版权声明:本文为博主原创文章,可以随便转载 https://blog.csdn.net/appleyuchi/article/details/82876216
我们修改数据集,使用:
《数据挖掘导论》中的数据集:
def loadSimpDat():
simpDat = [['a', 'b'],
['b', 'c', 'd'],
['a', 'c', 'd', 'e'],
['a', 'd', 'e'],
['a', 'b', 'c'],#与下面一条一样
['a', 'b', 'c','d'],
['a'],
['a', 'b', 'c'],#与上面一条一样
['a', 'b', 'd'],
['b', 'c' ,'e']]如果打印出来是这个,
Null Set 1
a 7
c 1
d 1
e 1
b 4
c 2
d 1
d 1
d 1
e 1
b 2
c 2
e 1
d 1
那么对应的图就是下面这个的,注意,这里阅读上面的打印结果时,
是横着看的,不是竖着看的。
而数字则是横向和字母配对的。
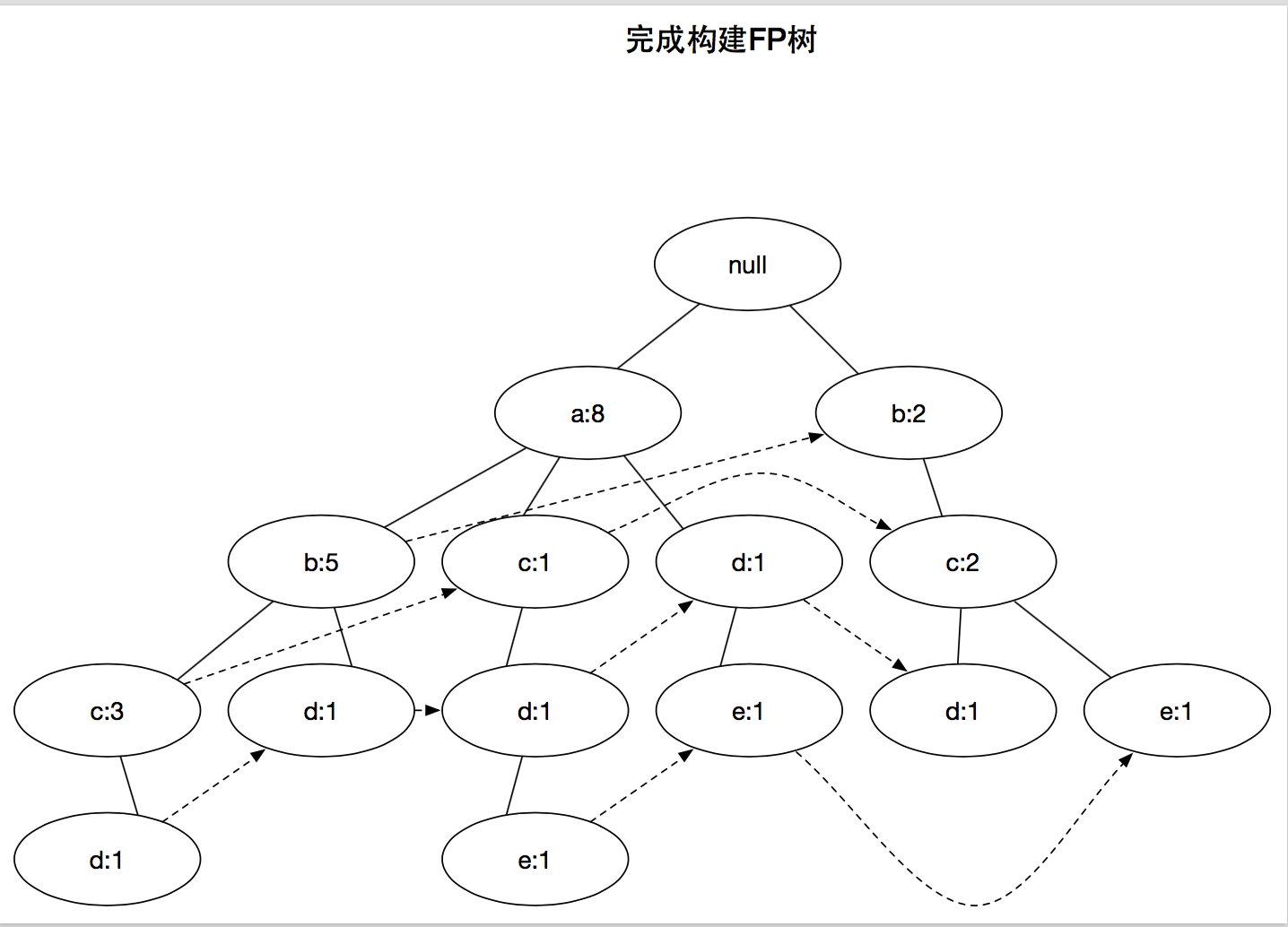
好了,问题来了,我们会发现图中a:8,代码输出却是a:7
这是为什么呢?
修改书中的代码即可:
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
# retDict[frozenset(trans)] = 1
retDict[frozenset(trans)]=retDict.get(frozenset(trans), 0) +1
print"初始化数据retDict=",retDict
return retDict然后输出结果就会和图中一模一样了
Null Set 1
a 8
c 1
d 1
e 1
b 5
c 3
d 1
d 1
d 1
e 1
b 2
c 2
e 1
d 1