gbk与gb2312的区别:
- GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码;
- GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名。
- 总体说来,GBK包括所有的汉字,包括简体和繁体。而gb2312则只包括简体汉字。
引自:“gbk与gb2312的区别”百度百科
gb2312,全称是GB2312-80《信息交换用汉字编码字符集 基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码, Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。GB码共收录6763个简体汉字、682个符号,其中汉字部分:一级字3755,以拼音排序,二级字3008,以偏旁排序。该标准的制定和应用为规范、推动中文信息化进程起了很大作用。
GBK: 汉字国标扩展码,基本上采用了原来GB2312-80所有的汉字及码位,并涵盖了原Unicode中所有的汉字20902,总共收录了883个符号, 21003个汉字及提供了1894个造字码位。 Microsoft简体版中文Windows 95就是以GBK为内码,又由于GBK同时也涵盖了Unicode所有CJK汉字,所以也可以和Unicode做一一对应。
这真的是GB2312的区位码是94的来历 ?
在网上获得了一些关于GB2312的区位码是94的来历说明,想请各位知情人士求证一下,具体内容核心思想摘抄如下:
来自 http://www.zhihu.com/question/21923181
为何采用94×94的区位码?
ASCII使用了0x00~0x7F,而作为国际通用的精确数字计算使用的BCD编码的范围是0x00~0x99,所以GB2312应该可以选的范围在0x9A~0xFF,为了预留一定空间避免冲突,可选范围应该在0xA0~0xFF之间,但习惯上中国人喜欢用数字1来标示一个数据的开始,所以首位就定在了0xA1。同时,0xFF代表结束,而且程序员一般概念上都将0xFF定义为“空”,为了避免代码习惯上的问题,末尾自然选择在了0xFE。因此,最重要的东西来了 0xFE-0xA0 + 1 = 94 。
cp936 — code page 936 (936是编号)
来自 http://bbs.csdn.net/topics/80329088
来自 http://bbs.csdn.net/topics/80329088
extended unicode characters:unicode字符扩展
中文是euc-cp936
日文是euc-cp932
gb2312以及gbk都是我国的编码委员会制定的。cp936是微软制定的。euc-cn是汉字在extended unicode characters码表里的表示。
来自 http://bbs.csdn.net/topics/80329088
关于Windows记事本与Sublime Text对中文字符编码转换的问题:
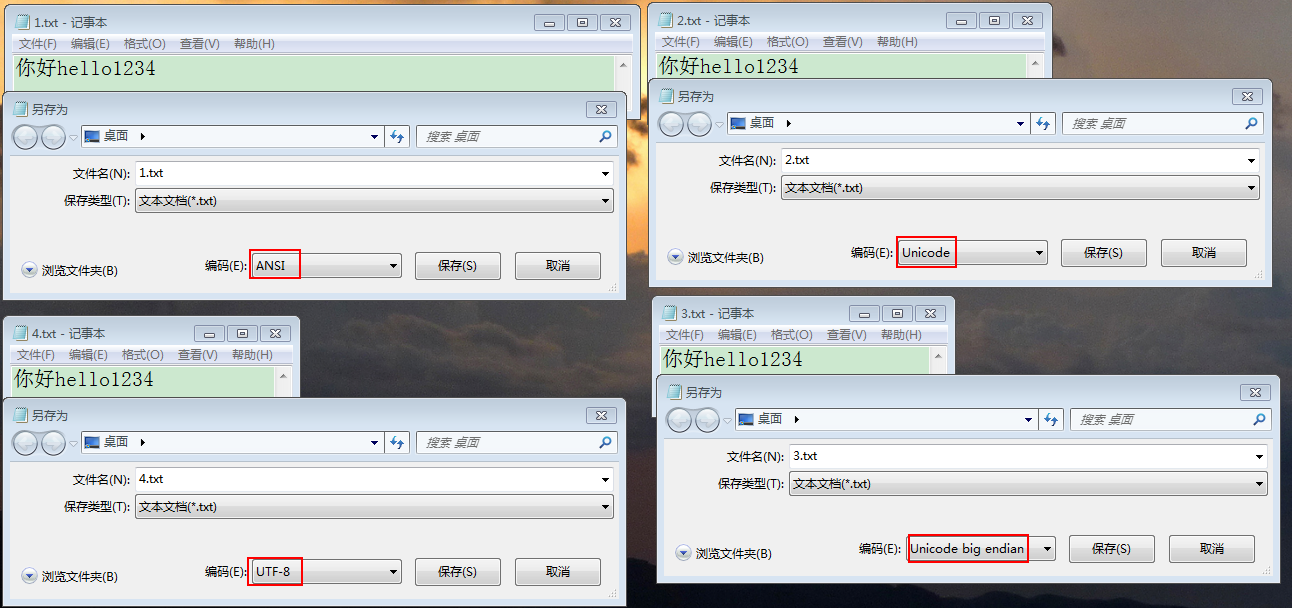
1、在Windows记事本中,新建文件,输入“你好hello1234”,以ANSI格式保存后;
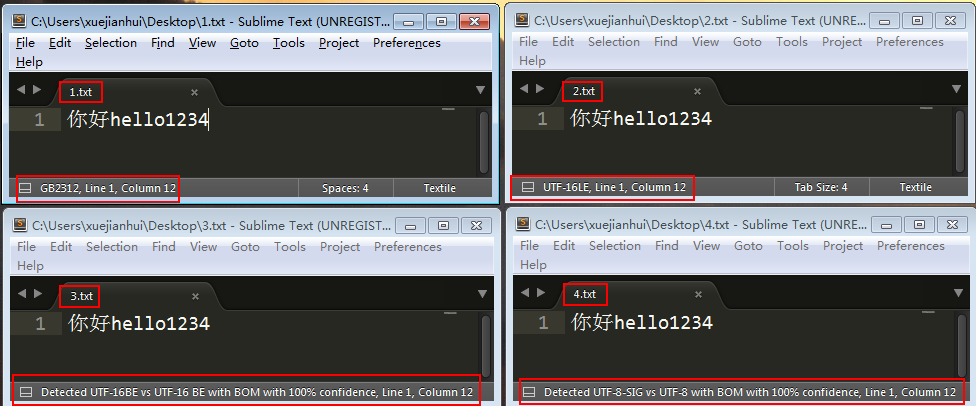
2、在Sublime Text中打开此文件,文件格式为GB2312,输入GB2312内不支持的汉字“喆”,提示保存失败,原因是’\u5586’是非法的多字节序列;
‘gb2312’ codec can’t encode character ‘\u5586’ in position 11: illegal multibyte sequence
第 11 个字符就是“喆”。
注意:如果不删除这个字段,Sublime Text会以UTF-8格式重新保存这个文件。
3、在Windows记事本中,输入GB2312内不支持的汉字“喆”,按ANSI格式保存成功;
4、再次用Sublime Text打开此文件,文件格式已变为GBK。
综上,Sublime Text是对GB2312和GBK做区分的,而Windows记事本在界面上是都以ANSI方式管理,并兼容这两种方式。
我猜测,除非遇到GB2312不能识别的生僻字才使用GBK,否则默认以GB2312编码格式保存。
GBK作为GB2312的扩展码,其文件开头的编码标志与GB2312应该是不同的,否则Sublime Text不会将GB2312和GBK区分显示。
为什么ansi可以包含汉字?
在简体中文系统下,ANSI 编码代表 GB2312 编码,《信息交换用汉字编码字符集》
是由中国标准总局1980年发布,1981年5月1日开始实施的一套国家 汉字编码字符集
标准,标准号是GB 2312—1980。
它是计算机可以识别的编码,适用于汉字处理、汉字通信等系统之间的信息交换。
基本集共收入汉字6763个和非汉字图形字符682个。
整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,
因此可用所在的区和位来对汉字进行编码