集合的两大接口Collection接口和Iterator接口
在集合框架中,集合(Collection)接口位于Set接口和List接口的最顶层,是Set接口和List接口的父接口。
1.List接口
(1)
① List中的元素是有顺序的。
② List通常允许重复元素。
③ List的实现类通常支持null元素。
④ 可以通过索引访问List对象容器中的元素。
list.set(1, “胡帅”);// 修改元素
System.out.println(ll.get(3)); ;// 打印元素
int size = list.size();// 元素个数
(2)ArrayList
ArrayList在概念上与数组类似,表示一组编入索引的元素,区别之处在于ArrayList没有预先确定的大小,其长度可按需增大。
泛型:泛型,就是允许在定义类、接口时指定类型形式参数,这个类型形式参数将在声明变量、创建对象时确定(即传入的实际参数)。
Iterator接口是一种用于遍历集合的接口。遍历,是指从集合中取出每一个元素的过程. 迭代器
Iterator it = list.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
it.remove();// 如果需要从集合中,移除元素才使用该方法
}
(3)LinkedList
① LinkedList是实现了双向链表功能的列表,它将列表中的每个对象放在独立的空间中,而且每个空间中还保存有上一个和下一个链接的索引
② LinkedList不支持快速随机访问,如果要访问LinkedList中第n个元素,必须从头开始查找,然后跳过前面的n-1个元素。所以访问LinkedList元素时,性能会比较低下。
(4)Voctor
ava.util.vector提供了向量类(vector)以实现类似动态数组的功能
ArrayList ,LinkedList ,Vector 三者均是List实现类,都可以代表有序,重复集合
但是:ArrayList底层是基于数组结构来实现的,查询数据较快,操作数据较慢 LinkedList
底层是基于链表结构来实现的,操作数据上较快,查询数据较慢
Vector 同ArrayList一样,也是基于数组结构来实现的,但是区别在于它线程安全(加了锁)
2.Set接口
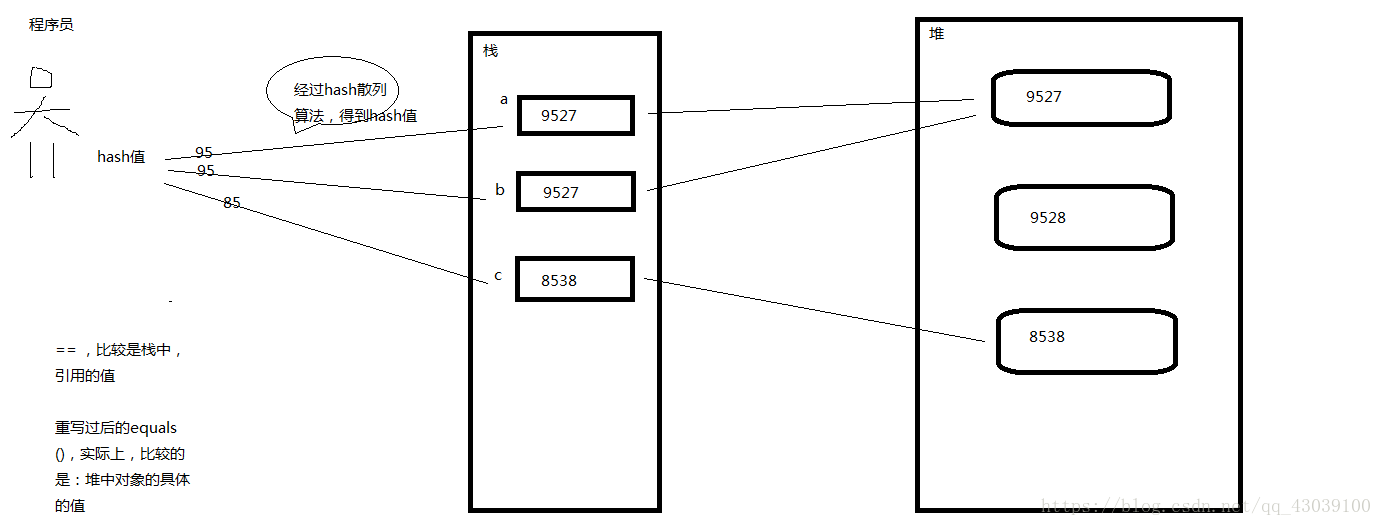
(1)Set类型容器中不能包含重复元素。当加入一个元素到容器中时候,要比较元素的内容是否存在重复的,所以加入Set类型对象容器的对象必须重写equals()方法。
1.HashSet
HashSet类是基于哈希算法的Set接口实现,它主要有如下几个特点:
(1)当遍历HashSet时,其中的元素是没有顺序的,因为元素没有顺序,所以不能基于索引访问Set中的元素。
(2)HashSet中不允许出现重复元素。这里的重复元素是指有相同的哈希码,并且用equals()方法进行比较时,返回true的两个对象。
(3)允许包含null元素。
2.TreeSet
TreeSet类不仅实现类Set接口,还实现了SortedSet接口,从而保证集合中的对象按照一定的顺序排序。当向TreeSet集合中添加一个对象时,会把它插入到有序的对象序列中。
TreeSet底层是TreeMap,但是TreeMap是采用二叉树的结构来存储数据,
在二叉树中,比较元素时,比树中元素小的,永远在下一代的左边
当然,比树中元素大的,永远在下一代的右边,相等的,就直接覆盖
Map接口
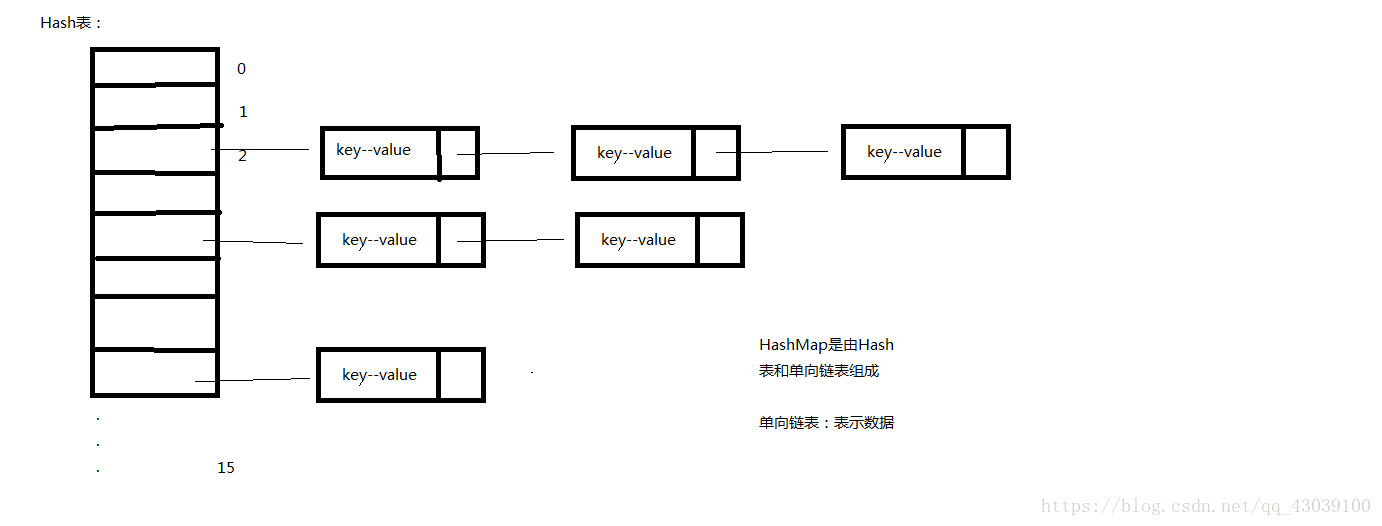
1.HashMap类
(1)HashMap类实现了Map接口,从而具有Map接口的所有方法
(2)HashMap是基于哈希算法的Map接口的实现。HashMap将它的键保存在哈希表中进行维护,键是唯一的
(3)HashMap使用哈希码通过键对其内容进行快速查找,但是HashMap中的元素是没有顺序的。如果要让Map中的元素按照一定的顺序排列,就要使用TreeMap类。
2.TreeMap类
返回Collections中最大元素(max)
(1)TreeMap类是基于红黑树算法的Map接口实现。TreeMap中键的存放方式与TreeSet相似,它将键存放在树中,键的顺序按照自然顺序或者自定义顺序两种方式排列。
Collections 和 Collection的区别
Collection 是List列表集合,和Set集合的父接口
Collections 是集合工具类
Collections.swap(list, 1, 2);//交换位置
Collections.rotate(list, 2);//根据指定长度 ,交换元素的位置
Collections.sort(list,new DogComparator());//排列
Collections.reverse(list);//反转排列
public int compareTo(Object o) {
/ TODO Auto-generated method stub
Student tmp=(Student) o;
return this.age-tmp.age;
}
进行逐一比较,此时返回为一的话排在后面
进行逐一比较,此时返回为-1的话排在前面
进行逐一比较,此时返回为0的话比较其他元素
//Ctrl + Shift + S 选择生成hashcode()和equals()
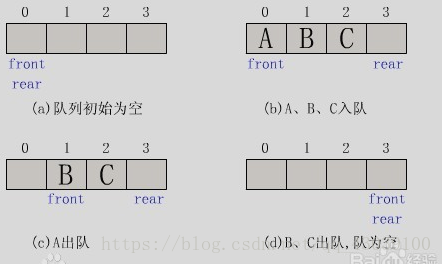
队列是一种数据结构.它有两个基本操作:在队列尾部加人一个元素,和从队列头部移除一个元素就是说,队列以一种先进先出的方式管理数据,如果你试图向一个 已经满了的阻塞队列中添加一个元素或者是从一个空的阻塞队列中移除一个元索,将导致线程阻塞.在多线程进行合作时,阻塞队列是很有用的工具。工作者线程可 以定期地把中间结果存到阻塞队列中而其他工作者线线程把中间结果取出并在将来修改它们。队列会自动平衡负载。如果第一个线程集运行得比第二个慢,则第二个 线程集在等待结果时就会阻塞。如果第一个线程集运行得快,那么它将等待第二个线程集赶上来。
②队列中没有元素时,称为空队列。
③建立顺序队列结构必须为其静态分配或动态申请一片连续的存储空间,并设置两个指针进行管理。一个是队头指针front,它指向队头元素;另一个是队尾指针rear,它指向下一个入队元素的存储位置。
④队列采用的FIFO(first in first out),新元素(等待进入队列的元素)总是被插入到链表的尾部,而读取的时候总是从链表的头部开始读取。每次读取一个元素,释放一个元素。所谓的动态创建,动态释放。因而也不存在溢出等问题。由于链表由结构体间接而成,遍历也方便。(先进先出)
add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回false
poll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞