版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_39220472/article/details/82050276
Linux系统:Centos7 64位
Scrapy框架:python的一个爬虫框架
python版本:python3.6.3
安装步骤:
[root@localhost Python3.6.3]# pip3 install scrapy
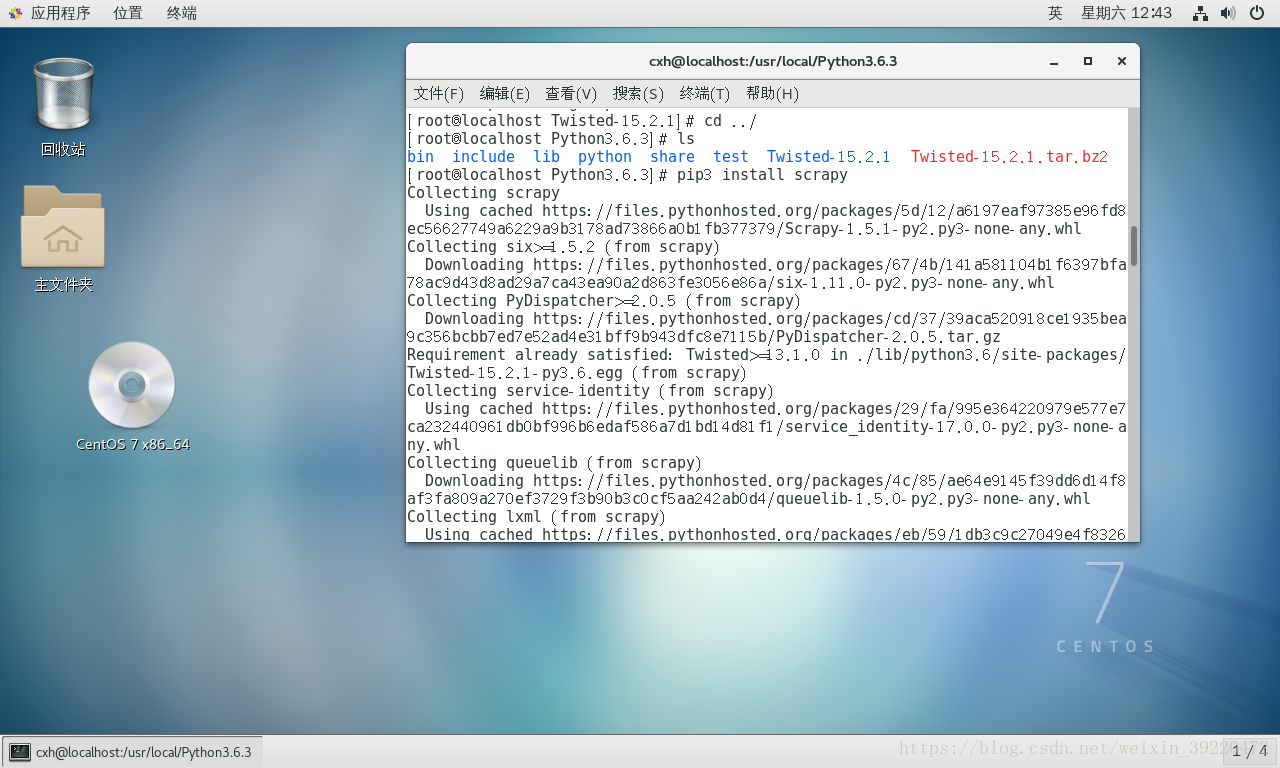
安装过程可能报的错,解决方案:
解决Could not find a version that satisfies the requirement Twisted>=13.1.0 (from Scrapy)
解决You are using pip version 9.0.1, however version 18.0 is available. You should consider upgrading
解决import twisted.persisted.styles # NOQA ModuleNotFoundError: No module named 'twisted.persisted'
安装成功:
在python3中导入scrapy:表示安装成功。
[root@localhost Python3.6.3]# python3
Python 3.6.3 (default, Aug 21 2018, 20:41:20)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> exit()
建立scrapy的软连接:
[root@localhost Python3.6.3] # ln -s /usr/local/ Python3.6.3/bin/scrapy /usr/bin/scrapy
验证Scrapy软链接
扫描二维码关注公众号,回复:
3482734 查看本文章

[root@localhost Python3.6.3]# scrapy --v
Scrapy 1.5.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command