练习:使用部门表、工资等级表和员工表熟悉语法
–部门表
dept部门表(deptno部门编号/dname部门名称/loc地点)
create table dept (
deptno numeric(2),
dname varchar(14),
loc varchar(13)
);
insert into dept values (10, ‘ACCOUNTING’, ‘NEW YORK’);
insert into dept values (20, ‘RESEARCH’, ‘DALLAS’);
insert into dept values (30, ‘SALES’, ‘CHICAGO’);
insert into dept values (40, ‘OPERATIONS’, ‘BOSTON’);
–工资等级表
salgrade工资等级表(grade 等级/losal此等级的最低/hisal此等级的最高)
create table salgrade (
grade numeric,
losal numeric,
hisal numeric
);
insert into salgrade values (1, 700, 1200);
insert into salgrade values (2, 1201, 1400);
insert into salgrade values (3, 1401, 2000);
insert into salgrade values (4, 2001, 3000);
insert into salgrade values (5, 3001, 9999);
–员工表
emp员工表(empno员工号/ename员工姓名/job工作/mgr上级编号/hiredate受雇日期/sal薪金/comm佣金/deptno部门编号)
工资 = 薪金 + 佣金
1.表自己跟自己连接
create table emp (
empno numeric(4) not null,
ename varchar(10),
job varchar(9),
mgr numeric(4),
hiredate datetime,
sal numeric(7, 2),
comm numeric(7, 2),
deptno numeric(2)
);
insert into emp values (7369, ‘SMITH’, ‘CLERK’, 7902, ‘1980-12-17’, 800, null, 20);
insert into emp values (7499, ‘ALLEN’, ‘SALESMAN’, 7698, ‘1981-02-20’, 1600, 300, 30);
insert into emp values (7521, ‘WARD’, ‘SALESMAN’, 7698, ‘1981-02-22’, 1250, 500, 30);
insert into emp values (7566, ‘JONES’, ‘MANAGER’, 7839, ‘1981-04-02’, 2975, null, 20);
insert into emp values (7654, ‘MARTIN’, ‘SALESMAN’, 7698, ‘1981-09-28’, 1250, 1400, 30);
insert into emp values (7698, ‘BLAKE’, ‘MANAGER’, 7839, ‘1981-05-01’, 2850, null, 30);
insert into emp values (7782, ‘CLARK’, ‘MANAGER’, 7839, ‘1981-06-09’, 2450, null, 10);
insert into emp values (7788, ‘SCOTT’, ‘ANALYST’, 7566, ‘1982-12-09’, 3000, null, 20);
insert into emp values (7839, ‘KING’, ‘PRESIDENT’, null, ‘1981-11-17’, 5000, null, 10);
insert into emp values (7844, ‘TURNER’, ‘SALESMAN’, 7698, ‘1981-09-08’, 1500, 0, 30);
insert into emp values (7876, ‘ADAMS’, ‘CLERK’, 7788, ‘1983-01-12’, 1100, null, 20);
insert into emp values (7900, ‘JAMES’, ‘CLERK’, 7698, ‘1981-12-03’, 950, null, 30);
insert into emp values (7902, ‘FORD’, ‘ANALYST’, 7566, ‘1981-12-03’, 3000, null, 20);
insert into emp values (7934, ‘MILLER’, ‘CLERK’, 7782, ‘1982-01-23’, 1300, null, 10);
部门表dept三个字段 :deptno、dname、 loc
工资等级表salgrade三个字段: grade、losal、hisal
员工表emp八个字段:empno、 ename、job、 mgr 、hiredate、sal、comm、deptno
1、> < = >= <= <>(!=)的使用
select * from emp where sal >3000;
select * from emp where sal<>5000;
select * from emp where sal=5000; 执行之后就能显示在表中
格式:select * from xxx(表) where yyy(字段)符号(> < = >= <= <>(!=))

2、模糊查询like的使用
select * from emp where ename like ‘%S%’; (S不知道在什么位置)
select * from emp where ename like ‘S%’; (以S开头)
select * from emp where ename like ‘%S’; (以S结尾)
select * from emp where ename like ‘_o%’;(o为第二个字符)
格式:
1、zzz不知是第几个字符:select * from xxx(表) where yyy(字段) like ‘%zzz%’;
2、以zzz字符开头:select * from xxx(表) where yyy(字段) like ‘zzz%’;
3、以zzz字符结尾:select * from xxx(表) where yyy(字段) like ‘%zzz’;
4、zzz为第二个字符:select * from xxx(表) where yyy(字段) like ‘_zzz%’;
_是占位符,占一个字节
3、排序
select * from emp order by sal;
select * from emp order by sal asc;
select * from emp order by sal desc;
select * from emp order by deptno asc,sal desc;
格式:
1、默认升序:select * from xxx(表) order by yyy(字段);
2、升序:select * from xxx(表) order by yyy(字段)asc;
3、降序:select * from xxx(表) order by yyy(字段)desc;
4、按照某字段排序某字段:select * from xxx(表) order by yyy1(字段1)asc,yyy2(字段2) desc;
字段1和字段2要根据实际情况设计是升序还是降序
4、限制多少行
select * from emp limit 2;
select * from emp order by deptno asc,sal desc limit 2;
格式:
select * from xxx(表) limit ttt(行数);
select * from xxx(表) order by yyy1(字段1)asc,yyy2(字段2) desc limit ttt(行数);
5、聚合
聚合函数有:sum、count、avg、max、min等
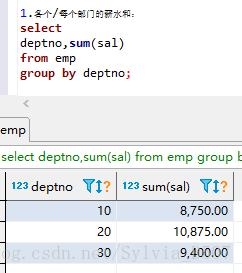
(1)各个/每个部门的薪水和
select
deptno,sum(sal)
from emp
group by deptno;
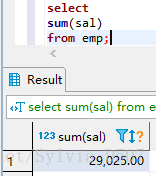
依葫芦画瓢:总的薪水和如上图
格式:
select
字段1,sum(字段2)
from xxx(表)
group by 字段1;
group by 后面跟着的字段必须与select 之后聚合函数之前的字段一致,如果是多个字段,可以不按顺序!
如:
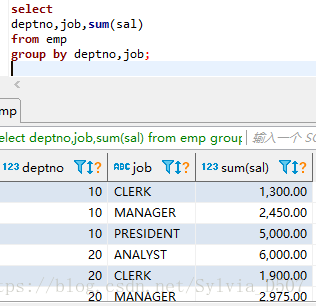
各个部门各个岗位的薪水和:
select
deptno,job,sum(sal)
from emp
group by deptno,job;
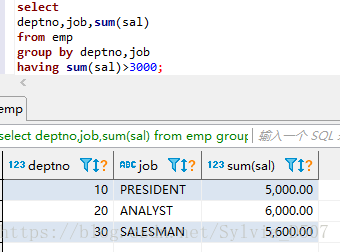
(2)各个部门各个岗位的薪水和>3000
select
deptno,job,sum(sal)
from emp
group by deptno,job
having sum(sal)>3000; (having 后面一般跟聚合函数,形成筛选条件,超好用)
(3)数量,最大值等
select count(*) from xxx(表)
select max(字段) from xxx(表)
(4)别名 as
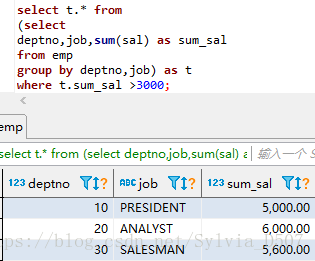
(5)子表:先将各个部门各个岗位的薪水和作为一个子表
select t.* from
(select deptno,job,sum(sal) as sum_sal
from emp
group by deptno,job) as t
where t.sum_sal >3000;
6、组合
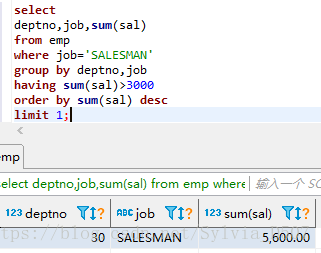
各个部门销售薪水和>3000并降序排序显示一行:
select
deptno,job,sum(sal)
from emp
where job=‘SALESMAN’
group by deptno,job
having sum(sal)>3000
order by sum(sal) desc
limit 1;
格式:
select
字段1,字段2,sum(字段3)
from xxx
where 字段2=‘yyy’
group by 字段1,字段2
having sum(字段3) 筛选条件
order by sum(字段 3) desc
limit 行数;
7、union合并表
1、去重复合并
select * from table1
union
select * from table2
2、不去重复合并
select * from table1
union all
select * from table2
3、指定字段合并
select 字段1,字段2 from table1
union all
select 字段3,字段4 from table2 (对应字段类型并不一致,也是可以的)
注意:
a. 名称是由第一张表决定的
b. 生产上不用*去合并所有的字段,要指定字段,在数据量比较大,合并字段比较少的情况下
c. 对应字段类型保持一致,这句话不一定正确

