问题描述
前几天早上出现一后台项目无法登陆的情况,排查发现新生代和老年代都占用100%,FullGC次数大概有100多次,最终出现OOM。
重启Tomcat后,至13点,FullGC的次数达到31次。
排查过程
- 通过对Java堆进行分析,发现数据量较大的实例类型为char[],其中最大的一个char[]实例大小为
127MB,对其内容进行分析,发现与某接口的方法有关。 - 进一步分析发现,该接口在某一参数的情况下,就会产生这种大对象。同时这个是一个局部变量。
- 检查JVM配置如下:
-server -Xrs -Xmx5120m -Xms1536m -Xmn512m -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods
-XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:SurvivorRatio=8可知,新生代中Survivor占51.2MB,无法放入127MB的char[]实例。
故这种对象如果在第一次MinorGC时存活,它将无法进入survivor,而会提前转移到老年代。
4. 那么,这类大小为127MB的局部变量为什么在MajorGC时能够存活?推测原因如下:
(1)第3点所述的熬过一轮MinorGC提前进入老年代的对象不断增加,直至占满老年代的70%。
(2)这时由于CMSInitiatingOccupancyFraction=70,将触发CMS的MajorGC。
(3)我们知道CMS的GC有部分过程是可以与用户线程同时执行的,假如在这个过程中,用户线程产生的对象大小占满老年代剩余的30%,那么CMS并发模式的GC就失败了(concurrent mode failure)。
(4)当CMS的并发GC失败后,将使用Serial Old的串行GC重新执行。
(5)Serial Old的GC是会全过程Stop The World的,也就是造成长时间停顿。
5. 为了验证上述结论,开启GC日志后对此场景进行复现。
复现记录
- 修改
-Xms5120m避免扩容,增加-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/data/gc.log - 重启发现FullGC很短的时间内就发生了4次,观察发生FullGC前后,出现了MC、CCSC增大的情况。得出这2部分内存的初始值过小。
(1)MC:方法区大小。按目前使用量,可调整为75MB。
(2)CCSC:压缩类空间大小。按目前使用量,可调整为10MB。 - 调用一次出问题的接口,调用前后GC情况
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
52416.0 52416.0 52416.0 0.0 419456.0 17534.6 4718592.0 66465.3 72012.0 71106.0 7560.0 7334.3 30 2.209 4 0.116 2.324
52416.0 52416.0 0.0 52416.0 419456.0 82050.7 4718592.0 264498.1 72908.0 71710.7 7688.0 7375.7 31 2.471 4 0.116 2.586可以发现Eden增加65MB,老年代增加200MB。
4. 重复多次请求接口后,新生代、老年代均被占满。
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
52416.0 52416.0 52416.0 0.0 419456.0 419456.0 4718592.0 4718592.0 75084.0 73600.4 7816.0 7422.0 607 40.282 42 203.704 243.9865.此时关闭所有页面,等待10分钟左右,JVM占满情况仍然无法恢复(Eden和survivor区偶尔会出现减少,但马上又会被迅速占满,old区始终维持占满状态)。
6.清理cookie后,重新登录,出现与之前情况一致的无法登录的现象。
7.执行dump:live,得到7.9G文件。(此处与上次情况不同,上次执行完后,old区域就被回收掉了,而dump文件也只有142M。另外,上次tomcat日志中有出现OOM的日志,本次没有)
8.重启该tomcat,截止重启前,GC情况如下:
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
52416.0 52416.0 52416.0 0.0 419456.0 419456.0 4718592.0 4718592.0 75084.0 73653.9 7816.0 7423.7 607 40.282 129 1054.540 1094.822
GC分析
GC日志
1.第一次出现Full GC (Allocation Failure)在1544.618。
2.伴随出现concurrent mode failure,这种提示代表无法在老年代填满之前完成垃圾回收,或者一个新的对象无法在老年代的剩余空间完成分配,这时程序会停止所有线程来完成GC。原文如下:
if the concurrent collector is unable to finish reclaiming the unreachable objects before the tenured generation fills up, or if an allocation cannot be satisfied with the available free space blocks in the tenured generation, then the application is paused and the collection is completed with all the application threads stopped
3.结束时间为2723.551,即从老年代占满到被重启间隔1179秒,约20分钟。
堆分析
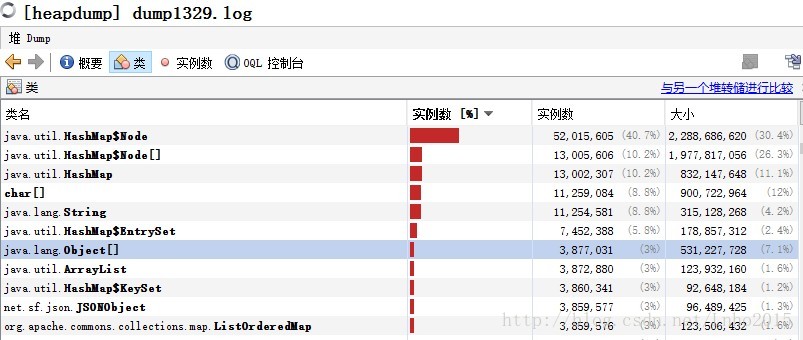
下图为复现过程的dump文件,大小最大的已经不是char[],不过前几个过大的对象均为调用上述接口中的局部变量。
解决办法
1.优化JVM启动参数
(1)调整堆内存初始值为-Xms5120m避免扩容
(2)调整新生代大小为-Xmn1536m
(3)CMSInitiatingOccupancyFraction=60
(4)方法区大小调整为100MB
(5)压缩类空间大小调整为15MB
2.对该接口实现进行优化
3.JVM参数调整后跟踪FullGC情况