一、下载、安装zipkin
zipkin的github地址:https://github.com/openzipkin/zipkin
下载:zipkin-server-2.11.5-exec.jar
执行:java -jar zipkin-server-2.11.5-exec.jar
访问地址:http://localhost:9411/zipkin/二、在服务提供方、与消费方的pom.xml文件中添加依赖
<!--服务链路监控(包含sleuth、zipkin)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>三、配置application.yml文件
spring:
application:
name: consumer-dept
zipkin:
base-url: http://localhost:9411 #zipkin地址
sleuth:
sampler:
percentage: 1 #抽样百分比(默认是0.1,即10%)-(只抽样监控10的请求%)四、消费方发起请求,调用服务提供方的查询部门信息的接口
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import com.f6car.springcloud.entities.Dept;
@RestController
public class DeptController_Consumer {
private static final String REST_URL_PREFIX = "http://MICROSERVICECLOUD-DEPT";
@Autowired
private RestTemplate restTemplate;
@RequestMapping(value = "/consumer/dept/get/{id}")
public Dept get(@PathVariable("id") Long id) {
return restTemplate.getForObject(REST_URL_PREFIX + "/dept/get/" + id, Dept.class);
}
}
五、查看zipkin



点击json按钮,查看详情信息:
[
{
"traceId": "aba1676129d21fce",
"parentId": "aba1676129d21fce",
"id": "8aed49b22ffbb25a",
"kind": "CLIENT",
"name": "http:/dept/get/1",
"timestamp": 1537668515817000,
"duration": 445000,
"localEndpoint": {
"serviceName": "consumer-dept",
"ipv4": "192.168.0.105",
"port": 80
},
"tags": {
"http.host": "MICROSERVICECLOUD-DEPT",
"http.method": "GET",
"http.path": "/dept/get/1",
"http.url": "http://MICROSERVICECLOUD-DEPT/dept/get/1",
"spring.instance_id": "192.168.0.105:consumer-dept:80"
}
},
{
"traceId": "aba1676129d21fce",
"id": "aba1676129d21fce",
"kind": "SERVER",
"name": "http:/consumer/dept/get/1",
"timestamp": 1537668515785000,
"duration": 547193,
"localEndpoint": {
"serviceName": "consumer-dept",
"ipv4": "192.168.0.105",
"port": 80
},
"tags": {
"mvc.controller.class": "DeptController_Consumer",
"mvc.controller.method": "get",
"spring.instance_id": "192.168.0.105:consumer-dept:80"
}
},
{
"traceId": "aba1676129d21fce",
"parentId": "aba1676129d21fce",
"id": "8aed49b22ffbb25a",
"kind": "SERVER",
"name": "http:/dept/get/1",
"timestamp": 1537668516243000,
"duration": 2000,
"localEndpoint": {
"serviceName": "microservicecloud-dept",
"ipv4": "192.168.0.105",
"port": 8001
},
"tags": {
"mvc.controller.class": "DeptController",
"mvc.controller.method": "get",
"spring.instance_id": "192.168.0.105:microservicecloud-dept:8001"
},
"shared": true
}
]六、补充
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
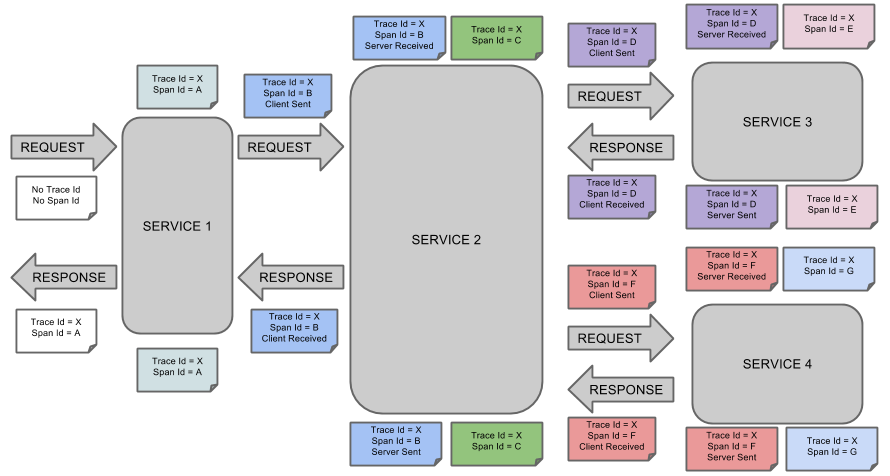
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们: 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时; 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到; 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。 spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
这是Spring Cloud Sleuth的概念图:
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。 每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。 Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。