我们先简单说明下索引的一些特点:
索引:
可以将索引理解成为一个快速通道——他能够快速的找到数据表中某一列具有特定值的行。
如果没有索引,那么想要根据某一列的值去锁定某一行,那么数据库只能一个一个去比对,相当耗时。
就像一本书,如果没有目录的情况下,你想要去查找某个章节,那你是不是只能一页一页的去翻,直到找到这一章节位置。
如果有目录的存在,那么要找某一章节,你只需要根据目录结构去查找,这个章节在多少页,你根据页码直接翻过去就行。
这个目录起到的作用就是索引。当然,我们也就很容易想象的到索引的优缺点————
优点:
很显然,大大的提升了检索的效率,这个可以认为是创建索引的驱动因素。
我们可以通过测试查看使用和不使用索引查询时候的效率。
我们创建一张表,这张的数据量是1W条:
我们先查看索引的创建情况:
除了主键索引我们没有创建其他索引。
我们通过shard的字段进行查询:


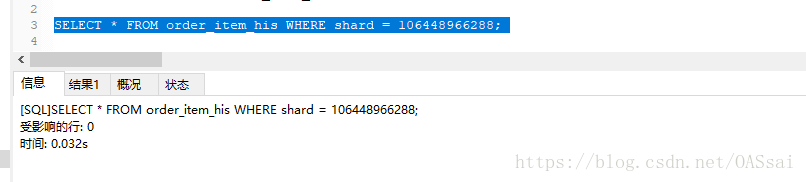

可以看到执行时间是0.032。查看解释,看到执行查询时候确实没有用到索引。
我们在shard字段上创建索引之后在执行查询:
我们看到索引已经创建,下面执行查询测试:
查询时间变为0.003,查询效率提升很明显。

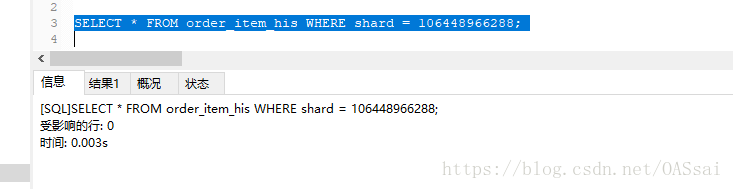

可以想象,如果数据在百万级,千万级以上,有没有索引的执行效率会更明显。
缺点:
1.索引也会占用空间。实际上索引也是一张表,这张表保存了主键和索引字段,同时指向实体表的记录。
可以这么理解,一本书有700页,那么目录就会有有6页左右。
换句话说,索引的本质就是以空间换时间。
2.索引需要维护。一本书如果书里面内容变了,比如修改或者增加或者删除了某个章节内容,那么其目录结构也需要随之做出改变。
同样的,索引也是一样,如果对表进行了insert,update,delete操作,不仅要保存表数据,还要保存一下索引文件。
接下来我们分析一下致使索引失效的几种情况:
1.想像一下,如果通过目录去查找书中的某个章节,如果你的目的是找到不是A章节的其他章节,那么会导致什么情况?
你会去一个一个查找章节,看这个章节是不是A章节。
同样的,如果执行检索的条件中使用了id != 30 或者id <> 30这种查询条件,将导致mysql无法使用索引。
这个不多做解释,没有通过对应的索引值去查询,索引很明显没有发挥空间。。。
2.查询条件中使用like,并且like查询以%开始。
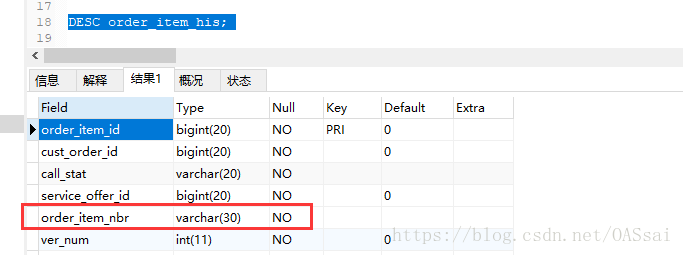
3.如果建立索引的列类型是字符类型,那么需要在查询条件中加上引号,否则无法使用索引。
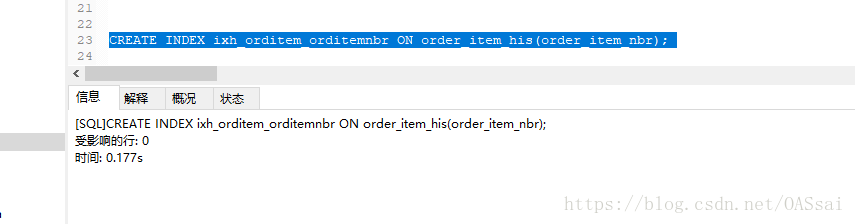
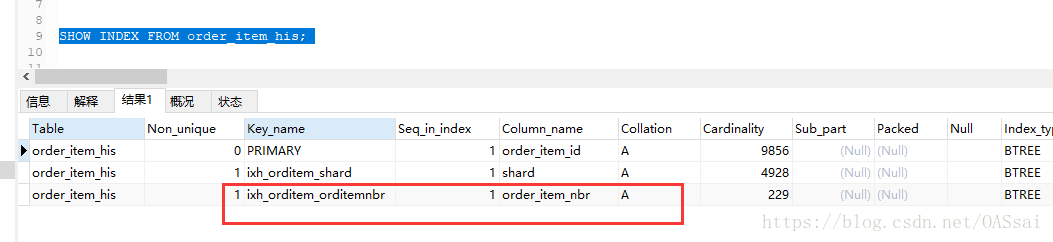
我们在字符型字段上创建一个索引:
查询测试:
可以看到字符型驱动条件没有加引号时候索引失效。
我们可以分析一下:
我们索引建立在字符型字段上,查询条件是数字,执行查询时候,mysql作比较发现类型不统一,这个时候会发生隐式转换:
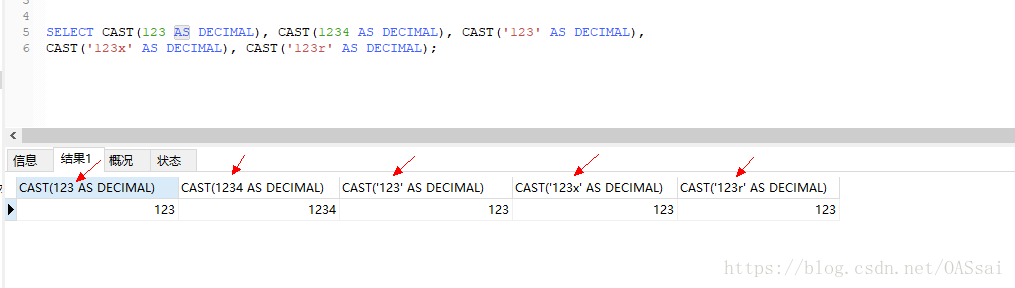
具体的转换规则请查询相关资料,在这里,字符型和数值型的转换,两者都会转换为浮点型,我们看看两种类型浮点型的值:
我们可以发现,在不超出浮点型数值范围的情况下,数值型转换为浮点型是一一对应的,而多个字符型可能会对应一个浮点型,也就是说通过浮点型的值去查询字符型,可能会有很多个结果。
那么这种情况的查询,字符型和数值型都转换为浮点型,查询条件的浮点型的值可能会对应很多个字符型的值,这种查询就有点类似like '%value%',mysql认为这种情况无法通过访问索引来快速定位,所以这种查询导致索引失效,转走全表扫描。





那么我们考虑,如果我们在一个数值型字段上建立索引,但是查询条件我们对数值加上引号,索引是否会有使用?
显然这种情况也是会有隐式转换,上面我们分析得知,字符型转换为浮点型,字符型对应的浮点型只有一个,但是浮点型对应的字符型可能会有多个,那么在查询条件的字符型转换后是可以得到唯一的浮点型的,所以我们分析这种情况下索引会起到作用。
我们用查询来佐证:
查看索引和字段类型:
查询并查看解释:
分析正确。
4.查询条件中有or,即使条件字段有索引也不会去使用。

附:
索引的相关语法:
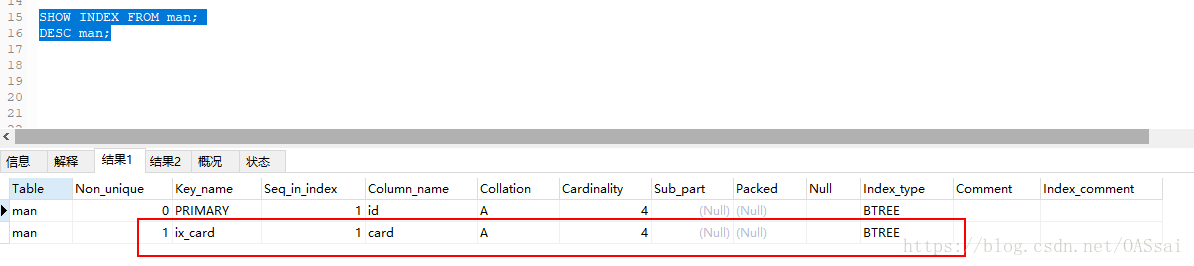
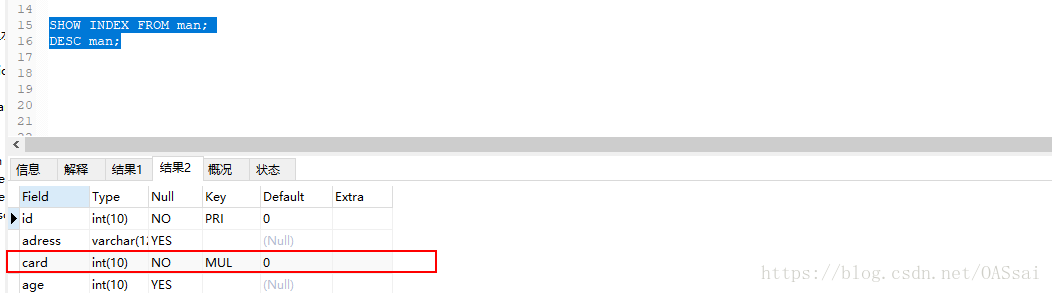
1.查询某个表上的索引:SHOW INDEX FROM table_name;
2.创建索引:CREATE INDEX index_name ON table_name(column);
如果是创建联合索引,补充对应的列名就行:
CREATE INDEX index_name ON table_name(column1, column2, column3);