brief 表的处理方案
通过 SQL 语句中的 field 字段,做排序,处理时间的时候,也是以这个field字段的顺序进行保留。
对操作时间进行计数统计,每多一个重复的秒级时间,则计数器加一。
排序时, <操作真实时间 * 1000 + 当前技术器的值 + 600> 这样就可以保证相同秒级时间的操作记录的顺序了。
关于 : 600、300 的解释 : 即 如果 order_brief、order_status 、和日志中的秒级时间重复了,此时都会生成唯一值,且order_brief的自然会排在最后,order_status的排在中间,日志的排在最前面。
3. order_status 表处理方案 1 :利用现有资源 xxx_id 结合起来做唯一且有序值
order_status表,利用 (action_time + (xxx_id%1000)) 作为内部保证序列的关键,因为 xxx_id 是升序的。但是xxx_id位数不确定,因此同一阶段后三位。
缺点 : xxx_id % 1000 存在翻转的可能,即 相同时间的几个 xxx_id 分别为 <108985、109006、109023>,这样截取之后的值分别为 <985、 6、 23> 这样原有次序就展示错误了。
4. order_status 处理方案2:
对 action_time 进行计数统计,每多一个重复的秒级时间,则计数器加一。
排序时, <真实时间 * 1000 + 当前技术器的值 + 300> 这样就可以保证相同秒级时间的操作记录的顺序了。
关于 : 600、300 的解释 : 即 如果 order_brief、order_status 、和日志中的秒级时间重复了,此时都会生成唯一值,且order_brief的自然会排在最后,order_status的排在中间,日志的排在最前面。
5. 日志记录的处理方案:
对重复时间【秒级】进行计数统计
排序时, <真实时间 * 1000 + 当前技术器的值 > 这样就可以保证相同秒级时间的操作记录的顺序了。
关于 : 600、300 的解释 : 即 如果 order_brief、order_status 、和日志中的秒级时间重复了,此时都会生成唯一值,且order_brief的自然会排在最后,order_status的排在中间,日志的排在最前面。
大致方案已经定型了
六、三个数据来源的关系处理就很简单了
1.order_brief 表处理
中的时间重复数据,保留,且生成唯一值保证顺序
2.order_status 表处理
如果有和 order_brief中时间重复的,则丢弃,不重复,则保留,且生成唯一值保证顺序
3.日志处理:
如果有和 order_brief中时间重复的,则丢弃,不重复,则保留,且生成唯一值保证顺序
七、编码
<?php
class TimeSeq
{
/**
* 将订单流程按照时间顺序进行排列
* 原有时间戳是秒级,后面扩充3位,扩充原理相减每个函数
*
* @param $resOrderInfo
* @param $timeVal_s
* @param $timeOffset // 为了按时间顺序排列,后面添加3位数字而已
* @param $timeName
* @param $desc
* @param int $deliveryId
*/
private static function addSeq(&$resOrderInfo, $timeVal_s, $timeName, $desc, $deliveryId, $timeOffset)
{
if( $timeOffset >= 0 ) {
$timeOffset = $timeOffset % 1000;
}
$time_seq = $timeVal_s * 1000 + $timeOffset; // 这里生成一个有序的key,仅仅是为了排序,而非真正的时间,真正的时间在 time_value 里并没有改变
$newArr = array('time_name' => $timeName,
'time_value' => $timeVal_s,
'desc' => $desc,
'delivery_id' => $deliveryId
);
$resOrderInfo['time_seq'][$time_seq] = $newArr;
}
1.order_brief的处理函数
/**
* 订单关键节点时间展示,以 order_brief 为主,同时穿插渗入 order_status 的非重复的订单状态变更信息
* 该函数收集 order_brief 中的订单时间信息
*
* @param $resOrderInfo
* @param $timeVal_s
* @param $timeName
* @param $desc
* @param int $deliveryId
*/
public static function timeSeq_OrderBrief(&$resOrderInfo, $timeVal_s, $timeName, $desc, $deliveryId = 0)
{
$timeOffset = 600; // 默认 600 ,而 order_status 默认是 300,主要是让重复时间, order_status 的信息在 order_brief 信息之前展示
// 使用 ‘time_seq_order_brief’ 做临时信息,用来将 order_brief 中的重复时间变为唯一信息,且可排序。
if( isset($resOrderInfo['time_seq_order_brief'][$timeVal_s]) ) {
$resOrderInfo['time_seq_order_brief'][$timeVal_s] = $resOrderInfo['time_seq_order_brief'][$timeVal_s] + 1;
} else {
$resOrderInfo['time_seq_order_brief'][$timeVal_s] = 1;
}
self::addSeq($resOrderInfo, $timeVal_s, $timeName, $desc, $deliveryId, ($timeOffset + $resOrderInfo['time_seq_order_brief'][$timeVal_s]));
}
2.order_status的处理函数
/**
* 订单关键节点时间展示,以 order_brief 为主,同时穿插渗入 order_status 的非重复的订单状态变更信息
* 该函数收集 order_status 中的订单时间信息
*
* @param $resOrderInfo
* @param $timeVal_s
* @param $timeName
* @param $desc
* @param int $deliveryId
* @param int $timeOffset
*/
public static function timeSeq_OrderStatus(&$resOrderInfo, $timeVal_s, $timeName, $desc, $deliveryId = 0)
{
$timeOffset = 300; // 默认 300 ,而 order_brief 默认是 600,主要是让重复时间, order_status 的信息在 order_brief 信息之前展示
if( isset($resOrderInfo['time_seq_order_brief'][$timeVal_s]) ) { // order_status 和 order_brief 重复的时间,不做展示
return;
}
// 使用 ‘time_seq_order_status’ 做临时信息,用来将 order_status 中的重复时间按照原有的顺序保留下来。
if( isset($resOrderInfo['time_seq_order_status'][$timeVal_s]) ) { // order_status 内部自身不能去重,而且还要注意次序
$resOrderInfo['time_seq_order_status'][$timeVal_s] = $resOrderInfo['time_seq_order_status'][$timeVal_s] + 1;
} else {
$resOrderInfo['time_seq_order_status'][$timeVal_s] = 1;
}
self::addSeq($resOrderInfo, $timeVal_s, $timeName, $desc, $deliveryId, ($timeOffset + $resOrderInfo['time_seq_order_status'][$timeVal_s]));
}
3.按定制的时间进行排序
public static function timeSeqSortUniq(&$resOrderInfo)
{
if( !isset($resOrderInfo['time_seq']) ) {
return;
}
if( empty($resOrderInfo['time_seq']) ) {
return;
}
3.1 删除 order_brief 的 临时数据
unset($resOrderInfo['time_seq_order_brief']);
3.2 删除 order_brief 的 临时数据
unset($resOrderInfo['time_seq_order_status']);
3.3 按指定的时间进行排序,生成时间升序的操作信息
ksort($resOrderInfo['time_seq']);
return;
}
}
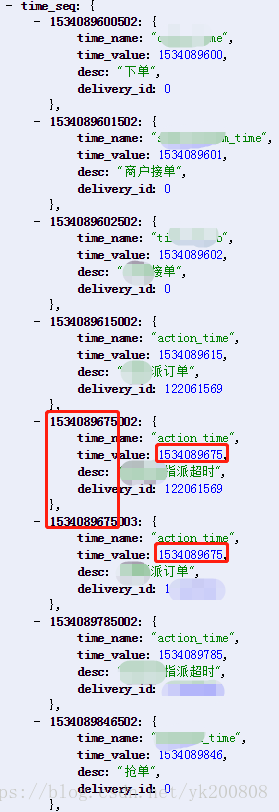
八、生成数据结果
九、延伸扩展
1. 多种数据来源的,按照某个维度的,程序处理排序,均可借鉴
2. 分布式唯一ID的生成器,其实也是相同的道理。
<时间戳【秒级、毫秒级】 + 计数器 【可以连续、也可以跳变】+ N【指定的offset】>
这个公式不仅可以应用于一个server,同样也可以应用于多个server。
十、总结
总结的话不多说了,唯一一点,朝着需求的方向努力一起做好需求,才是真正的提升