“听说现在的大数据可厉害,你干啥人家都知道”。
早上8点,卖包子的大妈这样对我说:
随着大规模数据处理技术的日渐成熟,拥有海量用户数据的公司都想从中挖掘出有利信息来影响用户的生活消费。
-
京东、淘宝等电商网站利用用户画像做个性化商品推荐;
-
今日头条、一点资讯利用算法做个性化内容推荐;
-
支付宝、宜信等互联网金融公司通过识别高危行为的特征实施风险控制;
这类企业对大数据、数据挖掘相关人才的需求非常之大,导致行业内人才的供给严重不足。
因此,大数据、数据挖掘、人工智能相关人才薪资都非常高,大数据平台/开发工程师(Hadoop)的起薪也在25K/月,像AI工程师平均年薪要在40-60万。

这也正是普通程序员的职场机遇。
那如何学习才能顺利入行并拿到30万+年薪呢?
下面给大家介绍详细的学习方案:
第一阶段:语言基础
1.Java
掌握JavaSE知识,不需要深入;
2.Linux
系统安装、基本命令、Shell脚本等;
3.Python
基础语法、数据结构等。
Python是人工智能领域最主流的编程语言,学习Python大数据技术有利于无缝转AI。
第二阶段:Hadoop生态架构技术
1.环境准备
在windows电脑搭建完全分布式,1主2从。
需要用到:VMware虚拟机、Linux系统(Centos6.5)、Hadoop安装包。
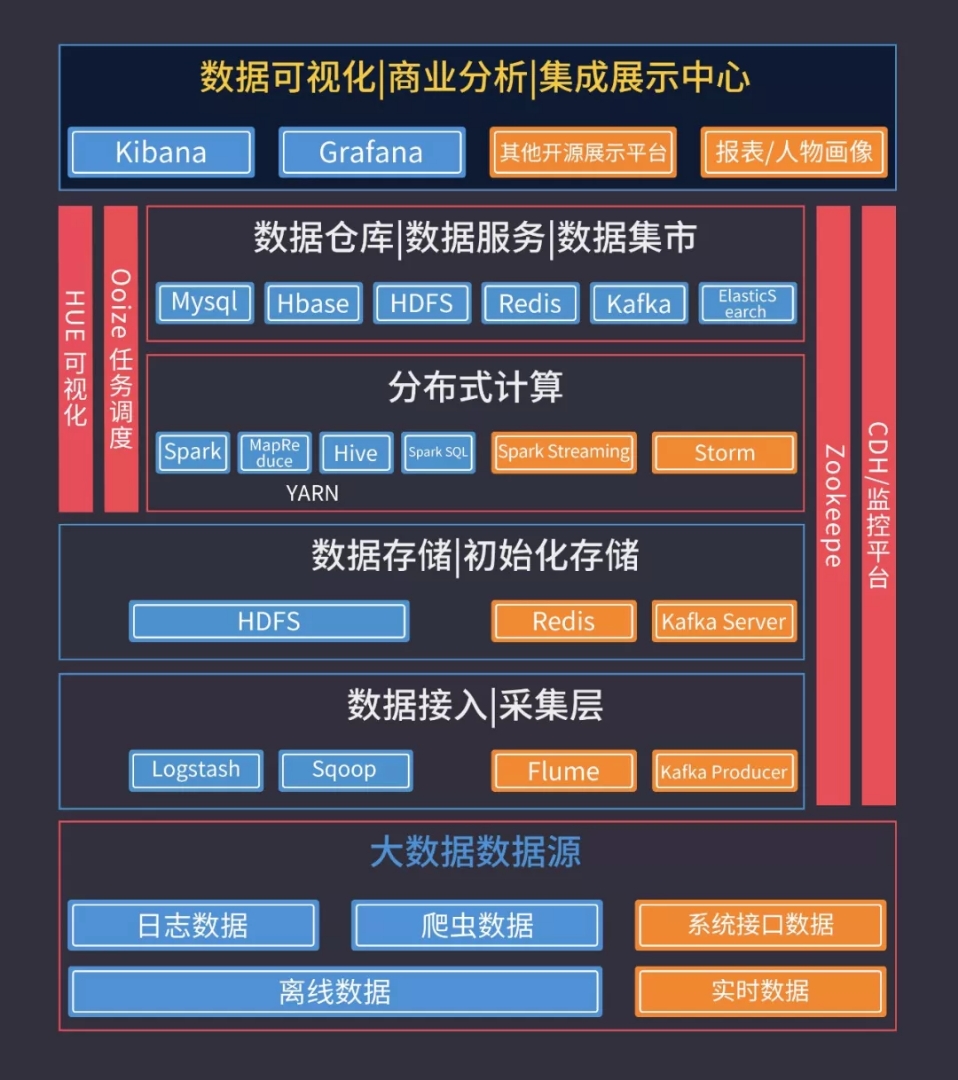
2.Map Reduce
主要适用于大批量的集群任务,时效性偏低。
3.HDFS1.0/2.0
Hadoop分布式文件系统(HDFS)能提供高吞吐量的数据访问。
4.Yarn(Hadoop2.0)
Yarn是一个资源调度平台,主要负责给任务分配资源。
5.Hive
Hive是一个数据仓库,所有的数据都存储在HDFS上。
使用Hive主要是写Hql,底层执行的是Map Redce程序。
6.Spark
Spark 是基于内存的迭代式计算,继承了Map Reduce 的优点,而且在时效性上有了很大提高。
7.Spark Streaming
Spark Streaming是实时处理框架,数据是一批一批的处理。
8.Spark Hive
Spark作为Hive的计算引擎,可以提高Hive查询的性能。
9.Storm
Storm是一个实时计算框架,对实时新增的每一条数据进行处理,是一条一条的处理。
10.Zookeeper
Zookeeper是很多大数据框架的基础,它是集群的管理者。
11.Hbase
Hbase是一个Nosql 数据库,适用于非结构化的数据存储,底层的数据存储在HDFS上。
12.Kafka
kafka是一个消息中间件,作为一个中间缓冲层。
13.Flume
Flume是一个日志采集工具,常见的就是采集应用产生的日志文件中的数据。
按照上述顺序学习,并掌握后就可以从事Hadoop开发工程师、Spark开发工程师等职位。
第三阶段:数据挖掘、机器学习算法
1.中文分词
开源分词库的离线和在线应用;
2.自然语言处理
文本相关性算法;
3.推荐算法
基于CB、CF,归一法,Mahout应用;
4.分类算法
NB、SVM;
5.回归算法
LR、Decision Tree;
6.聚类算法
层次聚类、Kmeans;
7.神经网络与深度学习
NN、Tensorflow;
按照上述顺序学习,并掌握后就可以从事数据挖掘相关的职位。
这也是普通程序员转行算法、机器学习相关工程师最简单的职位,而且这个职位非常利于后期向AI工程师发展。
--------------------- 本文来自 扑满心 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/sinat_38648491/article/details/79912837?utm_source=copy