版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/gwd1154978352/article/details/82863672
ElasticSearch汇总请查看:ElasticSearch教程——汇总篇
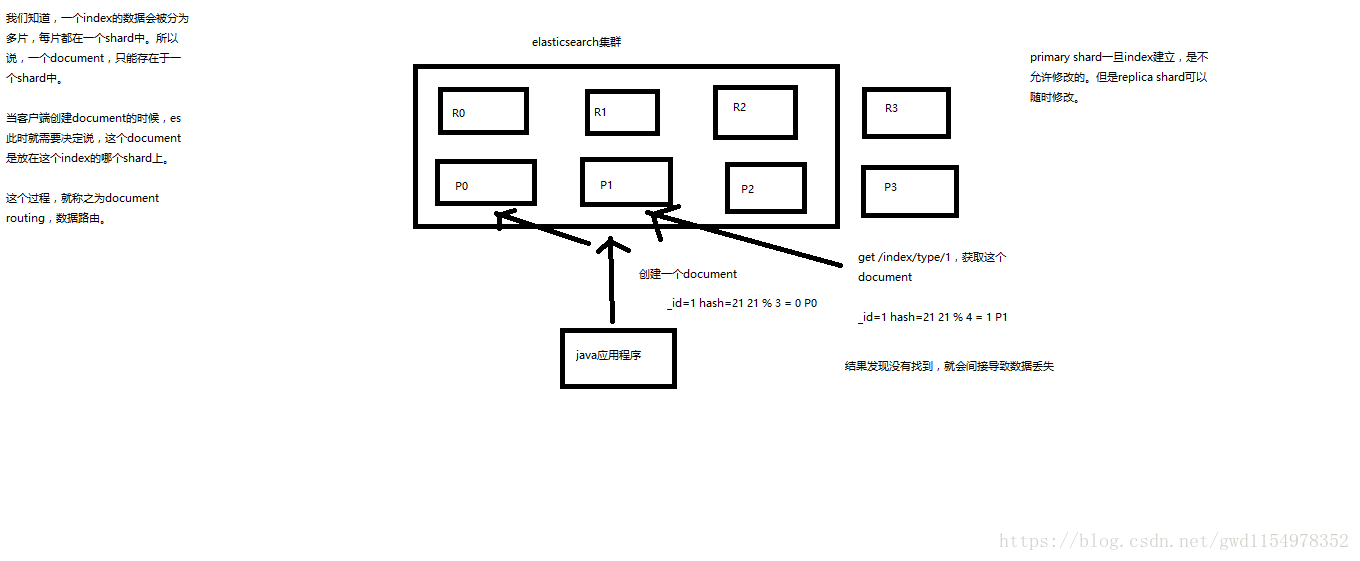
路由原理
路由算法
shard = hash(routing) % number_of_primary_shards
- shard是指document通过该路由算法会落到那个shard上;
- number_of_primary_shards指的是创建时指定的primary shard数量;
- 每次增删改查的一个document的时候,会带过来一个routing number,默认就是这个document的id(可能是自动生成,也可能是创建document的时候指定生成),routing值也是可以手动指定的,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的。如下指定routing值为userid
put /index/type/id?routing=user_id手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的
为何primary shard数量不可变
由上面可知,routing在创建之后是不变的,那么从hash函数中产出的hash值一定是相同的,如果primary shard的数量改变了,那么对应的document存储的shard也就改变了,那么就会存在在原始shard上找不到对应document的情况
增删改内部原理
(1)客户端随机任意选择一个node(因为任意一个node都是知道每个document在哪个node上的,多以对client来说都是一样的)发送请求过去,这个node瞬间就会变成coordinating node(协调节点);
(2)coordinating node,根据document的routing对document进行路由,将请求转发给对应的node(有primary shard);
(3)实际的node上的primary shard处理请求(进行增删改),然后将数据同步到replica node,同步完之后会给coordinating node响应;
(4)coordinating node,得到响应发现primary node和所有replica node都搞定之后,就返回响应结果给客户端;

查询原理
- 客户端发送请求到任意一个node,成为coordinate node;
- coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡;
- 接收请求的node返回document给coordinate node;
- coordinate node返回document给客户端;
- 特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了;
