一、CPU和GPU的区别
- CPU (Central Processing Unit) 即中央处理器
- GPU (Graphics Processing Unit) 即图形处理器
- GPGPU全称General Purpose GPU,即通用计算图形处理器。其中第一个“GP”通用目的(GeneralPurpose)而第二个“GP”则表示图形处理(GraphicProcess)
CPU虽然有多核,但总数没有超过两位数,每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件;
GPU的核数远超CPU,被称为众核(NVIDIA Fermi有512个核)。每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单(GPU初始时在浮点计算上一直弱于CPU)。
从结果上导致CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算,数据压缩,人工智能,物理模拟,以及其他很多很多计算任务等。
GPU由于历史原因,是为了视频游戏而产生的(至今其主要驱动力还是不断增长的视频游戏市场),在三维游戏中常常出现的一类操作是对海量数据进行相同的操作,如:对每一个顶点进行同样的坐标变换,对每一个顶点按照同样的光照模型计算颜色值。GPU的众核架构非常适合把同样的指令流并行发送到众核上,采用不同的输入数据执行
当程序员为CPU编写程序时,他们倾向于利用复杂的逻辑结构优化算法从而减少计算任务的运行时间,即Latency。
当程序员为GPU编写程序时,则利用其处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来掩盖Lantency
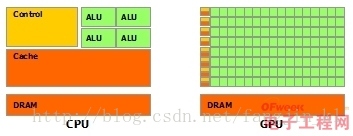
其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分
美国Sandia国家实验室一项模拟测试证明:由于存储机制和内存带宽的限制,16核、32核甚至64核处理器对于超级计算机来说,不仅不能带来性能提升,甚至可能导致效率的大幅度下降。
二、CUDA
CUDA(Compute Unified Device Architecture),是英伟达公司推出的一种基于新的并行编程模型和指令集架构的通用计算架构,它能利用英伟达GPU的并行计算引擎,比CPU更高效的解决许多复杂计算任务。
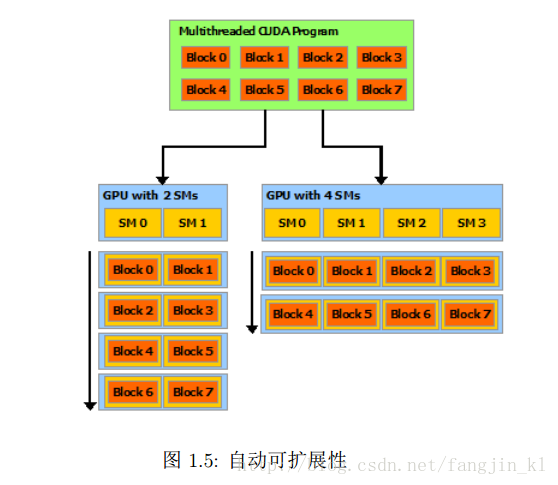
使用CUDA的好处就是透明。根据摩尔定律GPU的晶体管数量不断增多,硬件结构必然是不断的在发展变化,没有必要每次都为不同的硬件结构重新编码,而CUDA就是提供了一种可扩展的编程模型,使得已经写好的CUDA代码可以在任意数量核心的GPU上运行。如下图所示,只有运行时,系统才知道物理处理器的数量。
三、CuDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如加州大学伯克利分校的流行CAFFE软件。简单的,插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是调整性能,同时还可以在GPU上实现高性能现代并行计算。
CuDNN支持的算法
- 卷积操作、相关操作的前向和后向过程。
- pooling的前向后向过程
- softmax的前向后向过程
- 激活函数的前向后向过程
- ReLU
- sigmoid
- TANH
- Tensor转换函数,其中一个Tensor就是一个四维的向量。
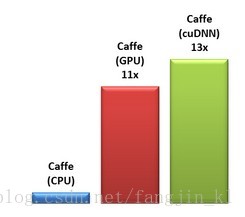
Baseline Caffe与用NVIDIA Titan Z 加速cuDNN的Caffe做比较
CUDA编程:一篇很好的介绍
四、OpenCL
是由苹果(Apple)公司发起,业界众多著名厂商共同制作的面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境。便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
OpenCL实际上是什么?
- OpenCL实际上是针对异构系统进行并行编程的一个全新的API,OpenCL可以利用GPU进行一些并行计算的工作。
- OpenGL是针对图形的,而OpenCL则是针对并行计算的API。
- OpenCL开发的过程中,技术平台均为NVIDIA的GPU,实际上OpenCL是基于NVIDIA GPU的平台进行开发的。另外OpenCL的第一次演示也是运行在NVIDIA的GPU上。
- 从本质上来说,OpenCL就是一个相当于Windows平台中DirectX那样的技术。或者说,它是一个连接硬件和软件的API接口。在这一点上,它和OpenGL类似,不过OpenCL的涉及范围要比OpenGL大得多,它不仅是用来作用于3D图形。如果用一句话描述,OpenCL的作用就是通过调用处理器和GPU的计算资源,释放硬件潜力,让程序运行得更快更好。
五、OpenCL和CUDA的关系
CUDA实际上是什么?
- CUDA架构是原生的,专门为计算接口而建造的这样的一个架构,这种硬件架构包括指令集都是非常适合于这种并行计算,为异构计算而设计的一整套的架构。CUDA架构可以支持API,包括OpenCL或者DirectX,同时CUDA还支持C、C++语言,还包括Fortran、Java、Python等各种各样的语言。

OpenCL与CUDA的关系是什么?
- CUDA和OpenCL的关系并不是冲突关系,而是包容关系。OpenCL是一个API,在第一个级别,CUDA架构是更高一个级别,在这个架构上不管是OpenCL还是DX11这样的API,还是像C语言、Fortran、DX11计算,都可以支持。作为程序开发员来讲,一般他们只懂这些语言或者API,可以采用多种语言开发自己的程序,不管他选择什么语言,只要是希望调用GPU的计算能,在这个架构上都可以用CUDA来编程。
- 关于OpenCL与CUDA之间的技术区别,主要体现在实现方法上。基于C语言的CUDA被包装成一种容易编写的代码,因此即使是不熟悉芯片构造的科研人员,也可能利用CUDA工具编写出实用的程序。而OpenCL虽然句法上与CUDA接近,但是它更加强调底层操作,因此难度较高,但正因为如此,OpenCL才能跨平台运行。
- CUDA是一个并行计算的架构,包含有一个指令集架构和相应的硬件引擎。OpenCL是一个并行计算的应用程序编程接口(API),在NVIDIA CUDA架构上OpenCL是除了C for CUDA外新增的一个CUDA程序开发途径。
- 如果你想获得更多的对硬件上的控制权的话,你可以使用OpenCL这个API来进行编程,如果对API不是太了解,也可以用CUDA C语言来编程,这是两种不同编程的方式,他们有他们相同点和不同点。但是有一点OpenCL和CUDA C语言进行开发的时候,在并行计算这块,他们的概念是差不多的,这两种程序在程序上是有很大的相似度,所以程序之间的相互移植相对来说也是比较容易。

- CUDA C语言与OpenCL的定位不同,或者说是用人群不同。CUDA C是一种高级语言,那些对硬件了解不多的非专业人士也能轻松上手;而OpenCL则是针对硬件的应用程序开发接口,它能给程序员更多对硬件的控制权,相应的上手及开发会比较难一些。
- 程序员的使用习惯也是非常重要的一方面,那些在X86 CPU平台使用C语言的人员,会很容易接受基于CUDA GPU平台的C语言;而习惯于使用OpenGL图形开发的人员,看到OpenCL会更加亲切一些,在其基础上开发与图形、视频有关的计算程序会非常容易。
参考博客:https://blog.csdn.net/babyfacer/article/details/6863572
https://blog.csdn.net/fangjin_kl/article/details/53906874
https://blog.csdn.net/l724225271/article/details/24439751